kaldi运行thchs30例子
首先,thchs30有两种数据库,kaldi运行的数据库最好是 thchs30-openslr。
修改run.sh里面的语音库路径 thchs30=...
修改nj线程数 等于CPU的核心数
修改cmd.sh queue.pl 改为run.pl本地机器跑
运行出现错误:
lexicon.txt验证出错
里面binary file matches
这是grep的问题,grep -v -a '<s>' | grep -v -a '</s>' | sort -u > data/dict/lexicon.txt || exit 1;
---------------------------------------------------------------------------------------------------------------------------
在线识别部分:
去egs下,打开voxforge,里面有个online_demo,直接考到thchs30下。在online_demo里面建2个文件夹online-data work,在online-data下建两个文件夹audio和models,audio下放你要回放的wav,models建个文件夹tri1,把s5下的exp下的tri1下的final.mdl和35.mdl(final.mdl是快捷方式)考过去。把s5下的exp下的tri1下的graph_word里面的words.txt,和HCLG.fst,考到models的tri1下。
类似处理,包括tri2b,tri3b,tri4b,不过后者需要添加转移矩阵,final.mat以及所指的mat文件。
如下所示,例如 tri2b文件夹下,
打开online_demo的run.sh
a)将下面这段注释掉:(这段是voxforge例子中下载现网的测试语料和识别模型的。我们测试语料自己准备,模型就是tri1了)
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Downloading test models and data ..."
wget -T 10 -t 3 $data_url;
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Download of $data_file has failed!"
exit 1
fi
fi
b) 然后再找到如下这句,将其路径改成tri1
ac_model_type=tri2b
if [ -s $ac_model/final.mat ]; then
trans_matrix=$ac_model/final.mat
echo "set matrix"
fi
online-gmm-decode-faster --rt-min=0.5 --rt-max=0.7 --max-active=4000 \
--beam=12.0 --acoustic-scale=0.0769 --left-context=3 --right-context=3 $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' $trans_matrix;;
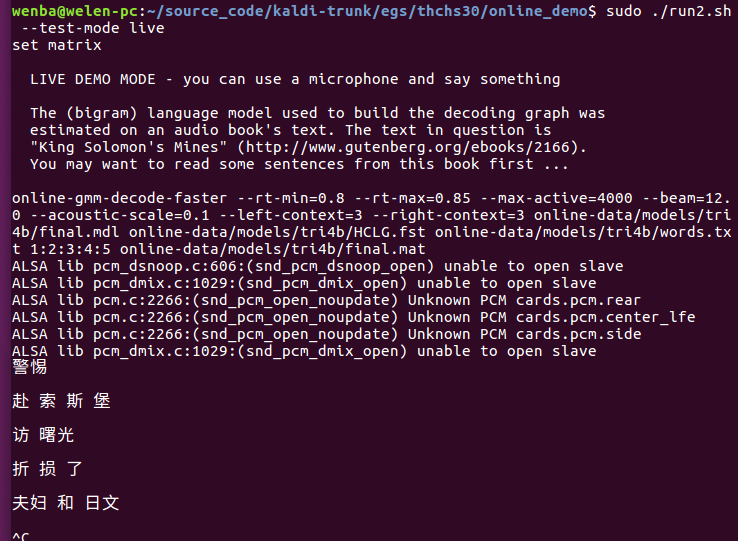
识别效果很差
kaldi运行thchs30例子的更多相关文章
- kaldi 运行voxforge例子
---------------------------------------------------------------------------------------------------- ...
- kaldi使用thchs30数据进行训练并执行识别操作
操作系统 : Ubutu18.04_x64 gcc版本 :7.4.0 数据准备及训练 数据地址: http://www.openslr.org/18/ 在 egs/thchs30/s5 建立 thch ...
- [Linux][Hadoop] 运行WordCount例子
紧接上篇,完成Hadoop的安装并跑起来之后,是该运行相关例子的时候了,而最简单最直接的例子就是HelloWorld式的WordCount例子. 参照博客进行运行:http://xiejiangl ...
- caffe简易上手指南(一)—— 运行cifar例子
简介 caffe是一个友好.易于上手的开源深度学习平台,主要用于图像的相关处理,可以支持CNN等多种深度学习网络. 基于caffe,开发者可以方便快速地开发简单的学习网络,用于分类.定位等任务,也可以 ...
- sparkR的一个运行的例子
在sparkR在配置完成的基础上,本例采用Spark on yarn模式,介绍sparkR运行的一个例子. 在spark的安装目录下,/examples/src/main/r,有一个dataframe ...
- (四)伪分布式下jdk1.6+Hadoop1.2.1+HBase0.94+Eclipse下运行wordCount例子
本篇先介绍HBase在伪分布式环境下的安装方式,然后将MapReduce编程和HBase结合起来使用,完成WordCount这个例子. HBase在伪分布环境下安装 一. 前提条件 已经成功地安装 ...
- RedHat 安装Hadoop并运行wordcount例子
1.安装 Red Hat 环境 2.安装JDK 3.下载hadoop2.8.0 http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/had ...
- 八、VTK安装并运行一个例子
一.版本 win10 VS2019 VTK8.2.0 其实vtk的安装过程和itk的安装过程很是类似,如果你对itk的安装很是熟悉(也就是我的博客一里面的内容,那么自己就可以安装.) 如果不放心,可以 ...
- 配置RHadoop与运行WordCount例子
1.安装R语言环境 su -c 'rpm -Uvh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch. ...
随机推荐
- 通过decorators = [,] 的形式给类中的所有方法添加装饰器
给类添加装饰器有多种方法: 1.可以在类中的某个方法上边直接@添加,这个粒度细.无需详细介绍 2.也可以在类中通过 decorators=[, ]的形式添加,这样的话,类中的所有方法都会被一次性加上装 ...
- python 将mysql数据库中的int类型修改为NULL 报1366错误,解决办法
gt.run_sql()是用pymysql 封装的类 distribution_sort_id type: int目的:将此字段值全部修改为NULL g=2gt.run_sql("updat ...
- PHP整理--MySQL--DOS命令操作数据库
一.MySQL:关系型数据库,存在表的概念. MySQL的结构:数据库可以存放很多表,每张表可以存放多个字段,每个字段可以存放多个记录. 二.Dos操作数据库 用PHPStudy终端➡其他选项菜单➡M ...
- php JS 导出表格特殊处理
但是这样导出身份证号会变为科学计数: 解决方法就是: 我们了解一下excel从web页面上导出的原理.当我们把这些数据发送到客户端时,我们想让客户端程序(浏览器)以excel的格式读取 它,所以把mi ...
- [Hbase]Hbase章4 Hbase分区爆了
又搞事了,发生了啥事呢:生产分区数暴了,What? 目前的情况: 前提:单Region Server分区上限设置为1000: 目前A表的数据量半年达到25E,20G一分区,达到了900多个分区,这是要 ...
- IntelliJ隐藏特定后缀文件
preference-
- Centos7搭建SS以及加速配置的操作记录 (转载)
原文地址https://www.cnblogs.com/kevingrace/p/8495424.html 部署 Shadowsocks之前,对它做了一个简单的了解,下面先介绍下.一道隐形的墙众所周知 ...
- ----constructor 与 object----
CONSTRUCTOR constructor是一种特殊的object,同样是用来创建和声明一个类 语法规则: constructor([arguments]) { ... } 注意: 1.在类中,只 ...
- sql server 临时库文件太大 迁移tempdb数据库
由于装SQL Server时默认装在系统盘,使用一段时间后,tempdb数据库占了68G,导致整个C盘爆满,彻底解决办法就是迁移tempdb物理文件,移至其他大空间磁盘上. 将 tempdb 从其在磁 ...
- json解析Object
最近的工作是在数据库使用myBaties查出的数据没有实体, 比如: <select id="allTree" parameterType="String" ...