day19 正则,re模块
http://www.cnblogs.com/Eva-J/articles/7228075.html 所有常用模块的用法
正则的规则:
在一个字符组里面枚举合法的所有字符,字符组里面的任意一个字符和‘带匹配字符’都相同,都视为可以匹配。

#
#是数字
#11位
#以13|15|17|18|16|14
# num = input('phone_number : ')
# if num.isdigit() and len(num) == 11 and num.startswith('13') or \
# num.startswith('14') or \
# num.startswith('15') or \
# num.startswith('17') or \
# num.startswith('18'):
# print('是一个格式正确的电话号码') # import re
# phone_number = input('please input your phone number : ')
# if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
# print('是合法的手机号码')
# else:
# print('不是合法的手机号码') #100万
#找到所有的电话号码 #正则 —— 通用的,处理 字符串
#正则表达式
#正则 是一种 处理文字 的 规则
#给我们提供一些规则,让我们从杂乱无章的文字中提取有效信息 #模块
#它只是我们使用python去操作一些问题的工具而已,和要操作的这个东西本身是两件事情 #re模块 —— python使用正则
#正则规则
#需要记忆的特别多:两大类 #[字符组]
#表示在一个字符的位置可以出现的所有情况的集合就是一个字符组 #表示数字的字符组:
#[13456782]
#[0123456789]
#[0-9]
#[2-8]
#简写模式必须由小到大 #表示字母的字符组
#[abcd]
#[a-z]
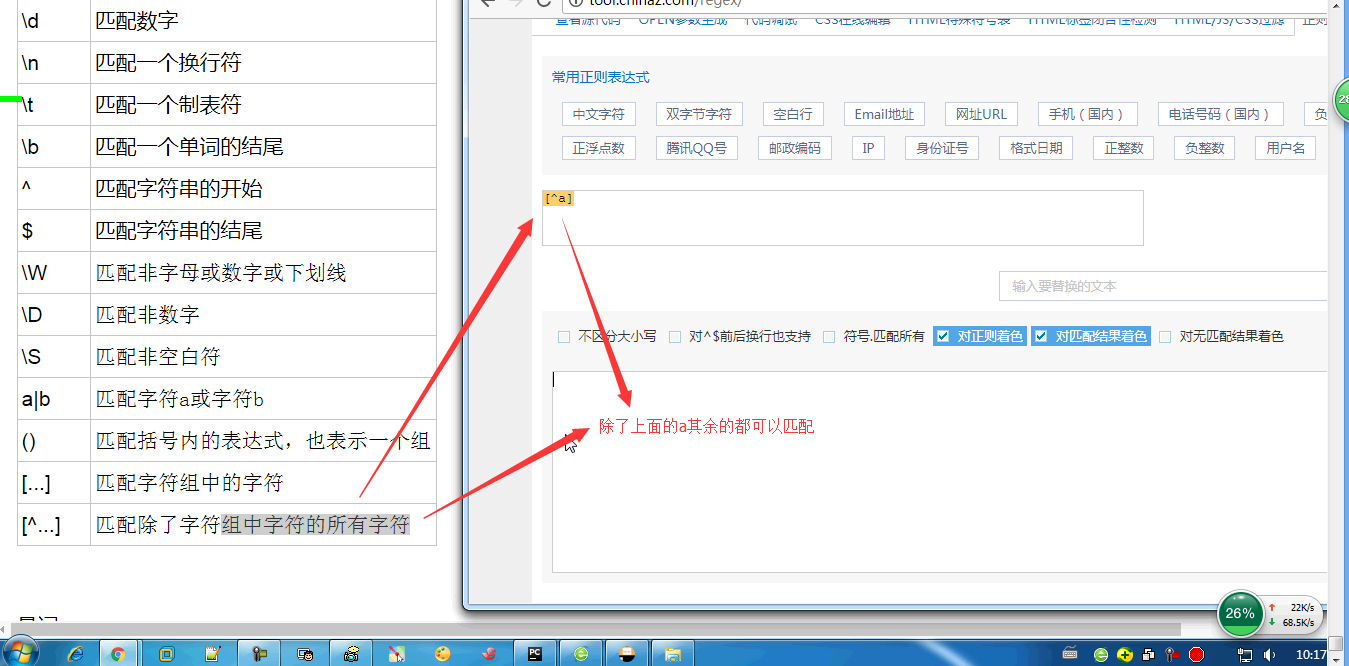
#[A-Z] #表示匹配任意字符 : [\w\W][\d\D][\S\s] #正则匹配:字符 量词 非贪婪标志
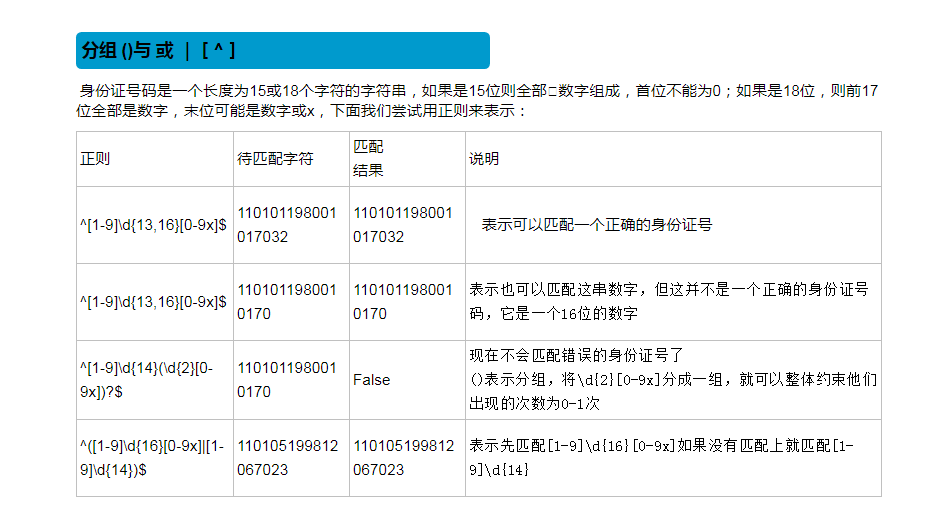
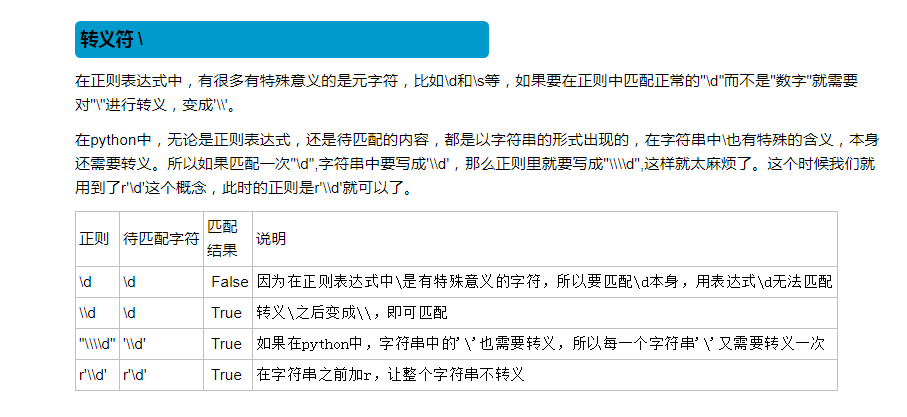
# 字符:字符、字符组、元字符 表示一个字符位置上可以出现的内容 #身份证号
# 15:首位不能为零,数字组成
# 18:首位不能为零,前17位是数字,最后一位可以是数字或者x # print('\\\\n')
# print('\\n') #r('\n') #r'\\n' --> r'\n'
#在在线工具中能执行,放到Python的字符串中,表示成r''就可以正常的执行了
re模块:
import re
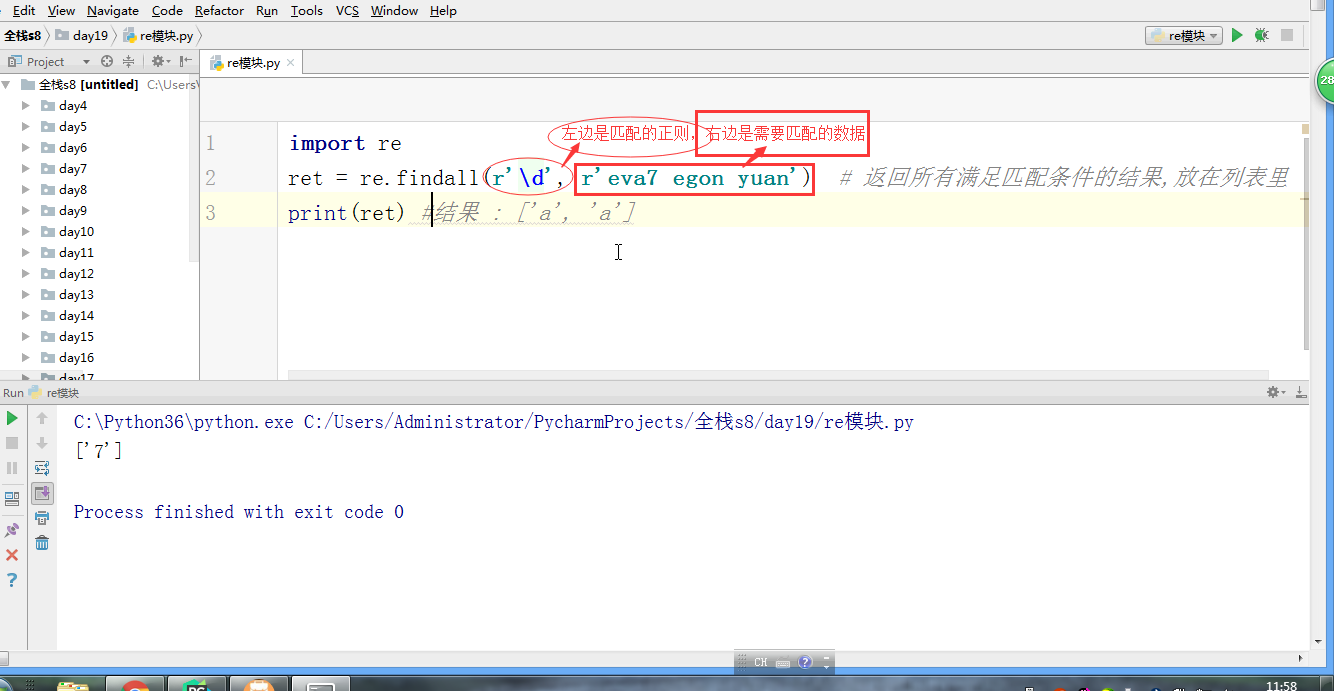
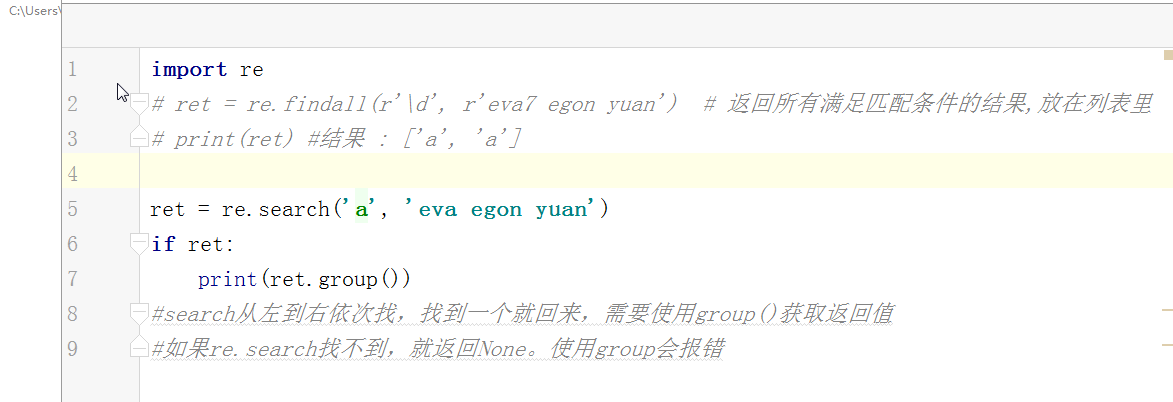
# ret = re.findall(r'\d', r'eva7 egon yuan') # 返回所有满足匹配条件的结果,放在列表里,返回结果一定是一个列表
# print(ret) #结果 : ['a', 'a'] # ret = re.search('a', 'eva egon yuan')
# if ret:
# print(ret.group()) # 这里返回的值只有一个a”
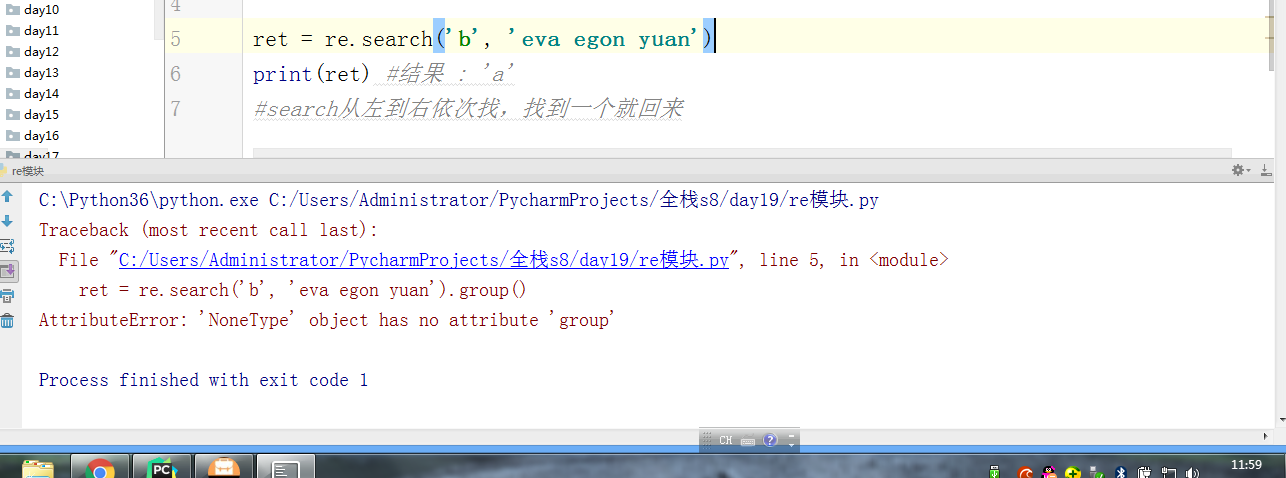
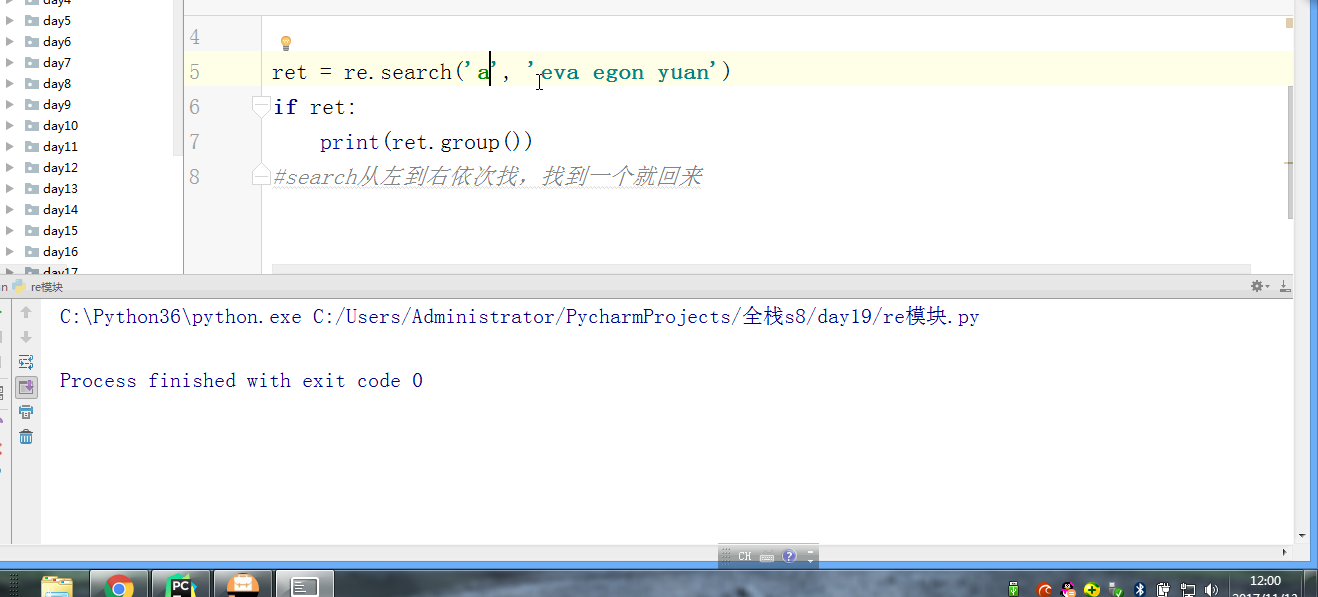
#search从左到右依次找,找且只找一个可以与之匹配的结果,然后返回,(这里可以跟findall做一下对比,如果有多个值与之匹配,也仅仅返回一个值而已,如果找不到就返回None,返回None的时候是无法用group获取数据的会报错)需要使用group()获取返回值
#如果re.search找不到,就返回None。返回None时,使用group会报错 # ret = re.match('a', 'bva egon yuan')
# print(ret.group())
#match只是匹配索引值为0的值,仅仅这一位而已,后面的都不匹配,匹配上了需要使用group来获取返回值(一般用不到match,实用性太低了,可替代性强,上面的findall和search都可以替代它)
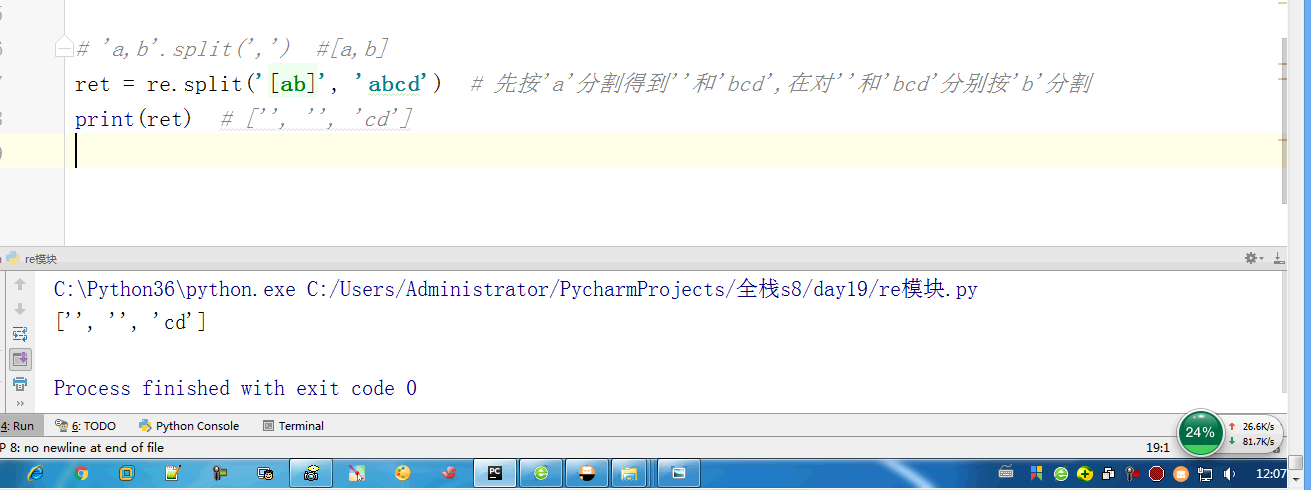
#匹配不上返回None,返回None时,如果使用group会报错 # 'a,b'.split(',') #[a,b]
# ret = re.split('[ac]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
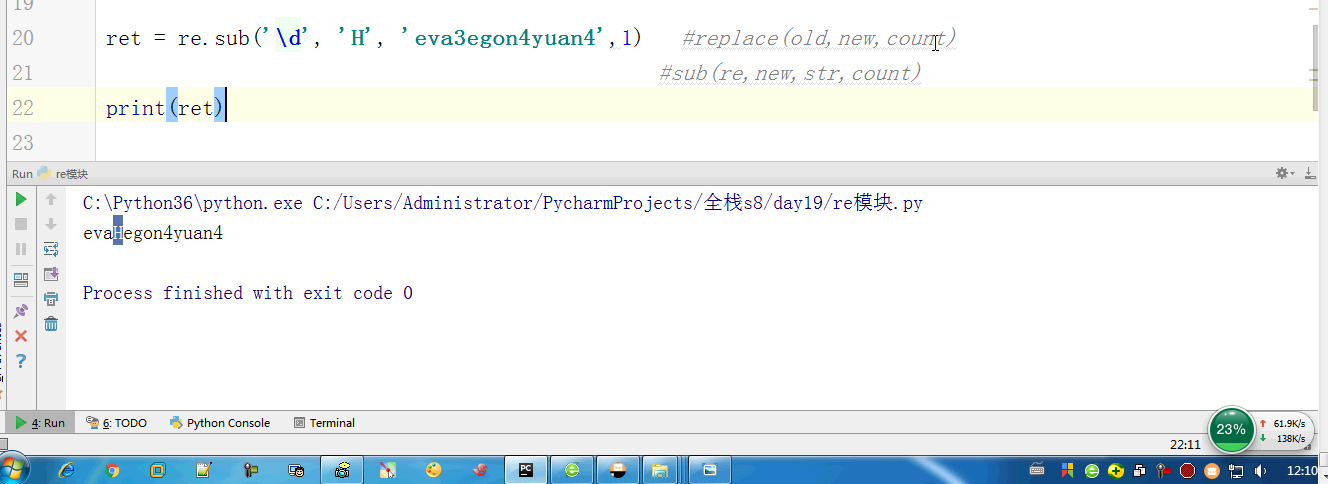
# print(ret) # ['', '', 'cd'] # ret = re.sub('\d', 'H', 'eva3egon4yuan4',1) #replace(old,new,count)
# #sub(re,new,str,count)
# print(ret) # ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
# print(ret) # obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
# ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
# print(ret.group()) #结果 : 123
#
# re.search('\d{3}','abc123eeee').group()
# re.search('\d{3}','bcd123eeee')
# re.search('\d{3}','efg123eeee')
# re.search('\d{3}','xyz123eeee') # re.findall() #[]
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
for i in ret:
print(i.group())
# print(next(ret).group()) #查看第一个结果
# print(next(ret).group()) #查看第二个结果
# print([i.group() for i in ret]) #查看剩余的左右结果 # findall
# search
# match
# split
# sub/subn
# compile
# finditer express = '1 - 2 * ( (60-30 +(-40/5) * (9-3.33 + 198/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )'
#正则表达式
#0. 去掉表达式中的所有空格
#1. 从表达式中匹配出所有的()里面不再有小括号的表达式
#2. 从表达式9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14中匹配出第一个乘法或者除法
#3. 计算简单的两个数之间的+-*/
#4. 递归——不用递归更简单 ——> 循环
#5. 博客上的数字匹配
re里面的sub模块的分组
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\1\2\3\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果:root:x:0:0::/root:/bin/bash
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\1\3\2\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果:rootx:0:0::/root:/bin:/bash
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\2\1\3\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果::rootx:0:0::/root:/bin/bash
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\3\1\2\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果:x:0:0::/root:/binroot:/bash
我们由上例子可得出,[1]是root [2]是: [3]是x:0:0::/root:/bin [4]是/ [5]是bash
所以我们的正则是分为了5个小组来匹配的,所以我们可以把这些小组进行排序,然后可以得到不同的结果



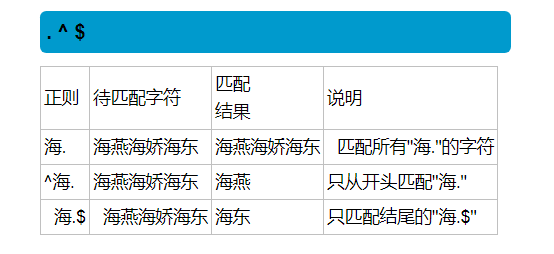
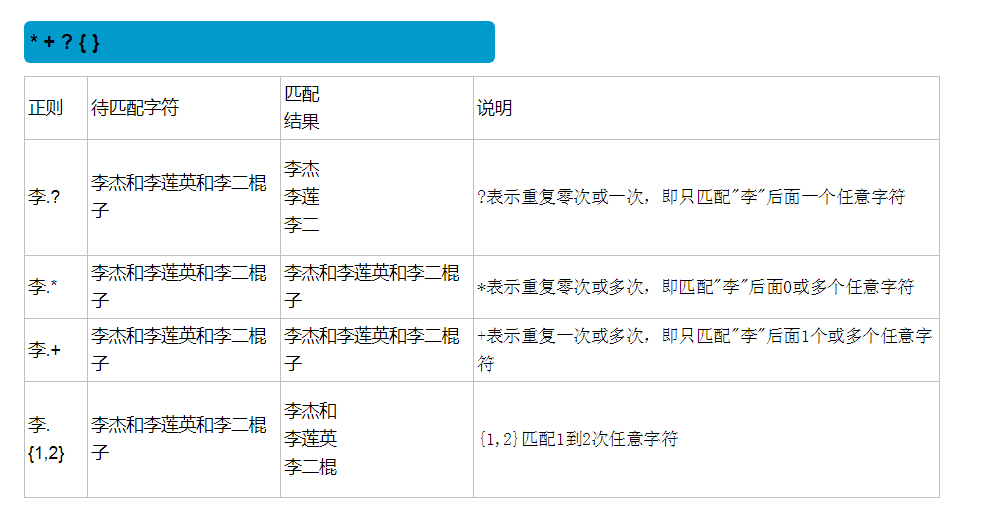
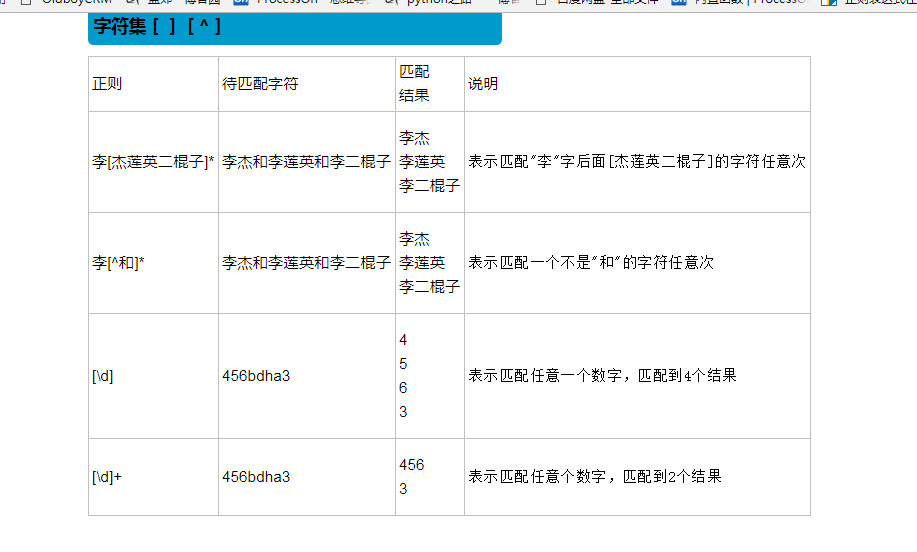
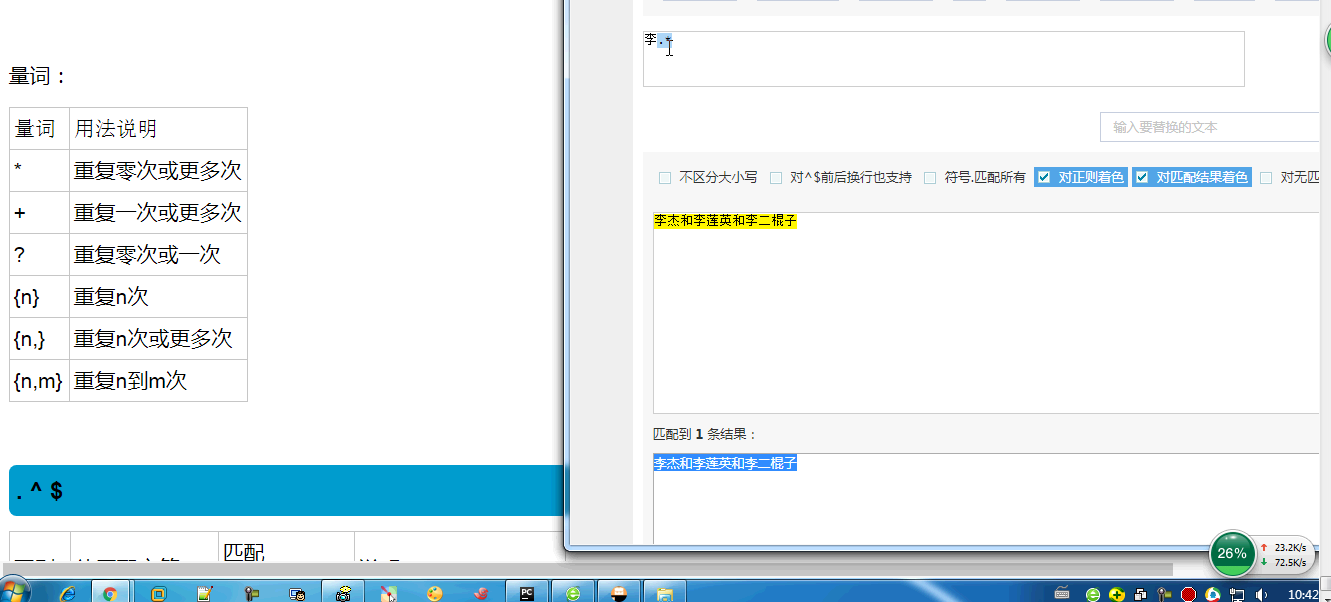
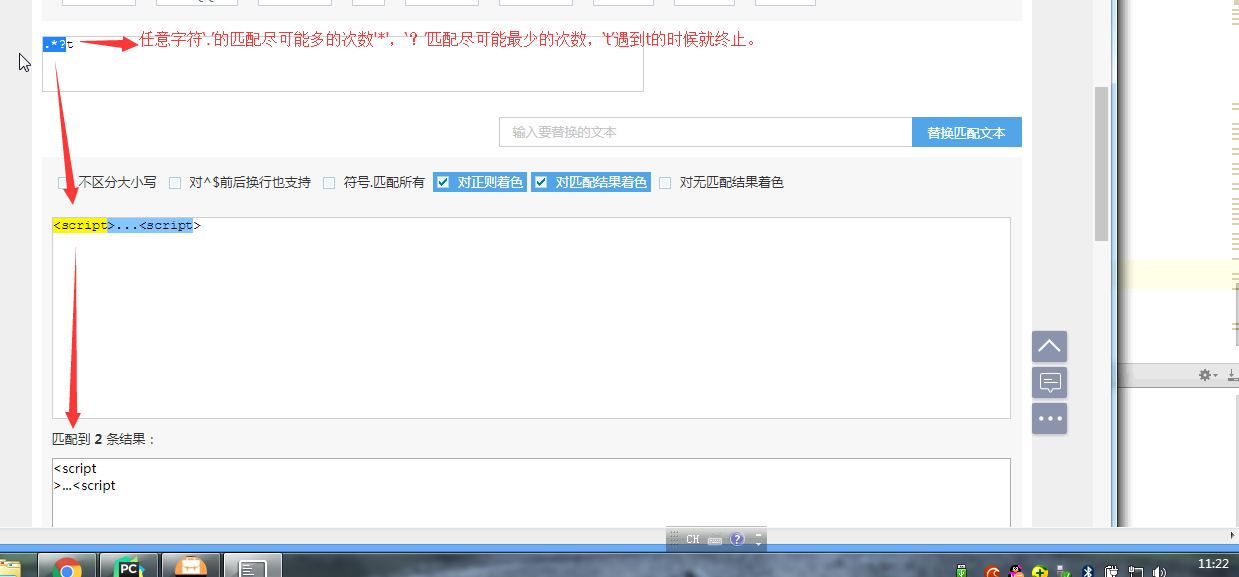
正则的一些小练习,灵活用法:


day19 正则,re模块的更多相关文章
- Python模块(三)(正则,re,模块与包)
1. 正则表达式 匹配字符串 元字符 . 除了换行 \w 数字, 字母, 下划线 \d 数字 \s 空白符 \n 换行符 \t 制表符 \b 单词的边界 \W \D \S 非xxx [ ...
- 日志(logging)与正则(re)模块
logging模块 #日志:日常的流水 =>日志文件,将程序运行过程中的状态或数据进行记录,一般都是记录到日志文件中 #1.logging模块一共分为五个打印级别 debug.info.warn ...
- python正则--re模块常用方法
前面几篇关于正则匹配的文章我用的方法都只有一个re.search 但其实正则re模块提供很多非常好用的方法,我们先来看看re模块都有那些属性方法呢 前面的一堆带_或者大写的就不关注了,主要关注最后面的 ...
- 正则 re模块
Python 正则表达式 re 模块 简介 正则表达式(regular expression)是可以匹配文本片段的模式.最简单的正则表达式就是普通字符串,可以匹配其自身.比如,正则表达式 ‘hello ...
- python的正则re模块
一. python的正则 python的正则模块re,是其内置模块,可以直接导入,即import re.python的正则和其他应用的正则及其相似,有其他基础的话,学起来还是比较简单的. 二. 正则前 ...
- python正则re模块
今日内容: 知识点一:正则 什么是正则: 就是用一系列具有特殊含义的字符组成一套规则,改规则用来描述具有某一特征的字符串 正则就是用来在一个大的字符串中取出符合规则的小字符串 为什么用正则: ...
- python 正则 re模块(详细版)
正则表达式 什么是正则表达式? 正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合 ...
- Python 正则表达模块详解
Python 的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承.Py ...
- python - re正则匹配模块
re模块 re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re ...
随机推荐
- html跳转指定位置-利用锚点
比如我现在 a.html 的时候,我想跳转到 b.html ,并且是 b.html 的某一个位置,用 <a href=>, a.html里: <a href="b.html ...
- 相关子查询和嵌套子查询 [SQL Server]
SQLServer子查询可以分为 相关子查询 和 嵌套子查询 两类.前提,假设Books表如下: 类编号 图书名 出版社 价格-------------- ...
- Js:消息弹出框、获取时间区间、时间格式、easyui datebox 自定义校验、表单数据转化json、控制两个日期不能只填一个
(function ($) { $.messageBox = function (message) { $.messager.show({ title:'消息框提示', msg:message, sh ...
- Confluence 6 查看你的许可证细节
希望查看你的 Confluence 许可证: 进入 > 基本配置(General Configuration). 在左侧的面板中选择 许可证详细(License Details). 你的许可证 ...
- vue之$forceUpdate
由于一些嵌套特别深的数据,导致数据更新了.UI没有更新(连深度监听都没有监听到) this.$forceUpdate();
- Oracle基础
一.Oracle数据库与实例区分 Oracle数据库是存在电脑磁盘中的文件 实例是存在内存中的进程 我们是通过操作实例间接操作数据库的 我们操作结果都存在内存缓存中,当我们提交事务时,才将修改数据记录 ...
- ionic3 git 提交报错
npm ERR! cordova-plugin-camera@ gen-docs: `jsdoc2md --template "jsdoc2md/TEMPLATE.md" &quo ...
- angularjs 监听 文档click 事件
项目 上遇到 innHTML 放入 一大段的html 内容 中带有 click 事件 如onclick="callInMethod("http://www.crm.bmcc.c ...
- mysql视图的作用
测试表:user有id,name,age,sex字段 测试表:goods有id,name,price字段 测试表:ug有id,userid,goodsid字段 视图的作用实在是太强大了,以下是我体验过 ...
- SQLmap注入启发式检测算法
1.经过setTargetEnv()就进入了checkWaf()的环节 def checkWaf(): """ Reference: http://sec ...