Mssql合并查询结果
在项目开发中,有时会碰到将列记录合并为一行的情况,例如根据地区将人员姓名合并,或根据拼音首字母合并城市等,下面就以根据地区将人员姓名合并为例,详细讲一下合并的方法。
首先,先建一个表,并添加一些数据,建表代码如下:
If OBJECT_ID(N'Demo') Is Not Null
Begin
Drop Table Demo
End
Else
Begin
Create Table Demo(
Area nvarchar(30),
Name nvarchar(20))Insert Into Demo(Area,Name)
Values(N'北京',N'张三'),
(N'上海',N'李四'),
(N'深圳',N'王五'),
(N'深圳',N'钱六'),
(N'北京',N'赵七'),
(N'北京','Tom'),
(N'上海','Amy'),
(N'北京','Joe'),
(N'深圳','Leo')
End
Go
建完后查询一下,可见表中数据如下:

如果仅将Name列合并,不遵循任何条件的话,我们可以采用两种方法,第一种就是采用FOR XML PATH方式,代码如下:
SELECT ','+Name FROM dbo.Demo FOR XML PATH('')
运行结果如下:
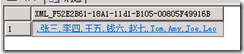
关于FOR XML PATH的详细介绍可参考MSDN:搭配 FOR XML 使用 PATH 模式
第二种方法就是定义一个变量用来装载查询的结果,代码如下:
Declare @NameCollection nvarchar(500)
Select @NameCollection=ISNULL(@NameCollection+',','')+Name From dbo.Demo
Select @NameCollection as NameCollection
运行结果如下:
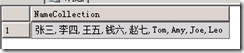
加了ISNULL是因为最开始变量@NameCollection为NULL,为了避免“张三”前多一个逗号(“,”)而采用的替换。
上面讲了在无条件的情况下合并一列,但是在项目中几乎不会遇到这样的情况,一般都是根据某一列来合并另一列的数据,例如我们现在要根据Area将Name合并,得到这样的结果:
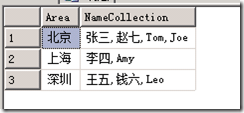
有了上面的基础,要合并成这样的数据就容易了,我们只需要针对Area列采用聚合GROUP BY或取不重复值DISTINCT,然后根据Area列合并Name列,有了思路,下面就来说说如何实现,首先还是采用FOR XML PATH方式,结合自连接,首先先按Area列对Name列进行合并,代码如下:
SELECT Area,
(SELECT ','+Name FROM dbo.Demo WHERE Area = t.Area FOR XML PATH(''))
AS NameCollection FROM dbo.Demo AS t
运行结果如下:
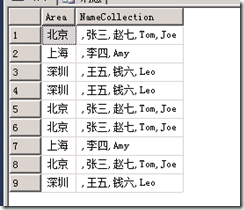
现在有两点还没实现,第一是结果重复了,第二是NameCollection列最开始都多了一个逗号,先去掉逗号,采用STUFF 函数来进行替换,代码修改如下:
SELECT Area,
STUFF((SELECT ','+Name FROM dbo.Demo WHERE Area = t.Area FOR XML PATH('')),1,1,'')
AS NameCollection FROM dbo.Demo AS t
现在运行后结果如下:
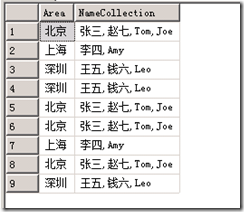
下面就剩下去掉重复数据了,分别采用GROUP BY和DISTINCT,代码如下:
SELECT DISTINCT Area,
STUFF((SELECT ','+Name FROM dbo.Demo WHERE Area = t.Area FOR XML PATH('')),1,1,'')
AS NameCollection FROM dbo.Demo AS t
SELECT Area,
STUFF((SELECT ','+Name FROM dbo.Demo WHERE Area = t.Area FOR XML PATH('')),1,1,'')
AS NameCollection FROM dbo.Demo AS t GROUP BY Area
关于STUFF函数可以参考MSDN介绍:STUFF函数
运行结果即为最终我们需要的结果,最开始在上面讲到了一种用变量来装载查询结果实现合并一列的方法,下面详细介绍如何采用上述方法来实现我们的需求,我们可以根据上面的方法建一个函数,传入一个Area参数,根据Area来进行合并,返回合并值,函数如下:
CREATE FUNCTION MergeByColumn
(
-- Add the parameters for the function here
@Area nvarchar(30)
)
RETURNS nvarchar(500)
AS
BEGIN
-- Declare the return variable here
DECLARE @NC nvarchar(500)-- Add the T-SQL statements to compute the return value here
SELECT @NC=ISNULL(@NC+',','')+Name FROM dbo.Demo WHERE Area=@Area-- Return the result of the function
RETURN @NCEND
GO
建好后测试下,以传入参数为“北京”为例,运行如下代码:
SELECT dbo.MergeByColumn('北京') AS NameCollection
得到结果如下:

现在只需将Area列也加入查询即可,修改代码如下:
SELECT Area,dbo.MergeByColumn(Area) AS NameCollection From dbo.Demo
现在也得到了重复的结果,如下:
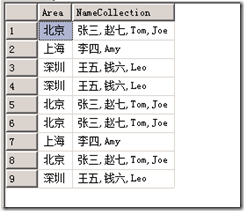
去重复同样可以用GROUP BY和DISTINCT,代码如下,即可以得到我们最终的结果:
SELECT DISTINCT Area,dbo.MergeByColumn(Area) AS NameCollection From dbo.Demo
SELECT Area,dbo.MergeByColumn(Area) AS NameCollection From dbo.Demo GROUP BY Area
Mssql合并查询结果的更多相关文章
- SQL多表合并查询结果
两表合并查询,并同时展示及分页SELECT a.* FROM ( ( SELECT punycode, `domain`, 'Success' AS state, add_time, AS refun ...
- oracle中的连接查询与合并查询总结
连接查询: 连接查询是指基于多张表或视图的查询.使用连接查询时,应指定有效的查询条件,不然可能会导致生成笛卡尔积.如现有部门表dept,员工表emp,以下查询因查询条件无效,而产生笛卡尔积: (各 ...
- 7-11使用UNION合并查询
合并查询的语法: SELECT ...FROM 表名一 UNION SELECT ...FROM 表名二 合并查询的特点: 1: 合并表中的列的个数,数据类型数据类型相同或兼容. 2:UNION 默 ...
- SQL SERVER连接、合并查询
----创建测试表MyStudentInfoCREATE table MyStudentInfo( Id int not null primary key, Name varchar(16), ...
- oracle 基础SQL语句 多表查询 子查询 分页查询 合并查询 分组查询 group by having order by
select语句学习 . 创建表 create table user(user varchar2(20), id int); . 查看执行某条命令花费的时间 set timing on: . 查看表的 ...
- Oracle 表复杂查询之多表合并查询
转自:https://www.cnblogs.com/GreenLeaves/p/6635887.html 本文使用到的是oracle数据库scott方案所带的表,scott是oracle数据库自带的 ...
- sql 内连接 子查询 合并查询
-- 内连接:-- 显示员工姓名.工资和公司所在地 select e.ename, e.sal, d.dname from emp e,dept d; -- 笛卡尔积 select e.ename, ...
- oracle的多表合并查询-工作心得
本随笔文章,由个人博客(鸟不拉屎)转移至博客园 发布时间: 2018 年 11 月 29 日 原地址:https://niaobulashi.com/archives/oracle-select-al ...
- 使用union合并查询
语法: select …..from 表1 union select ……from 表2 2. 合并查询的特点 ① 合并的表中的列的个数.数据类型必须相同或向兼容. ② union默认去掉重复值,如果 ...
随机推荐
- ssm项目导入activiti依赖后jsp页面el表达式报错
错误原因:Tomcat8.x与activiti6.0依赖冲突导致 解决方法: 1.修改tomcat版本 2.在pom.xml中修改 在依赖中把 <dependency> <group ...
- STM32 BOR/POR/PDR介绍
以STM32为例,介绍单片机中的BOR/POR/PDR1)PVD = Programmable Votage Detector 可编程电压监测器 它的作用是监视供电电压,在供电电压下降到给定的阀值以下 ...
- ANSYS分析中的单位
ANSYS输入的数值的单位换算比较复杂,参数的单位需要自己进行定义. 不同单位对应课件文件
- zabbix使用客户端和不使用客户端监控指定端口
监控指定端口也很简单,以监控181主机的22端口为例 点击已成功监控的181主机的监控项 点击创建监控项 使用客户端监控端口:选择键值net.tcp.listen[port],需要自己把port改成2 ...
- TypeScript 学习资料
TypeScript 学习资料: 学习资料 网址 TypeScript Handbook(中文版)(推荐) https://m.runoob.com/manual/gitbook/TypeScript ...
- 基于javaMail的邮件发送--excel作为附件
基于JavaMail的Java邮件发送 Author xiuhong.chen@hand-china.com Desc 简单邮件发送 Date 2017/12/8 项目中需要根据物料资质的状况实时给用 ...
- django中form页面刷新后自动提交的解决方案
如果一个页面包含了form,同时这个form中的提交按钮是type=submit的input的时候,你刷新该页面,就会有弹窗提示是否重新提交表单,这个特性不胜其烦,常见解决方法有两个: 第一种是前端的 ...
- LeetCode——688. Knight Probability in Chessboard
一.题目链接:https://leetcode.com/problems/knight-probability-in-chessboard/ 二.题目大意: 给定一个N*N的棋盘和一个初始坐标值(r, ...
- python3学习笔记10(迭代器和生成器)
参考http://www.runoob.com/python3/python3-iterator-generator.html 迭代器 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束 ...
- 1.编写一个shell脚本
一.shell和shell脚本 在linux系统下,以 #/bin/bash开头的文本会被shell解释器进行解释. shell是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操 ...