kaldi运行thchs30例子
首先,thchs30有两种数据库,kaldi运行的数据库最好是 thchs30-openslr。
修改run.sh里面的语音库路径 thchs30=...
修改nj线程数 等于CPU的核心数
修改cmd.sh queue.pl 改为run.pl本地机器跑
运行出现错误:
lexicon.txt验证出错
里面binary file matches
这是grep的问题,grep -v -a '<s>' | grep -v -a '</s>' | sort -u > data/dict/lexicon.txt || exit 1;
---------------------------------------------------------------------------------------------------------------------------
在线识别部分:
去egs下,打开voxforge,里面有个online_demo,直接考到thchs30下。在online_demo里面建2个文件夹online-data work,在online-data下建两个文件夹audio和models,audio下放你要回放的wav,models建个文件夹tri1,把s5下的exp下的tri1下的final.mdl和35.mdl(final.mdl是快捷方式)考过去。把s5下的exp下的tri1下的graph_word里面的words.txt,和HCLG.fst,考到models的tri1下。
类似处理,包括tri2b,tri3b,tri4b,不过后者需要添加转移矩阵,final.mat以及所指的mat文件。
如下所示,例如 tri2b文件夹下,
打开online_demo的run.sh
a)将下面这段注释掉:(这段是voxforge例子中下载现网的测试语料和识别模型的。我们测试语料自己准备,模型就是tri1了)
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Downloading test models and data ..."
wget -T 10 -t 3 $data_url;
if [ ! -s ${data_file}.tar.bz2 ]; then
echo "Download of $data_file has failed!"
exit 1
fi
fi
b) 然后再找到如下这句,将其路径改成tri1
ac_model_type=tri2b
if [ -s $ac_model/final.mat ]; then
trans_matrix=$ac_model/final.mat
echo "set matrix"
fi
online-gmm-decode-faster --rt-min=0.5 --rt-max=0.7 --max-active=4000 \
--beam=12.0 --acoustic-scale=0.0769 --left-context=3 --right-context=3 $ac_model/final.mdl $ac_model/HCLG.fst \
$ac_model/words.txt '1:2:3:4:5' $trans_matrix;;
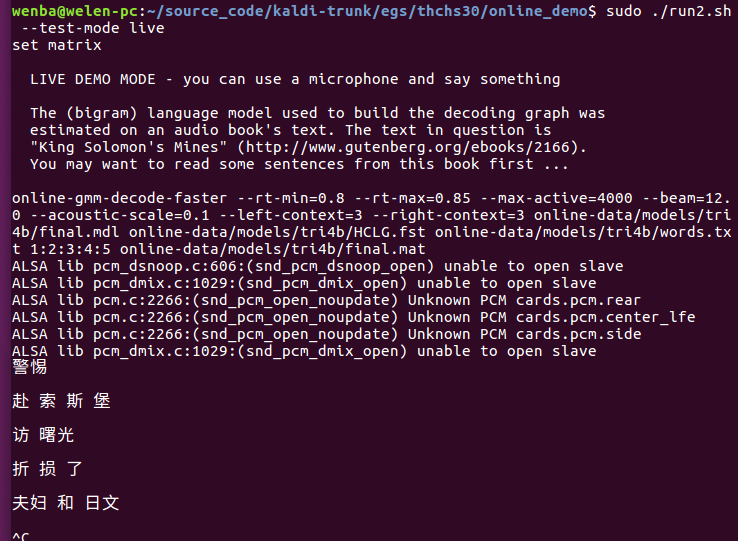
识别效果很差
kaldi运行thchs30例子的更多相关文章
- kaldi 运行voxforge例子
---------------------------------------------------------------------------------------------------- ...
- kaldi使用thchs30数据进行训练并执行识别操作
操作系统 : Ubutu18.04_x64 gcc版本 :7.4.0 数据准备及训练 数据地址: http://www.openslr.org/18/ 在 egs/thchs30/s5 建立 thch ...
- [Linux][Hadoop] 运行WordCount例子
紧接上篇,完成Hadoop的安装并跑起来之后,是该运行相关例子的时候了,而最简单最直接的例子就是HelloWorld式的WordCount例子. 参照博客进行运行:http://xiejiangl ...
- caffe简易上手指南(一)—— 运行cifar例子
简介 caffe是一个友好.易于上手的开源深度学习平台,主要用于图像的相关处理,可以支持CNN等多种深度学习网络. 基于caffe,开发者可以方便快速地开发简单的学习网络,用于分类.定位等任务,也可以 ...
- sparkR的一个运行的例子
在sparkR在配置完成的基础上,本例采用Spark on yarn模式,介绍sparkR运行的一个例子. 在spark的安装目录下,/examples/src/main/r,有一个dataframe ...
- (四)伪分布式下jdk1.6+Hadoop1.2.1+HBase0.94+Eclipse下运行wordCount例子
本篇先介绍HBase在伪分布式环境下的安装方式,然后将MapReduce编程和HBase结合起来使用,完成WordCount这个例子. HBase在伪分布环境下安装 一. 前提条件 已经成功地安装 ...
- RedHat 安装Hadoop并运行wordcount例子
1.安装 Red Hat 环境 2.安装JDK 3.下载hadoop2.8.0 http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/had ...
- 八、VTK安装并运行一个例子
一.版本 win10 VS2019 VTK8.2.0 其实vtk的安装过程和itk的安装过程很是类似,如果你对itk的安装很是熟悉(也就是我的博客一里面的内容,那么自己就可以安装.) 如果不放心,可以 ...
- 配置RHadoop与运行WordCount例子
1.安装R语言环境 su -c 'rpm -Uvh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch. ...
随机推荐
- jmeter在几个固定的字符串中,随机取其中之一的方法
在测试过程中遇到上送字段必需是几个固定值中的一个, 使用读取文件中几个固定值,然后随机在这几个固定值中选择的办法解决问题 __CSVRead() CSV file to get values from ...
- 【深度好文】多线程之WaitHandle-->派生EventWaitHandle事件构造-》AutoResetEvent、ManualResetEvent
AutoResetEvent/ManualResetEvent 都是继承自 EventWaitHandle ,EventWaitHandle继承自WaitHandle. 在讨论这个问题之前,我们先了解 ...
- 位移运算 << >> >>>
位移运算都是补码的运算 左移<<:左移后第一位可能是1,也可能是0,所以可能是正数,也可能是负数,正负都补0 右移>>:抹掉最后一位,近似于十进制值除以2,负数右移高位补1,正 ...
- 关于Promise的记录和理解
在JavaScript中,所有的代码都是单线程执行的,这就导致了其所有的网络请求,IO操作,浏览器时间等都是异步非阻塞的模式执行的,这就使得代码的执行顺序可能会超出我们的掌控. 尤其是当多个异步操作待 ...
- APP支付(.NET版)
---恢复内容开始--- APP支付(.NET版) 一. 支付宝支付 1. 有一个支付账号,在蚂蚁金服开放平台中登录账号→选择“管理中心”→在“开发者中心”下选择“网页&移动应用”→然后按 ...
- Python调用Linux bash命令
import subprocess as sup # 以下注释很多(为了自己以后不忘), 如果只是想在python中执行Linux命令, 看前5行就够了 # 3.5版本之后官方推荐使用sup.run ...
- VB中将类标记为可序列化
引用名空间: Imports SystemImports System.Runtime.Serialization 在类前加特性: <Serializable> 更多内容: https:/ ...
- 结对项目——四则运算GUI项目
一.项目地址:https://git.coding.net/lvgx/wsz.git 二.PSP: PSP2.1 任务内容 计划共完成需要的时间(min) 实际完成需要的时间(min) Plannin ...
- oracle的部分增删查改
1. 创建表空间 create tablespace (demo)表名 logging datafile( 表空间存放的位置) ‘D:\app\Administrator\oradata\orcl\ ...
- 博客六--Tensorflow卷积神经网络的自主搭建
本人较懒也很忙,所以就不重复工作.连接我的开源中国博客查询:https://my.oschina.net/u/3770644/blog/3042523