azkaban使用
新建一个text文件,a.job,打包成zip包传到azkaban即可
方式1:job流
1. a.job内容范例:
type=command
command=hive shell
command=hive -e 'set hive.execution.engine=tez;'
command=hive -e 'select * from hivedb.t_user limit 5;'
2.写法2:
zip包里放job和sql文件,如图
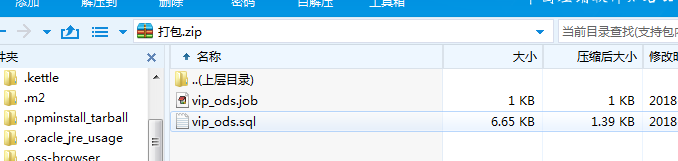
vip_ods.job:
type=command
command=hive -f vip_ods.sql
vip_ods.sql:
use hivedb;
insert overwrite table hive_tb1 SELECT id,name from user;
insert overwrite table hive_tb2 SELECT id,name from food;
以下是依赖关系阐述: 第二个job:bar.job依赖foo.job
# bar.job
type=command
dependencies=foo
command=echo bar
方式2:flow流
以下摘自官网
Creating Flows
This section covers how to create your Azkaban flows using Azkaban Flow 2.0. Flow 1.0 will be deprecated in the future.
Flow 2.0 Basics
Step 1:
Create a simple file called flow20.project. Add azkaban-flow-version to indicate this is a Flow 2.0 Azkaban project:
azkaban-flow-version: 2.0
Step 2:
Create another file called basic.flow. Add a section called nodes, which will contain all the jobs you want to run. You need to specify name and type for all the jobs. Most jobs will require the config section as well. We will talk more about it later. Below is a simple example of a command job.
nodes:
- name: jobA
type: command
config:
command: echo "This is an echoed text."
Step 3:
Select the two files you’ve already created and right click to compress them into a zip file called Archive.zip. You can also create a new directory with these two files and then cd into the new directory and compress: zip -r Archive.zip . Please do not zip the new directory directly.
Make sure you have already created a project on Azkaban ( See Create Projects ). You can then upload Archive.zip to your project through Web UI ( See Upload Projects ).
Now you can click Execute Flow to test your first Flow 2.0 Azkaban project!
Job Dependencies
Jobs can have dependencies on each other. You can use dependsOn section to list all the parent jobs. In the below example, after jobA and jobB run successfully, jobC will start to run.
nodes:
- name: jobC
type: noop
# jobC depends on jobA and jobB
dependsOn:
- jobA
- jobB - name: jobA
type: command
config:
command: echo "This is an echoed text." - name: jobB
type: command
config:
command: pwd
You can zip the new basic.flow and flow20.project again and then upload to Azkaban. Try to execute the flow and see the difference.
Job Config
Azkaban supports many job types. You just need to specify it in type, and other job-related info goes to config section in the format of key: value pairs. Here is an example for a Pig job:
nodes:
- name: pigJob
type: pig
config:
pig.script: sql/pig/script.pig
You need to write your own pig script and put it in your project zip and then specify the path for the pig.script in the config section.
Flow Config
Not only can you configure individual jobs, you can also config the flow parameters for the entire flow. Simply add a config section at the beginning of the basic.flow file. For example:
---
config:
user.to.proxy: foo
failure.emails: noreply@foo.com nodes:
- name: jobA
type: command
config:
command: echo "This is an echoed text."
When you execute the flow, the user.to.proxy and failure.emails flow parameters will apply to all jobs inside the flow.
Embedded Flows
Flows can have subflows inside the flow just like job nodes. To create embedded flows, specify the type of the node as flow. For example:
nodes:
- name: embedded_flow
type: flow
config:
prop: value
nodes:
- name: jobB
type: noop
dependsOn:
- jobA - name: jobA
type: command
config:
command: pwd
azkaban使用的更多相关文章
- 从源码看Azkaban作业流下发过程
上一篇零散地罗列了看源码时记录的一些类的信息,这篇完整介绍一个作业流在Azkaban中的执行过程,希望可以帮助刚刚接手Azkaban相关工作的开发.测试. 一.Azkaban简介 Azkaban作为开 ...
- 初识Azkaban
先说下hadoop 内置工作流的不足 (1)支持job单一 (2)硬编码 (3)无可视化 (4)无调度机制 (5)无容错机制 在这种情况下Azkaban就出现了 1)Azkaban是什么 Azkaba ...
- Azkaban 2.5.0 job type 插件安装
一.环境及软件 安装环境: 安装目录: /usr/local/ae/ankaban Hadoop 安装目录 export HADOOP_HOME=/usr/local/ae/hadoop-1.2.1 ...
- Azkaban 2.5.0 搭建
一.前言 最近试着参照官方文档搭建 Azkaban,发现文档很多地方有坑,所以在此记录一下. 二.环境及软件 安装环境: 系统环境: ubuntu-12.04.2-server-amd64 安装目录: ...
- Hadoop - Azkaban 作业调度
1.概述 在调度 Hadoop 的相关作业时,有以下几种方式: 基于 Linux 系统级别的 Crontab. Java 应用级别的 Quartz. 第三方的调度系统. 自行开发 Hadoop 应用调 ...
- hadoop工作流引擎之azkaban [转]
介绍 Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个 ...
- Azkaban遇到的坑-installation Failed.Error chunking
在使用azkaban做spark作业调度时,在上传zip包时报installation Failed.Error chunking错误,原来是于我们所编写的应用会上传到 MySQL 存储,过大的zip ...
- Oozie和Azkaban的技术选型和对比
1 两种调度工具功能对比图 下面的表格对上述2种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在区别 特性 ...
- Harry Potter and the Prisoner of Azkaban
称号:Harry Potter and the Prisoner of Azkaban 作者:J.K. Rowling 篇幅: 448页 蓝思值:880L 用时: 11天 工具: 有道词典 [ ...
- hadoop工作流引擎之azkaban
Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个可存在 ...
随机推荐
- Direct Shot Correspondence Matching
一篇BMVC18的论文,关于semantic keypoints matching.dense matching的工作,感觉比纯patch matching有意思,记录一下. 1. 摘要 提出一种针对 ...
- Faster_RCNN 2.模型准备(上)
总结自论文:Faster_RCNN,与Pytorch代码: 本文主要介绍代码第二部分:model/utils , 首先分析一些主要理论操作,然后在代码分析里详细介绍其具体实现. 一. 主要操作 1. ...
- 用css解决table文字溢出控制td显示字数
场景: 最左边这栏我不行让他换行,怎么办呢? 下面是解决办法: table{ width:100px; table-layout:fixed;/* 只有定义了表格的布局算法为fixed,下面td的定义 ...
- Unity3D之Mesh(四)绘制多边形
来自https://www.cnblogs.com/JLZT1223/p/6086191.html 1. 总的来说绘制平面的思想十分简单,就是将需要的平面拆分成几个三角形然后进行绘制就可以啦,主要的思 ...
- 题解-拉格朗日(bzoj3695变种)
Problem 在无穷大的水平面上有一个平面直角坐标系,\(N-1\)条垂直于\(x\)轴的直线将空间分为了\(N\)个区域 你被要求把\((0,0)\)处的箱子匀速推到\((x,y)\) 箱子受水平 ...
- win7经常出现“关闭xxxx前您必须关闭所有会话框”
这可能是windows的一个BUG,在没有关闭输入法的状态下它不默认你关闭了所有窗口,只要把输入法切换回默认的英文输入法就可以正常关闭了
- 【转】Java并发编程:阻塞队列
在前面几篇文章中,我们讨论了同步容器(Hashtable.Vector),也讨论了并发容器(ConcurrentHashMap.CopyOnWriteArrayList),这些工具都为我们编写多线程程 ...
- Java 处理 XML
DOM 优缺点:实现 W3C 标准,有多种编程语言支持这种解析方式,并且这种方法本身操作上简单快捷,十分易于初学者掌握.其处理方式是将 XML 整个作为类似树结构的方式读入内存中以便操作及解析,因此支 ...
- slice的部分说明
1.slice是数值的一个引用,并不会新增内存地址. 2.slice的容量和长度是两个概念,这个长度跟数组的长度是一个概念,即在内存中进行了初始化实际存在的元素的个数.何谓容量?如果通过make函数创 ...
- Chrome表单文本框自动填充黄色背景色样式
chrome表单自动填充后,input文本框的背景会变成偏黄色的,这是由于chrome会默认给自动填充的input表单加上input:-webkit-autofill私有属性,然后对其赋予以下样式: ...