MQ 如何保证数据一致性?
前言
上个月,我们有个电商系统出了个灵异事件:用户支付成功了,但订单状态死活不改成“已发货”。
折腾了半天才定位到问题:订单服务的MQ消息,像人间蒸发一样消失了。
这个Bug让我明白:(MQ)消息队列的数据一致性设计,绝对能排进分布式系统三大噩梦之一!
今天这篇文章跟大家一起聊聊,MQ如何保证数据一致性?希望对你会有所帮助。
1 数据一致性问题的原因
这些年在Kafka、RabbitMQ、RocketMQ踩过的坑,总结成四类致命原因:
- 生产者悲剧:消息成功进Broker,却没写入磁盘就断电。
- 消费者悲剧:消息消费成功,但业务执行失败。
- 轮盘赌局:网络抖动导致消息重复投递。
- 数据孤岛:数据库和消息状态割裂(下完单没发券)
这些情况,都会导致MQ产生数据不一致的问题。
那么,如何解决这些问题呢?
2 消息不丢的方案
我们首先需要解决消息丢失的问题。
2.1 事务消息的两阶段提交
以RocketMQ的事务消息为例,工作原理就像双11的预售定金伪代码如下:
// 发送事务消息核心代码
TransactionMQProducer producer = new TransactionMQProducer("group");
producer.setTransactionListener(new TransactionListener() {
// 执行本地事务(比如扣库存)
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
return doBiz() ? LocalTransactionState.COMMIT : LocalTransactionState.ROLLBACK;
}
// Broker回调检查本地事务状态
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
return checkDB(msg.getTransactionId()) ? COMMIT : ROLLBACK;
}
});
真实场景中,别忘了在checkLocalTransaction里做好妥协查询(查流水表或分布式事务日志)。
去年在物流系统救火,就遇到过事务超时的坑——本地事务成功了,但因网络问题没收到Commit,导致Broker不断回查。
2.2 持久化配置
RabbitMQ的坑都在配置表里:
| 配置项 | 例子 | 作用 |
|---|---|---|
| 队列持久化 | durable=true | 队列元数据不丢 |
| 消息持久化 | deliveryMode=2 | 消息存入磁盘 |
| Lazy Queue | x-queue-mode=lazy | 消息直接写盘不读取进内存 |
| Confirm机制 | publisher-confirm-type | 生产者确认消息投递成功 |
RabbitMQ本地存储+备份交换机双重保护代码如下:
channel.queueDeclare("order_queue", true, false, false,
new HashMap<String, Object>(){{
put("x-dead-letter-exchange", "dlx_exchange"); // 死信交换机
}});
去年双十一订单系统就靠这个组合拳硬刚流量峰值:主队列消息积压触发阈值时,自动转移消息到备份队列给应急服务处理。
2.3 副本配置
| 消息队列 | 保命绝招 |
|---|---|
| Kafka | acks=all + 副本数≥3 |
| RocketMQ | 同步刷盘 + 主从同步策略 |
| Pulsar | BookKeeper多副本存储 |
上周帮一个金融系统迁移到Kafka,为了数据安全启用了最高配置。
server.properties配置如下:
acks=all
min.insync.replicas=2
unclean.leader.election.enable=false
结果发现吞吐量只剩原来的三分之一,但客户说“钱比速度重要”——这一行哪有银弹,全是取舍。
不同的业务场景,情况不一样。
3 应对重复消费的方案
接下来,需要解决消息的重复消费问题。
3.1 唯一ID
订单系统的架构课代表代码:
// 雪花算法生成全局唯一ID
Snowflake snowflake = new Snowflake(datacenterId, machineId);
String bizId = "ORDER_" + snowflake.nextId();
// 查重逻辑(Redis原子操作)
String key = "msg:" + bizId;
if(redis.setnx(key, "1")) {
redis.expire(key, 72 * 3600);
processMsg();
}
先使用雪花算法生成全局唯一ID,然后使用Redis的setnx命令加分布式锁,来保证请求的唯一性。
某次促销活动因Redis集群抖动,导致重复扣款。
后来改用:本地布隆过滤器+分布式Redis 双校验,总算解决这个世纪难题。
3.2 幂等设计
针对不同业务场景的三种对策:
| 场景 | 代码示例 | 关键点 |
|---|---|---|
| 强一致性 | SELECT FOR UPDATE先查后更新 | 数据库行锁 |
| 最终一致性 | 版本号控制(类似CAS) | 乐观锁重试3次 |
| 补偿型事务 | 设计反向操作(如退款、库存回滚) | 操作日志必须落库 |
去年重构用户积分系统时,就靠着这个三板斧把错误率从0.1%降到了0.001%:
积分变更幂等示例如下:
public void addPoints(String userId, String orderId, Long points) {
if (pointLogDao.exists(orderId)) return;
User user = userDao.selectForUpdate(userId); // 悲观锁
user.setPoints(user.getPoints() + points);
userDao.update(user);
pointLogDao.insert(new PointLog(orderId)); // 幂等日志
}
这里使用了数据库行锁实现的幂等性。
3.3 死信队列
RabbitMQ的终极保命配置如下:
// 消费者设置手动ACK
channel.basicConsume(queue, false, deliverCallback, cancelCallback);
// 达到重试上限后进入死信队列
public void process(Message msg) {
try {
doBiz();
channel.basicAck(deliveryTag);
} catch(Exception e) {
if(retryCount < 3) {
channel.basicNack(deliveryTag, false, true);
} else {
channel.basicNack(deliveryTag, false, false); // 进入DLX
}
}
}
消费者端手动ACK消息。
在消费者端消费消息时,如果消费失败次数,达到重试上限后进入死信队列。
这个方案救了社交系统的推送服务——通过DLX收集全部异常消息,凌晨用补偿Job重跑。
4 系统架构设计
接下来,从系统架构设计的角度,聊聊MQ要如何保证数据一致性?
4.1 生产者端
对于实效性要求不太高的业务场景,可以使用:本地事务表+定时任务扫描的补偿方案。
流程图如下:
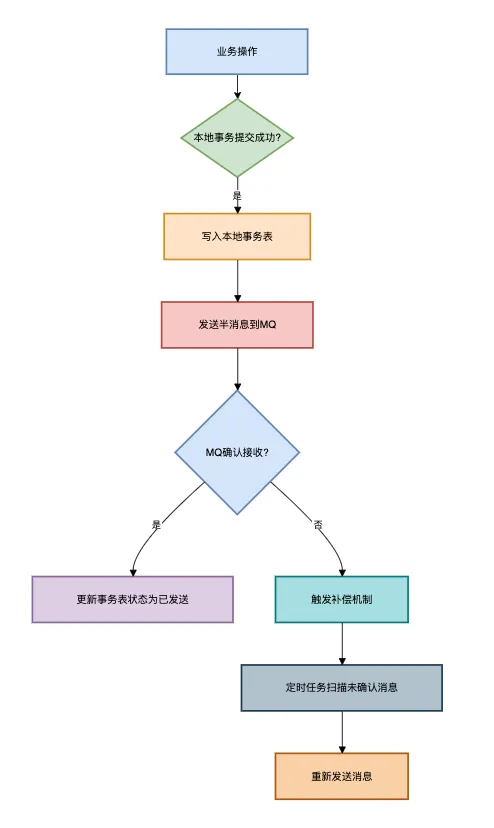
4.2 消费者端
消费者端为了防止消息风暴,要设置合理的并发消费线程数。
流程图如下:

4.3 终极方案
对于实时性要求比较高的业务场景,可以使用 事务消息+本地事件表 的黄金组合.
流程图如下:
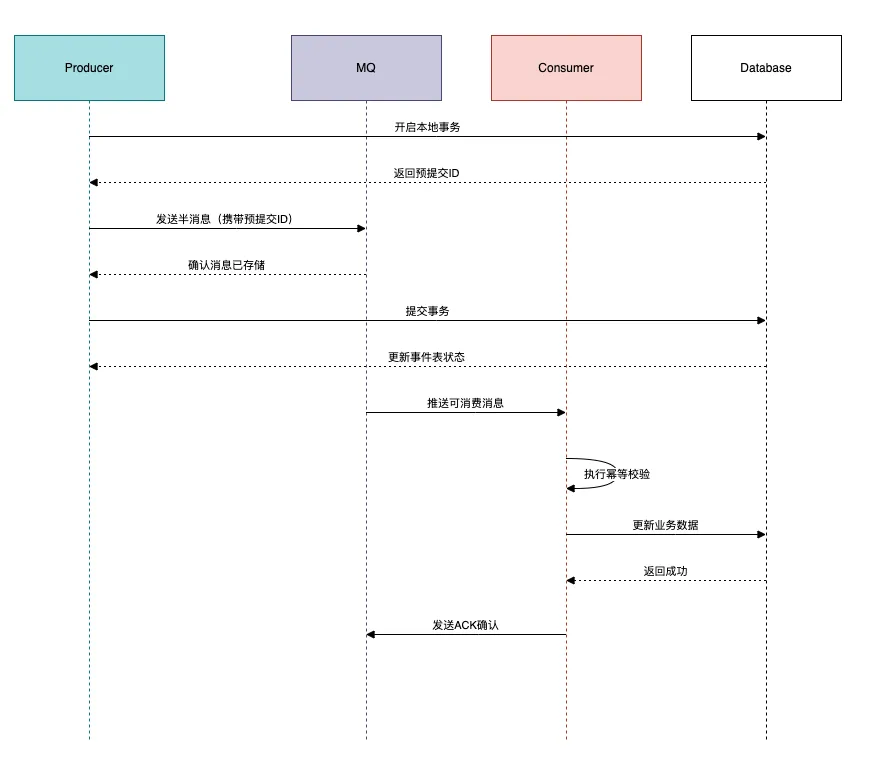
5 血泪经验十条
- 消息必加唯一业务ID(别用MQ自带的ID)
- 消费逻辑一定要幂等(重复消费是必然事件)
- 数据库事务和消息发送必须二选一(或者用事务消息)
- 消费者线程数不要超过分区数*2(Kafka的教训)
- 死信队列必须加监控报警(别等客服找你)
- 测试环境一定要模拟网络抖动(chaos engineering)
- 消息体要兼容版本号(血的教训警告)
- 不要用消息队列做业务主流程(它只配当辅助)
- 消费者offset定时存库(防止重平衡丢消息)
- 业务指标和MQ监控要联动(比如订单量和消息量的波动要同步)
总结
(MQ)消息队列像金融系统的SWIFT结算网络,看似简单实则处处杀机。
真正的高手不仅要会调参,更要设计出能兼容可靠性与性能的架构。
记住,分布式系统的数据一致性不是银弹,而是通过层层防御达成的动态平衡。
就像当年我在做资金结算系统时,老板说的那句震耳发聩的话:“宁可慢十秒,不可错一分”。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
MQ 如何保证数据一致性?的更多相关文章
- MySQL 是怎么保证数据一致性的(转载)
在<写数据库同时发mq消息事务一致性的一种解决方案>一文的方案中把分布式事务巧妙转成了数据库事务.我们都知道关系型数据库事务能保证数据一致性,那数据库到底是怎么设计事务这一特性的呢? 一. ...
- ZooKeeper 如何保证数据一致性?
在分布式场景中,ZooKeeper 的应用非常广泛,比如数据发布和订阅.命名服务.配置中心.注册中心.分布式锁等. 在分布式场景中,ZooKeeper 的应用非常广泛,比如数据发布和订阅.命名服务.配 ...
- 【面试普通人VS高手系列】Redis和Mysql如何保证数据一致性
今天分享一道一线互联网公司高频面试题. "Redis和Mysql如何保证数据一致性". 这个问题难倒了不少工作5年以上的程序员,难的不是问题本身,而是解决这个问题的思维模式. 下面 ...
- Dynamo分布式系统——「RWN」协议解决多备份数据如何读写来保证数据一致性,而「向量时钟」来保证当读取到多个备份数据的时候,如何判断哪些数据是最新的这种情况
转自:http://blog.jqian.net/post/dynamo.html Dynamo是Amazon开发的一款高可用的分布式KV系统,已经在Amazon商店的后端存储有很成熟的应用.它的特点 ...
- 使用MQ来保证分布式事务的最终一致性
前言 之前我们讨论了如何拆分一个订单下单的一个服务(https://www.cnblogs.com/linkstar/p/9610268.html) 从单体到微服务的拆分,当时我们只是对原来的整个服务 ...
- ZK集群如何保证数据一致性源码阅读
什么是数据一致性? 只有当服务端的ZK存在多台时,才会出现数据一致性的问题, 服务端存在多台服务器,他们被划分成了不同的角色,只有一台Leader,多台Follower和多台Observer, 他们中 ...
- 消息队列MQ如何保证高可用性?
保证MQ的高可用性,主要是解决MQ的缺点--系统复杂性变高--带来的问题 主要说一下 rabbitMQ 和 kafka 的高可用性 一.rabbitMQ的高可用性 rabbitMQ是基于主从做 ...
- Rabbit MQ 怎么保证可靠性、幂等性、消费顺序?
RabbitMQ如何保证消息的可靠性 RabbitMQ消息丢失的三种情况 生产者弄丢消息时的解决方法 方法一:生产者在发送数据之前开启RabbitMQ的事务(采用该种方法由于事务机制,会导致吞吐量下降 ...
- MySQL 在高并发下的 订单撮合 系统使用 共享锁 与 排他锁 保证数据一致性
作者:林冠宏 / 指尖下的幽灵 掘金:https://juejin.im/user/587f0dfe128fe100570ce2d8 博客:http://www.cnblogs.com/linguan ...
- oracle如何保证数据一致性和避免脏读
oracle通过undo保证一致性读和不发生脏读 1.不发生脏读2.一致性读3. 事务槽(ITL)小解 1.不发生脏读 例如:用户A对表更新了,没有提交,用户B对进行查询,没有提交的更新不能出现在 ...
随机推荐
- spark (二) spark wordCount示例
目录 实现思路 实现1: scala 基本集合操作方式获取结果 实现2: scala map reduce方式获取结果 实现3: spark 提供的map reduce方式获取结果 FAQ: 实现思路 ...
- echo输出
linux中不免经常使用echo进行输出,或输出到屏幕,或输出到文件.但是使用的时候会发现,在想要输出一些需要转义的字符时,例如\t等,它却原样不动的输出了. 使用man命令查看echo的帮助文档,会 ...
- Mysql身份认证过程
背景 最近有一些hersql的用户希望能支持mysql的caching_sha2_password认证方式,caching_sha2_password与常用的mysql_native_password ...
- 基于wvp-GB28181-pro 与 ZLMediaKit 的国标服务器
官方教程 wvp-GB28181-pro 与 ZLMediaKit 的联调手册 wvp-GB28181-pro wiki ZLMediaKit 基于C++11的高性能运营级流媒体服务框架 地址:Git ...
- Java并发包常用类用法及原理
com.java.util.concurrent包是java5时添加的,专门处理多线程提供的工具类 一.Atomic 二.Lock 三.BlockingQueue 四.BlockDeque 五.Con ...
- 隐私集合求交(PSI)-两方
在知乎上看到大佬写的关于论文:Efficient Batched Oblivious PRF with Applications to Private Set Intersection的讲解,循序渐进 ...
- Qemu-KVM基本工作原理介绍
本文分享自天翼云开发者社区<Qemu-KVM基本工作原理介绍>,作者:郑****文 1.KVM与Qemu关系 Qemu本身并不是KVM的一部分,而是一整套完整的虚拟化解决方案,它是纯软件实 ...
- 更快更省更好用!天翼云云原生一体机iStack打通物云最后一公里!
近年来,随着企业数字化转型的深入,从传统 IT 架构向云原生架构转型,已经成为企业谋求更高质量发展的必由之路.然而,云原生技术复杂度高,运维成本高,且技术工具间的集成度不足.打破云原生技术应用门槛,以 ...
- 你知道PCB走线可以过多大的瞬态电流吗?
相信很多同学在PCB Layout设计过程中,都有过这样的疑问:网口要做8KV浪涌防护,PCB走线应该走多宽呢? 有经验的硬件工程师可能此时就会说了,那还不简单,表层走线按照1mm/A,内层走线按照2 ...
- Q:LISTAGG()函数用法笔记(oracle)
.LISTAGG()函数作为普通函数使用时就是查询出来的结果列转为行 ☆LISTAGG 函数既是分析函数,也是聚合函数有两种用法:1.分析函数,如: row_number().rank().dense ...