【Hadoop】3、Hadoop-MapReduce使用avro进行数据的序列化与反序列化
package cn.cutter.demo.hadoop.avro; import org.apache.hadoop.io.Text; import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date; /**
* @ClassName NcdcRecordParser
* @Description TODO
* @Author xiaof
* @Date 2019/2/17 16:36
* @Version 1.0
**/
public class NcdcRecordParser {
private static final int MISSING_TEMPERATURE = 9999; private static final DateFormat DATE_FORMAT =
new SimpleDateFormat("yyyyMMddHHmm"); private String stationId;
private String observationDateString;
private String year;
private String airTemperatureString;
private int airTemperature;
private boolean airTemperatureMalformed;
private String quality; public void parse(String record) {
stationId = record.substring(4, 10) + "-" + record.substring(10, 15);
observationDateString = record.substring(15, 27);
year = record.substring(15, 19);
airTemperatureMalformed = false;
// Remove leading plus sign as parseInt doesn't like them
if (record.charAt(87) == '+') {
airTemperatureString = record.substring(88, 92);
airTemperature = Integer.parseInt(airTemperatureString);
} else if (record.charAt(87) == '-') {
airTemperatureString = record.substring(87, 92);
airTemperature = Integer.parseInt(airTemperatureString);
} else {
airTemperatureMalformed = true;
}
airTemperature = Integer.parseInt(airTemperatureString);
quality = record.substring(92, 93);
} public void parse(Text record) {
parse(record.toString());
} public boolean isValidTemperature() {
return !airTemperatureMalformed && airTemperature != MISSING_TEMPERATURE
&& quality.matches("[01459]");
} public boolean isMalformedTemperature() {
return airTemperatureMalformed;
} public boolean isMissingTemperature() {
return airTemperature == MISSING_TEMPERATURE;
} public String getStationId() {
return stationId;
} public Date getObservationDate() {
try {
System.out.println(observationDateString);
return DATE_FORMAT.parse(observationDateString);
} catch (ParseException e) {
throw new IllegalArgumentException(e);
}
} public String getYear() {
return year;
} public int getYearInt() {
return Integer.parseInt(year);
} public int getAirTemperature() {
return airTemperature;
} public String getAirTemperatureString() {
return airTemperatureString;
} public String getQuality() {
return quality;
} }
通过avro输出数据,我们的数据集是:
0067011990999991950051507004+68750+023550FM-12+038299999V0203301N00671220001CN9999999N9+00001+99999999999
0043011990999991950051512004+68750+023550FM-12+038299999V0203201N00671220001CN9999999N9+00221+99999999999
0043011990999991950051518004+68750+023550FM-12+038299999V0203201N00261220001CN9999999N9-00111+99999999999
0043012650999991949032412004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+01111+99999999999
0043012650999991949032418004+62300+010750FM-12+048599999V0202701N00461220001CN0500001N9+00781+99999999999
package cn.cutter.demo.hadoop.avro; import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.mapred.*;
import org.apache.avro.mapreduce.AvroJob;
import org.apache.avro.mapreduce.AvroKeyOutputFormat;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.io.FileInputStream;
import java.io.IOException; /**
* @ClassName AvroGenericMaxTemperature
* @Description 通过avro记录的数据文件,使用MapReduce进行解析读取数据
* @Author xiaof
* @Date 2019/2/17 15:23
* @Version 1.0
**/
public class AvroGenericMaxTemperature extends Configured implements Tool { //转换json数据,avro的模式解析
private static final Schema SCHEMA = new Schema.Parser().parse("{\"name\":\"WeatherRecord\",\"doc\":\"A weather reading\",\"type\":\"record\",\"fields\":[{\"name\":\"year\",\"type\":\"int\"},{\"name\":\"temperature\",\"type\":\"int\"},{\"name\":\"stationId\",\"type\":\"string\"}]}"); public static class MaxTemperatureMapper extends Mapper<LongWritable, Text, AvroKey<Integer>, AvroValue<GenericRecord>> {
//创建天气解析类对象,数据记录对象
private NcdcRecordParser ncdcRecordParser = new NcdcRecordParser();
private GenericRecord genericRecord = new GenericData.Record(SCHEMA); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.解析数据
ncdcRecordParser.parse(value.toString()); //2.判断数据有效性
if(ncdcRecordParser.isValidTemperature()) {
//3.获取对应的数据进入记录record中,然后输出到上下文对象
genericRecord.put("year", ncdcRecordParser.getYearInt());
genericRecord.put("temperature", ncdcRecordParser.getAirTemperature());
genericRecord.put("stationId", ncdcRecordParser.getStationId());
context.write(new AvroKey<Integer>(ncdcRecordParser.getYearInt()), new AvroValue<GenericRecord>(genericRecord));
}
}
} public static class MaxTemperatureReducer extends Reducer<AvroKey<Integer>, AvroValue<GenericRecord>, AvroKey<GenericRecord>, NullWritable> {
@Override
protected void reduce(AvroKey<Integer> key, Iterable<AvroValue<GenericRecord>> values, Context context) throws IOException, InterruptedException {
//遍历所有的数据,获取最大的数据
GenericRecord max = null;
for(AvroValue<GenericRecord> value : values) {
//获取数据的值,判断max等于空,或者当前温度大于max记录的温度,那么就更新max
GenericRecord record = value.datum();
if(max == null || (Integer) record.get("temperature") > (Integer) max.get("temperature")) {
max = newWeatherRecord(record);
}
} context.write(new AvroKey(max), NullWritable.get());
} private GenericRecord newWeatherRecord(GenericRecord value) {
GenericRecord record = new GenericData.Record(SCHEMA);
record.put("year", value.get("year"));
record.put("temperature", value.get("temperature"));
record.put("stationId", value.get("stationId")); return record;
}
} @Override
public int run(String[] strings) throws Exception {
if (strings.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n",
getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Job job = Job.getInstance(this.getConf(), "Max temperature");
job.setJarByClass(this.getClass()); job.getConfiguration().setBoolean(Job.MAPREDUCE_JOB_USER_CLASSPATH_FIRST, true); FileInputFormat.addInputPath(job, new Path(strings[0]));
FileOutputFormat.setOutputPath(job, new Path(strings[1])); AvroJob.setMapOutputKeySchema(job, Schema.create(Schema.Type.INT));
AvroJob.setMapOutputValueSchema(job, SCHEMA);
AvroJob.setOutputKeySchema(job, SCHEMA); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(AvroKeyOutputFormat.class); job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class); return job.waitForCompletion(true) ? 0: 1; } public static void main(String[] args) throws Exception { System.setProperty("hadoop.home.dir", "F:\\hadoop-2.7.7");
String paths[] = {"H:\\ideaworkspace\\1-tmp\\input\\1.txt", "H:\\ideaworkspace\\1-tmp\\output1"}; int exitCode = ToolRunner.run(new AvroGenericMaxTemperature(), paths);
System.exit(exitCode); }
}
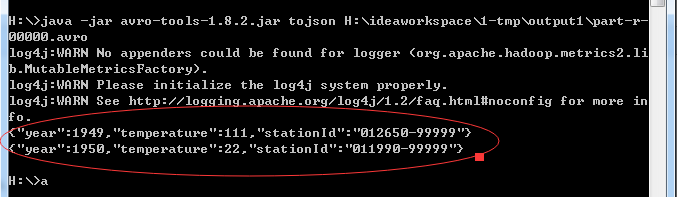
结果使用avro-tool进行查看:
H:\>java -jar avro-tools-1.8.2.jar tojson H:\ideaworkspace\1-tmp\output1\part-r-
00000.avro
【Hadoop】3、Hadoop-MapReduce使用avro进行数据的序列化与反序列化的更多相关文章
- 对 JSON 数据进行序列化和反序列化
如何:对 JSON 数据进行序列化和反序列化 2017/03/30 作者 JSON(JavaScript 对象符号)是一种高效的数据编码格式,可用于在客户端浏览器和支持 AJAX 的 Web 服务之间 ...
- Json数据的序列化与反序列化的三种经常用法介绍
下面内容是本作者从官网中看对应的教程后所做的demo.其体现了作者对相关知识点的个人理解..作者才疏学浅,难免会有理解不到位的地方.. 还请各位读者批判性对待... 本文主要介绍在Json数据的序列化 ...
- c#中对json数据的序列化和反序列化(笔记)
今天遇到在后台中要获取json格式数据里的某些值,网上查了些资料: string jsonstr = _vCustomerService.LoadCustomerbyNumTotalData(quer ...
- JS实现Ajax,Josn数据的序列化和反序列化---例: 省市区联动(包含get,post)
服务器端相应JOSN数据 用到序列化和反序列化----命名空间using System.Web.Script.Serialization; public void ProcessRequest(H ...
- Python 中数据的序列化和反序列化(json处理)
概念: JSON(JavaScript Object Notation):是一种轻量级的数据交换格式. 易于人阅读和编写.同时也易于机器解析和生成. 它基于JavaScript Programming ...
- 详解电子表格中的json数据:序列化与反序列化
从XML到JSON 当下应用开发常见的B/S架构之下,我们会遇到很多需要进行前后端数据传输的场景.而在这个传输的过程中,数据通过何种格式传输.方式是否迅速便捷.书写方式是否简单易学,都成为了程序员在开 ...
- NSFileManager(沙盒文件管理)数据持久化 <序列化与反序列化>
iOS应用程序只能在为该改程序创建的文件中读取文件,不可以去其它地方访问,此区域被成为沙盒,所以所有的非代码文件都要保存在此,例如图像,图标,声音,映像,属性列表,文本文件等. 默认情况下 ...
- fastjson生成和解析json数据,序列化和反序列化数据
本文讲解2点: 1. fastjson生成和解析json数据 (举例:4种常用类型:JavaBean,List<JavaBean>,List<String>,List<M ...
- 【转】GOOGLE-PROTOBUF与FLATBUFFERS数据的序列化和反序列化
转载自[黑米GameDev街区] 原文链接: http://www.himigame.com/unity3d-game/1607.html 关于Protobuf 通过本文的转载和分享的相关链接,足够 ...
随机推荐
- 博客三--tensorflow的队列及线程基本操作
连接我的开源中国账号:https://my.oschina.net/u/3770644/blog/3036960查询
- RNQOJ PID28 / [Stupid]愚蠢的宠物
勉勉强强够着点并查集的边,题目吧他分类到并查集也无可厚非,这里与常规的并查集的区别在于要做一个mark数组进行一下标记,展开来说就是对于要查询的A,B,先对A进行处理,把A所有的前驱也就是双亲节点进行 ...
- CKeditor5 图片上传
下面是自定义了一个适配器,之前我一直是在 ClassicEditor .create( editorElement, { ckfinder: { uploadUrl: '/ckfinder/core/ ...
- squid故障汇总
1.COSS will not function without large file support (off_t is 4 bytes long. Please reconsider recomp ...
- Postfix邮件服务器
http://www.postfix.org/INSTALL.html https://www.cnblogs.com/alex-note/p/6840160.html http://linux.vb ...
- ubuntu18.04时区设置
1.运行命令 sudo tzselect 2.选择大区 选择亚洲Asia,继续选择中国China,最后选择北京Beijing 3.建立软链 ln -sf /usr/share/zoneinfo/Asi ...
- spring深入学习(一)-----IOC容器
spring对于java程序员来说,重要性不可言喻,可以想象下如果没有他,我们要多做多少工作,下面一个系列来介绍下spring(5.x版本). spring模块 IOC概念 spring中最重要的两个 ...
- MySQL定时器
MySQL的定时器是一个很有用的功能,有时候需要数据库自动根据时间进行一些必要的操作,此时定时器就派上了用场了. 一.查看MySQL版本号 select version(); 二.查看event的状态 ...
- IDEL中easyui使用jstl和el出现传值不显示的问题
<%@ page language="java" contentType="text/html;charset=UTF-8" pageEncoding=& ...
- python opencv 处理文件、摄像头、图形化界面
转换成RGB import cv2 import numpy as ny img = ny.zeros( ( 3 , 3 ),ny.float32) img=cv2.cvtColor(img,cv2. ...