如何通过 MCP 将你的 Supabase 数据库连接到 Cursor

Cursor + MCP + Supabase. 图片来自作者
在过去几周里,MCP(Model Context Protocol,模型上下文协议)在许多 AI 相关的在线社区和论坛里大火。开发者和技术人员都在热议这个东西,但说实话,包括我自己在内,很多人都对 MCP 究竟是什么、它能做什么以及为什么我们应该关心它感到困惑。
为了弄清楚这个问题,我花了一些时间研究,并整理了一个真实案例,来展示 MCP 在构建 AI 工具驱动的 Web 应用时到底有多大影响力。具体来说,我会演示 MCP 如何让你轻松地将 Supabase 数据库直接连接到 Cursor IDE。
设置完成后,Cursor 代理就能自动访问你的 Supabase 数据库。这意味着你每次与 AI 助手交互时,不需要手动提供数据库上下文。这对使用 Cursor 和 Supabase 构建全栈 Web 应用的开发者来说,简直是个巨大的优势。
在正式进入教程之前,先让我简单介绍一下 MCP 是什么。
什么是 MCP?
模型上下文协议(MCP)本质上是一种标准方式,允许 AI 代理安全地访问外部数据源或上下文,而不需要每次都编写复杂的自定义代码。可以把 MCP 想象成一个万能适配器:你只需要设置一次,它就能让 AI 驱动的工具连接到几乎任何外部数据库或资源。
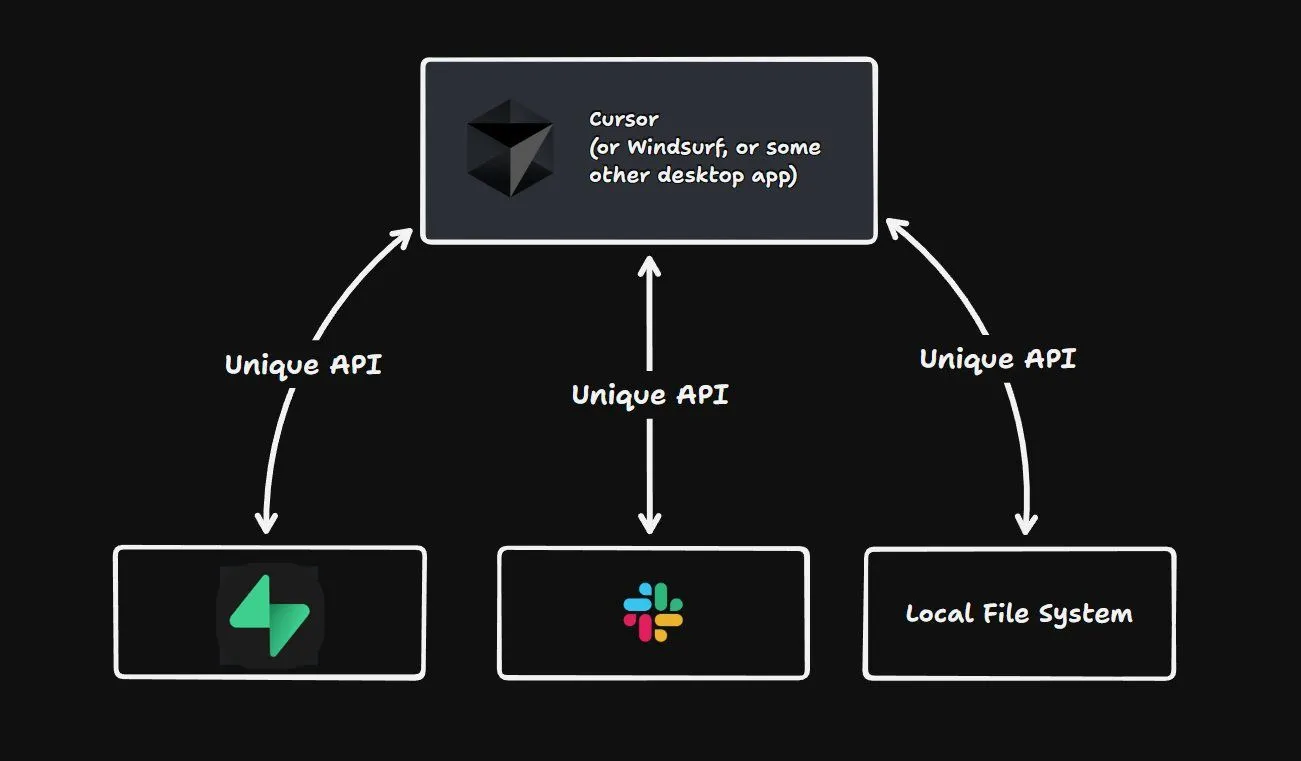
如果你曾尝试让 LLM(大语言模型)在现实世界中发挥作用,你可能会很快遇到一个大问题:几乎所有有用的服务,比如 Slack、GitHub,甚至是本地文件系统,都有自己独特的 API。这意味着你需要编写大量的自定义代码,让 LLM 单独适配每个 API。想要添加一个新工具?又得写一堆额外的代码。这很快就会变成一场噩梦。
[MCP 结构示意图](Image from Matt Pocock)
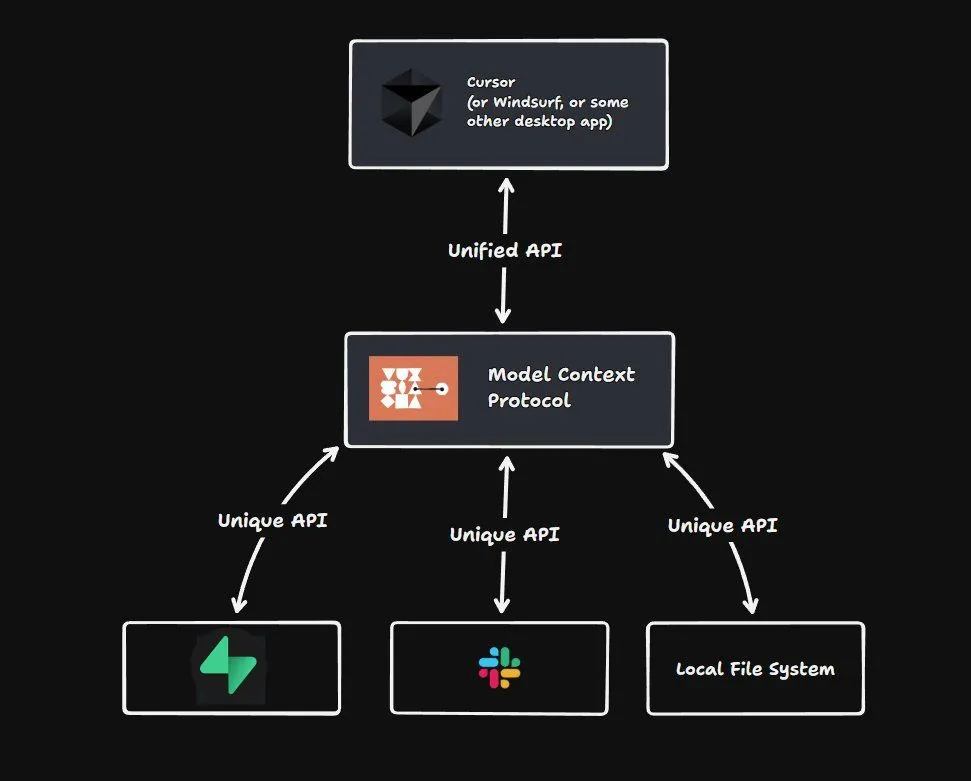
MCP 作为 LLM 和所有这些 API 之间的一个中间层。与其为每个工具单独编写自定义代码,MCP 允许你定义一组 LLM 可以调用的“工具”。
[MCP 运行示意图](Image from Matt Pocock)
你可以选择将 MCP 服务器远程托管,或者在本地运行。无论哪种方式,你的 LLM 只需要直接连接到 MCP 服务器,并调用它提供的工具即可。MCP 服务器会处理 API 调用,让交互变得无缝衔接。
现在,让我们从理论转向实践,尝试使用 MCP 将你的 Supabase 数据库连接到 Cursor。
如何在 Cursor 添加 MCP 服务器
- 进入 Cursor 设置页面,在 MCP 选项卡下,点击“Add new MCP Server”(添加新 MCP 服务器)按钮。

[Cursor MCP 服务器添加界面](Screenshot of Cursor IDE using MCP. Image by author)
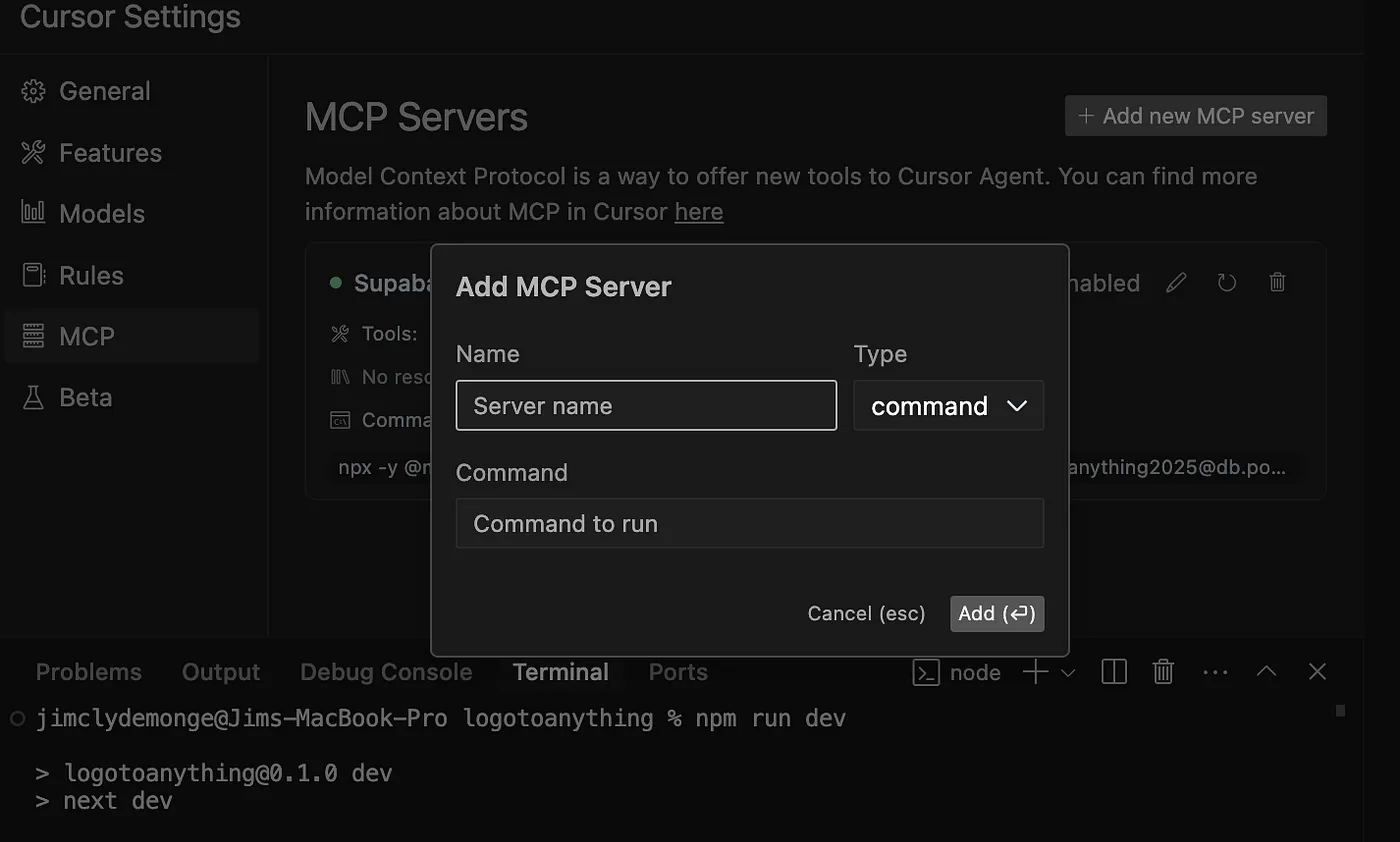
- 给你的 MCP 服务器起个名字,比如“Supabase database”,然后将类型(Type)设置为 command。
[Cursor MCP 服务器命名](Screenshot of Cursor IDE using MCP. Image by author)
- 在“Command”栏粘贴以下 CLI 命令:
npx -y @modelcontextprotocol/server-postgres
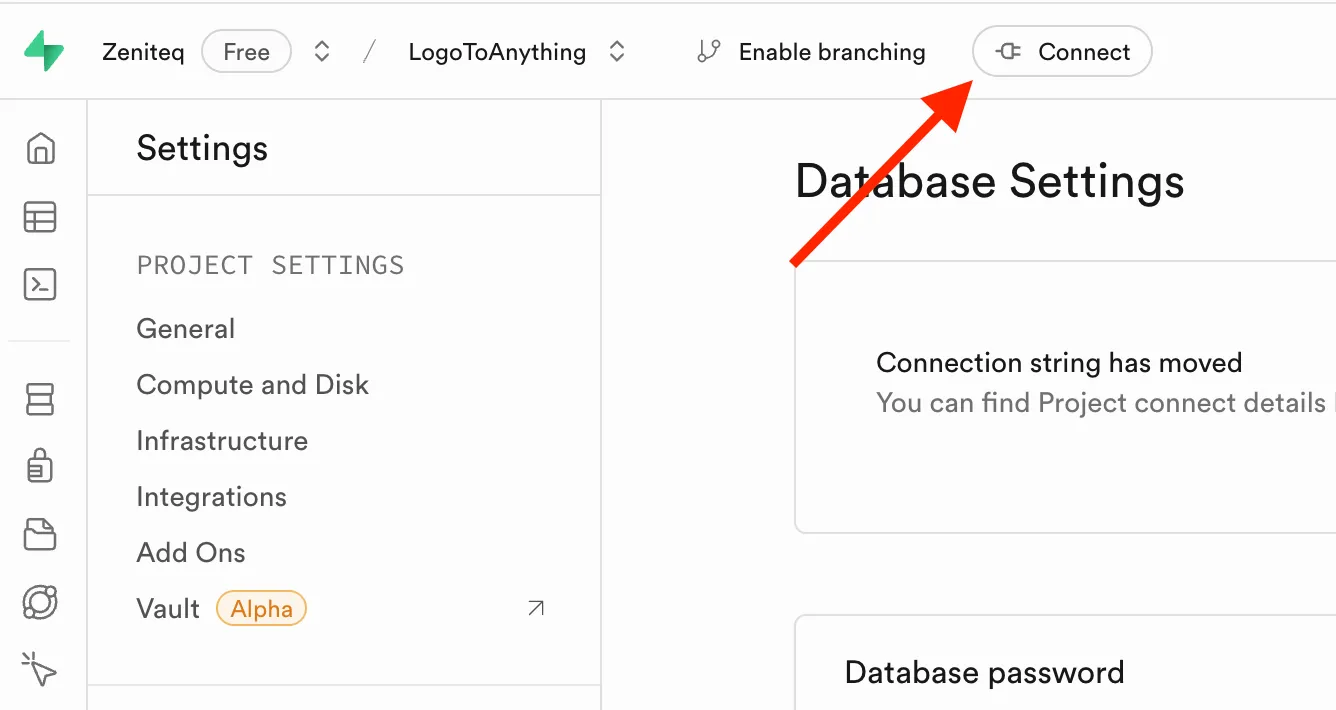
你可以在 Supabase 项目中获取 connection-string,方法是点击控制面板顶部的“Connect”按钮。
[Supabase 项目设置](Image of Supabase project settings. Image by author)
- 在“Connection String”选项卡下,你会看到“Direct Connection URI”。复制它并粘贴到 MCP 命令的“Connection String”部分。
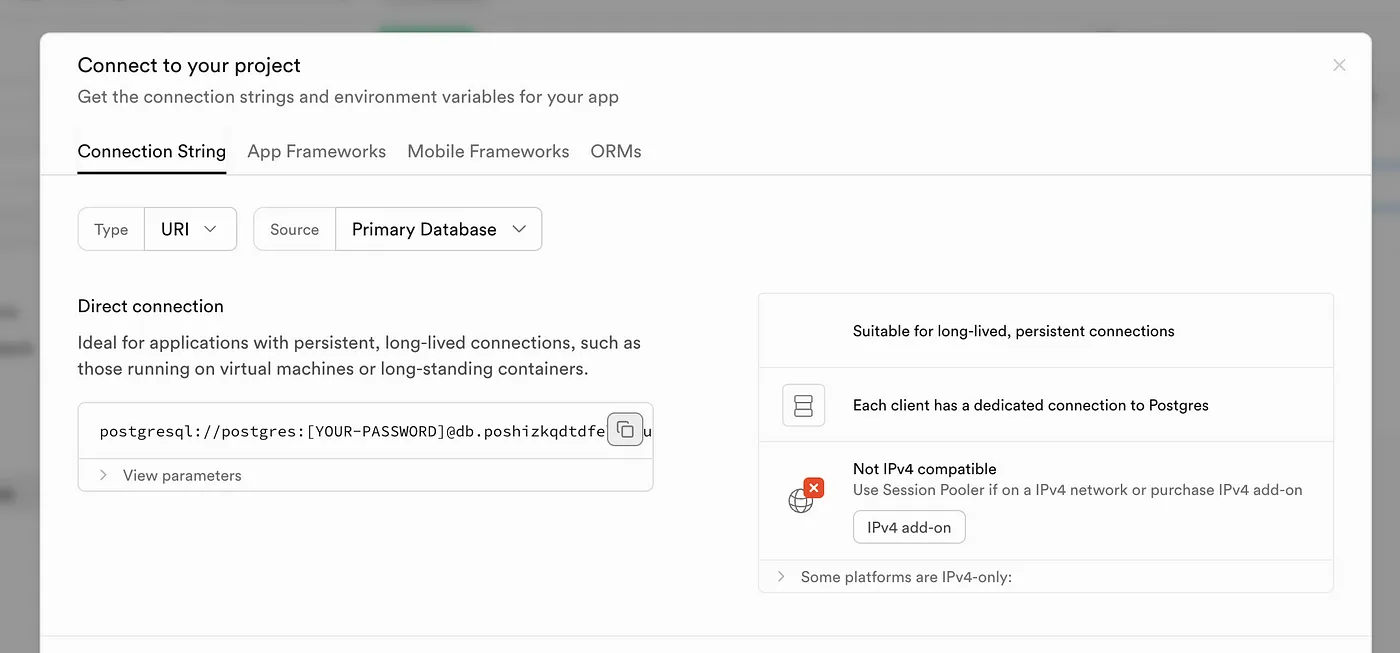
[Supabase 连接 URI](Screenshot of Supabase connection string. Image by author)
注意:URI 里有一个 YOUR-PASSWORD 部分,作为参数。你需要把它替换为你的实际数据库密码。你可以在 Project Settings > Configuration > Database > Database password 里找到数据库密码。
- 你的 MCP 服务器参数应该像这样:
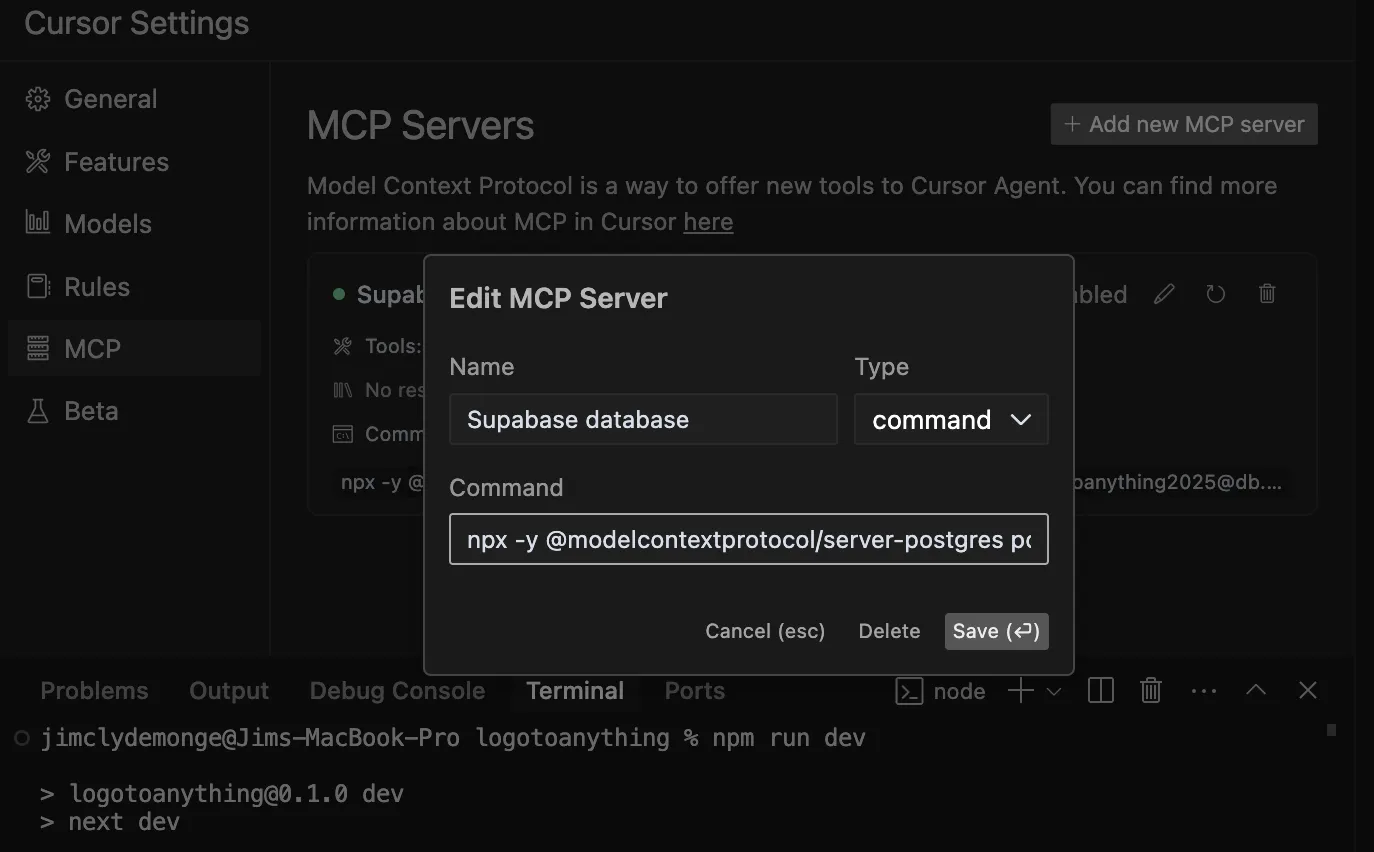
[Cursor MCP 服务器参数](Screenshot of Cursor IDE using MCP. Image by author)
- 确认无误后,点击“Add”按钮。你会在 MCP 服务器旁边看到一个状态指示器,一旦它变成绿色,就说明一切正常!
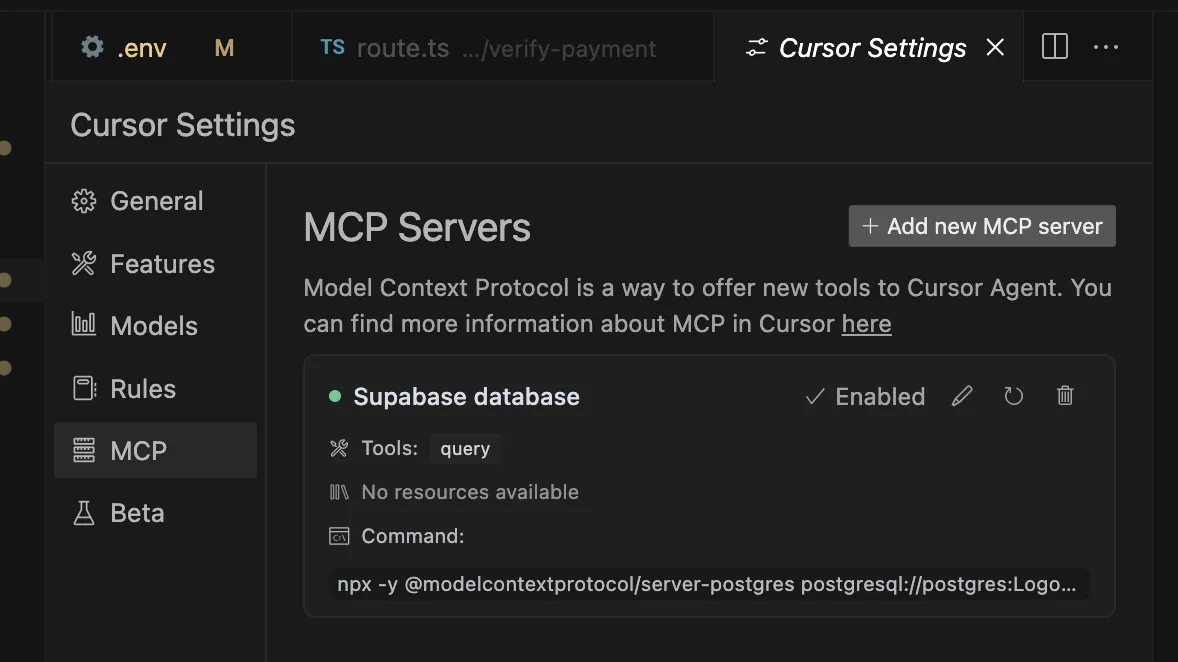
[Cursor MCP 服务器状态指示](Screenshot of Cursor IDE using MCP. Image by author)
MCP 连接故障排除
如果连接没有立即成功,可以检查以下常见问题:
- MCP 服务器未激活?
o 检查参数,确保连接字符串(connection string)里 没有 <> 标签,密码 也没有 [] 标签。
- 还是不行?
o 你可能需要手动创建一个 mcp.json 文件,放在本地系统 .cursor 文件夹下。

[mcp.json 文件示例](Image by author)
mcp.json 文件的内容如下:
{
"mcpServers": {
"supabase": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-postgres", ""]
}
}
}
确保用正确的连接字符串替换 。完美!现在我们可以测试 MCP 服务器了。
测试 Supabase MCP 服务器
要验证我们的 Supabase MCP 服务器是否正常运行,打开一个新的 Chat Agent,并运行以下提示:
Prompt(提示):
tell me what tables have in my Supabase database
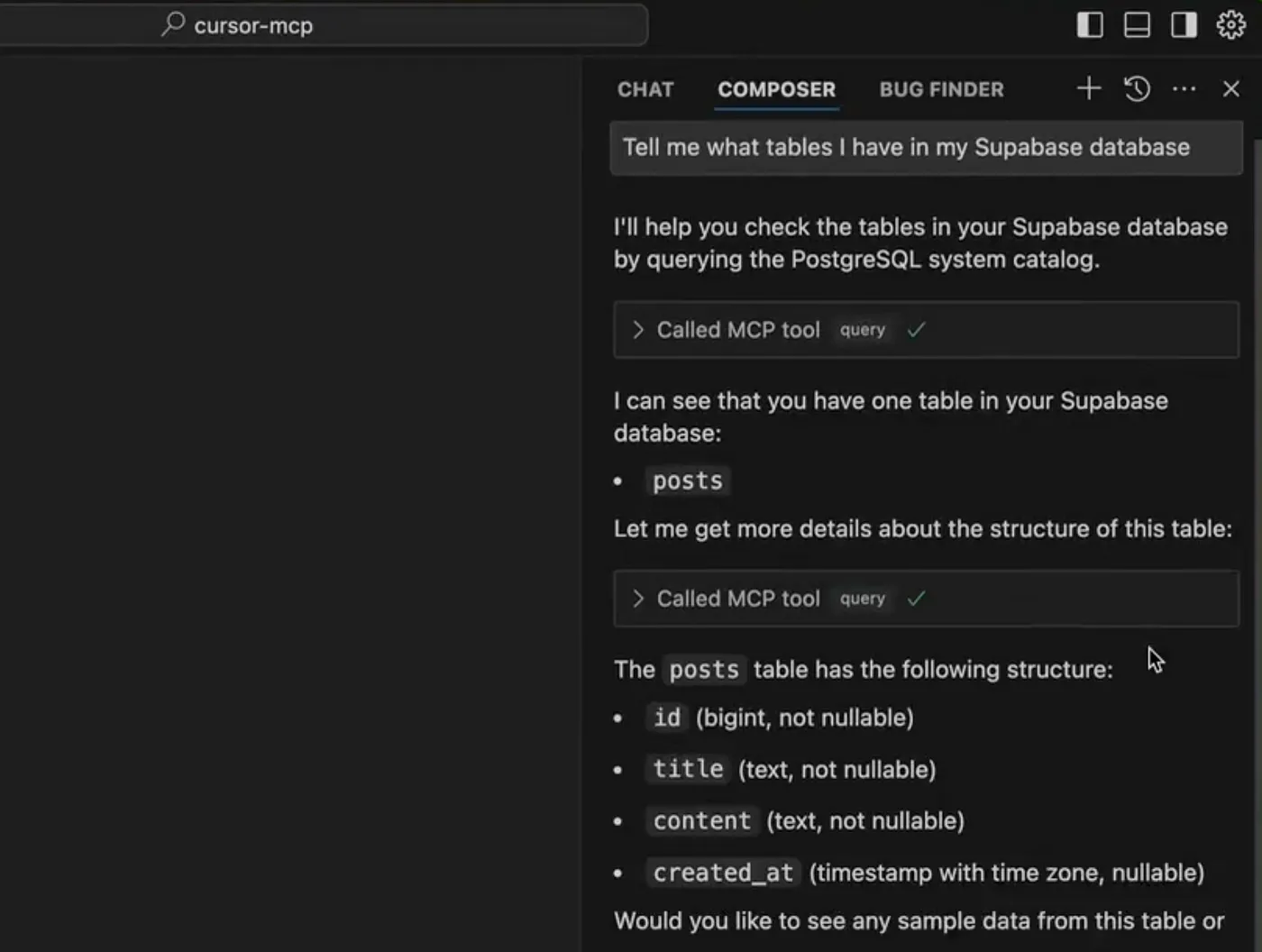

如果 MCP 服务器正常工作,Cursor 的 AI 代理就会从 Supabase 数据库中提取并显示表的列表。是不是很酷?
为什么 MCP 很重要?
MCP 受到关注的原因是,它简化了数据库(比如 Supabase)和 AI 开发环境(比如 Cursor)之间的集成。如果没有 MCP,每次你和 AI 代理交互时,都必须手动输入数据库上下文。
最近,我开发了我的第一个 Web 应用 LogoToAnything,在这个过程中,我用 MCP 让 Supabase 数据库连接到了 Cursor IDE。相信我,这省去了很多时间、算力消耗(token)和不必要的麻烦。
有了 MCP,AI 助手始终可以访问数据库上下文,这意味着:
更快的响应速度
更轻松的调试体验
更快速的开发周期
这也是为什么开发者们如此兴奋 —— MCP 让复杂的集成变得简单,让你可以专注于 构建,而不是 配置。
所以,赶快试试吧,享受更流畅、更智能的编码体验!
如何通过 MCP 将你的 Supabase 数据库连接到 Cursor的更多相关文章
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集及MySQL数据库操作
转载请注明出处 利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集 1.任务 采集豆瓣电影名称.链接.评分.导演.演员.年份.国家.评论人数.简评等信息 将以上数据存入MySQL数 ...
- 重拾Python(5):数据读取
本文主要对Python如何读取数据进行总结梳理,涵盖从文本文件,尤其是excel文件(用于离线数据探索分析),以及结构化数据库(以Mysql为例)中读取数据等内容. 约定: import numpy ...
- python导出zabbix数据并发邮件脚本
Zabbix没有报表导出的功能,于是通过编写脚本导出zabbix数据并发邮件.效果如下: 下面是脚本,可根据自己的具体情况修改: #!/usr/bin/python #coding:utf-8 imp ...
- python连接Greenplum数据库
配置greenplum客户端认证 配置pg_hba.conf cd /home/gpadmin/gpdbdata/master/gpseg- vim pg_hba.conf 增加 host all g ...
- 14.python与数据库之mysql:pymysql、sqlalchemy
相关内容: 使用pymysql直接操作mysql 创建表 查看表 修改表 删除表 插入数据 查看数据 修改数据 删除数据 使用sqlmary操作mysql 创建表 查看表 修改表 删除表 插入数据 查 ...
- python sqlite3 数据库操作
python sqlite3 数据库操作 SQLite3是python的内置模块,是一款非常小巧的嵌入式开源数据库软件. 1. 导入Python SQLite数据库模块 import sqlite3 ...
- MySQL自带功能介绍
前言: 数据库相关的操作 1.SQL语句 *****(MySql(一)已经介绍): 2.利用mysql内部提供的功能(视图.触发器.函数.存储过程: 一.视图: 把经常使用的查询结果,做成临时视图表, ...
- Python学习笔记六:数据库操作
一:Python操作数据库的流程 二:开发环境准备 1:开发工具PyCharm 2:Python操作mysql的工具:需要安装Python-Mysql Connector,网址:https://sou ...
- python模块分析之sqlite3数据库
SQLite作为一种应用广泛的文件式关系型数据库,python操作sqlite主要有两种方式,原生SQL语句和ORM映射工具. SQLAlchemy连接SQLITE SQLAlchemy是一款优秀的p ...
随机推荐
- Qt编写地图综合应用4-仪表盘
一.前言 仪表盘在很多汽车和物联网相关的系统中很常用,最直观的其实就是汽车仪表盘,这个以前主要是机械的仪表,现在逐步改成了智能的带屏带操作系统的仪表,这样美观性和拓展性功能性大大增强了,上了操作系统的 ...
- rysnc使用手册
rsync 是一个用于在本地和远程计算机之间同步文件和目录的命令行工具.它具有许多强大的功能,包括增量传输.压缩和保留权限等.以下是一些 rsync 的常用选项和用法示例: 基本用法 rsync [O ...
- 性能测试工具_nGrinder
1. ngrinder-controller-3.4.3.war 放置到tomcat的webapps目录下:2. 启动tomcat;3. 访问地址: http://localhost:8080/ngr ...
- Diary -「联合省选 2023」鸢尾
零 她们诞生于那样一段迷茫的时期,她们总是一个唱着虚幻的梦呓,一个哼着现实的词曲. 「平行的世界 / 另一个 / 我是怎样的」?如果那时的,虚幻的歌者没有妥协,现在的她会是怎样的人呢? 我 ...
- 使用Emgu.CV开发视频播放器简述
OpenCV是大名鼎鼎的视觉处理库,其对应的c#版本为Emgu.CV.本人采用Emgu.CV开发了一款视频播放软件,可对本地视频文件和rstp在线视频流播放,还具有对视频局部区域放大功能.虽然功能比较 ...
- c# 微软小冰-虚拟女友聊天
using Newtonsoft.Json; using System; using System.Collections.Generic; using System.IO; using System ...
- 史上最全Redis面试49题(含答案):哨兵+复制+事务+集群+持久化等
Redis主要有哪些功能? 1.哨兵(Sentinel)和复制(Replication) Redis服务器毫无征兆的罢工是个麻烦事,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制. ...
- 【Java 温故而知新系列】基础知识-05 面向对象
1.面向对象概述 面向对象(Object-Oriented,简称OO)是一种编程思想,核心思想是将现实世界中的事物抽象为程序中的"对象",通过对象之间的交互来解决问题. 对象 对象 ...
- C 2017笔试题
1.下面程序的输出结果是 int x=3; do { printf("%d\n",x-=2); }while(!(--x)); 输出:1 -2 解析:x初始值为3,第一次循环中运行 ...
- 推荐一款非常好用的在线 SSH 管理工具
前言 SSH工具在远程连接.文件传输.远程管理和增强安全性等方面发挥着重要作用,是我们开发人员和系统管理员不可或缺的工具.今天大姚给大家推荐一款非常好用的在线 SSH 管理工具:Xterminal. ...