svtools lmerge具体算法
svtools具有不同的子命令以实现不同的功能,其中一个就是lmerge。根据其帮助文档(merge LUMPY calls inside a single file from svtools lsort)可以看出,它是在lsort之后对一个vcf文件内的变异进行合并的,但只是知道它的功能而不知道它的原理,还是不能放心的使用它。所以就从它的代码看一下它是怎么操作的。
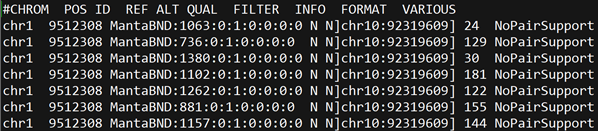
图1. lsort后的vcf文件,没行代表一个变异。
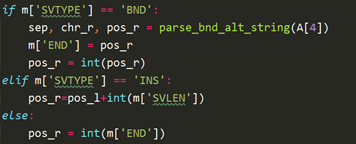
图2. 代码
由代码可知,它是对每个变异获得两个端点,一个就是vcf文件中的POS,把它作为第一个端点。然后获取第二个端点,根据变异类型不同,第二端点的获取方式也不同。如果变异类型是BND,则会解析vcf文件中REF位置的内容,获得其中的位置信息,作为第二端点。如果变异类型是INS的话,就把第一个端点加上SVLEN作为第二端点。其他情况获取vcf文件中END的信息作为第二端点。

图3. vcf文件展示
由于vcf文件每行内容都太长,所以上图换行展示。格外注意这里有CIPOS和CIEND两个信息。
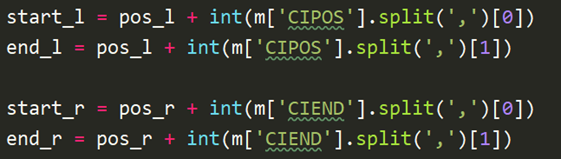
图4. 代码
由以上代码可以看出,在获取到两个端点之后,又分别根据CIPOS和CIEND的信息,把两个端点分别扩展成了两个区间。

图5. 把两个端点扩展为两个区间后的变异信息
可以看出,每个变异都含有两个区间,剩下的就是对这两个区间进行判断,两个变异记录是否为同一个变异。判断的标准:若这两个区间同时有重叠,则认为这两个变异记录是同一个变异(当然他们所对应的染色体也应该是一样的)。然后就可以对他们进行合并。

图6. vcf文件展示
vcf文件里有一个信息,PRPOS,这个信息是一系列数字,个数等于CIPOS[1] - CIPOS[0] + 1,表示第一端点处在每个位置的概率。另一个信息是PREND,也是一列数字,个数等位CIEND[1] - CIEND[0] + 1,表示第二端点处在各个位置的概率。
这里进行同一变异的合并,合并时,分别把第一区间和第二区间按照位置进行对齐,分别获得可以包含所有第一区间和第二区间的最大区间。例如一共有两个变异记录可能是同一变异,他们的第一区间分别为[start11=290 end11=390]和[start21=350 end21=580],则对齐后的区间为[start1=290 end2=580];若第二区间分别为[start12=680 end12=790]和[start22=780 end22=1000],则对齐后的区间为[start2=680 end2=1000]。按照区间的位置,也把PRPOS和PREDN进行对齐,前后空着的位置补0,然后把对齐后的PRPOS按位置进行相加,也把对齐后的PREND进行相加,就获得了与对齐区间长度一样的,PRPOS和PREND。然后找出PRPOS中数值最大的位置,然后对应到对齐后的第一区间,那就是变异合并后第一端点的位置。找到PREND中数值最大的位置,然后对应到对齐后的第二区间,那就是变异合并后第二端点的位置,这样就找到了变异合并后的两个端点的位置。
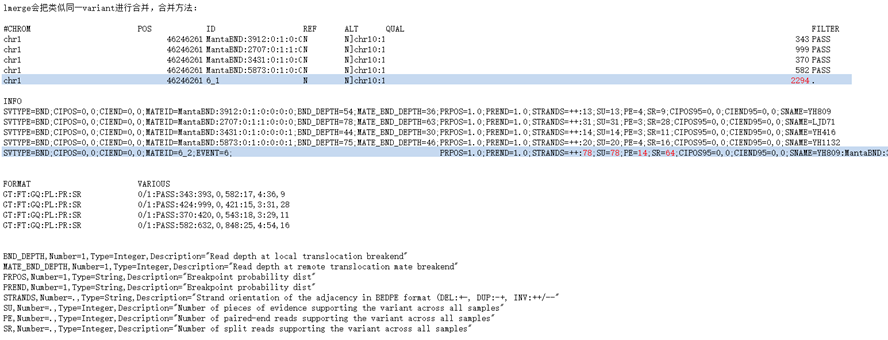
同时vcf文件里还会有QUAL、SU、PE、SR这些值,这些值的含义在vcf的header里都可以找到,他们的值合并的时候是直接相加的。这样就把代表同一变异的不同记录进行了合并,这就是svtools lmerge进行变异合并的原理。
svtools lmerge具体算法的更多相关文章
- B树——算法导论(25)
B树 1. 简介 在之前我们学习了红黑树,今天再学习一种树--B树.它与红黑树有许多类似的地方,比如都是平衡搜索树,但它们在功能和结构上却有较大的差别. 从功能上看,B树是为磁盘或其他存储设备设计的, ...
- 分布式系列文章——Paxos算法原理与推导
Paxos算法在分布式领域具有非常重要的地位.但是Paxos算法有两个比较明显的缺点:1.难以理解 2.工程实现更难. 网上有很多讲解Paxos算法的文章,但是质量参差不齐.看了很多关于Paxos的资 ...
- 【Machine Learning】KNN算法虹膜图片识别
K-近邻算法虹膜图片识别实战 作者:白宁超 2017年1月3日18:26:33 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 红黑树——算法导论(15)
1. 什么是红黑树 (1) 简介 上一篇我们介绍了基本动态集合操作时间复杂度均为O(h)的二叉搜索树.但遗憾的是,只有当二叉搜索树高度较低时,这些集合操作才会较快:即当树的高度较高(甚至一种极 ...
- 散列表(hash table)——算法导论(13)
1. 引言 许多应用都需要动态集合结构,它至少需要支持Insert,search和delete字典操作.散列表(hash table)是实现字典操作的一种有效的数据结构. 2. 直接寻址表 在介绍散列 ...
- 虚拟dom与diff算法 分析
好文集合: 深入浅出React(四):虚拟DOM Diff算法解析 全面理解虚拟DOM,实现虚拟DOM
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- 46张PPT讲述JVM体系结构、GC算法和调优
本PPT从JVM体系结构概述.GC算法.Hotspot内存管理.Hotspot垃圾回收器.调优和监控工具六大方面进行讲述.(内嵌iframe,建议使用电脑浏览) 好东西当然要分享,PPT已上传可供下载 ...
- 【C#代码实战】群蚁算法理论与实践全攻略——旅行商等路径优化问题的新方法
若干年前读研的时候,学院有一个教授,专门做群蚁算法的,很厉害,偶尔了解了一点点.感觉也是生物智能的一个体现,和遗传算法.神经网络有异曲同工之妙.只不过当时没有实际需求学习,所以没去研究.最近有一个这样 ...
随机推荐
- SpringBoot 设置编码UTF-8
第一种 通过过滤器来设置 @Configuration public class UtfConfig { @Bean public FilterRegistrationBean filterRegi ...
- springboot-实现excle文件导出的单元格相同内容合并
导出excle文件中的单元格有些需要合并如何操作 例如:左边的表格想合并单元格成右边的表格更加便于观看 一.依赖文件 <!-- excle操作--> <depen ...
- 鸿蒙接入Flutter3.22
配置环境变量 配置HarmonyOS SDK和环境变量 API12, deveco-studio-5.0 或 command-line-tools-5.0 配置 Java17 配置环境变量 (SDK, ...
- 4G模组软件指南 | 必读篇之模块信息(hmeta)
今天我讲解的这篇关于4G模组软件的模块信息属于必读篇,望珍惜! 1.模块信息概述 模块信息是每一个模块携带的信息,就像人的身份证一样,这些信息确定了模块的唯一性; 包含设备唯一id,硬件型号,模组的硬 ...
- The 2024 ICPC Asia East Continent Online Contest (I) C
Link: Permutation Counting 4 我的评价是神题,给出两种做法. 方法一 利用线代技巧. 设法构造矩阵 \(A\), 其中 \(A_{ij} = [j \in [l_i, r_ ...
- 【一步步开发AI运动小程序】四、小程序如何抽帧
随着人工智能技术的不断发展,阿里体育等IT大厂,推出的"乐动力"."天天跳绳"AI运动APP,让云上运动会.线上运动会.健身打卡.AI体育指导等概念空前火热.那 ...
- CodeForces - 1336A Linova and Kingdom
CodeForces - 1336A 就差一点点,很可惜,少发现个很显而易见的结论 就是一个点的价值,实际上就是(这个点的深度 - 之后的点的数目) 就是 \(depth_i - size_i\) 然 ...
- 深入解析 WezTerm 的自定义功能:键绑定和鼠标绑定
WezTerm 是一个高性能的跨平台终端模拟器,它提供了广泛的自定义选项,包括键绑定和鼠标绑定,使得用户可以根据自己的需求优化操作界面.本文将详细介绍几个关键的自定义功能,解释它们的用途,并展示如何配 ...
- python之pyexecjs
pyexecjs是一个用Python来执行JavaScript代码的工具库,该库支持多种JavaScript运行时环境,如Node.js.PhantomJS.SlimerJS等,允许开发者在Pytho ...
- Winform解决跨线程更新UI的问题
最近又拿起了Winform的程序,由于要起socket server,所以需要起线程,这里就遇到了经典的跨线程UI调用的问题. 如果什么都不写,直接由线程更新UI,会报错:线程间操作无效. 这里的解决 ...