Java8 Hash改进/内存改进
又开新坑o(*≧▽≦)ツ讲讲几个Java版本的特性,先开始Java8,

HashMap的改进
HashMap采用哈希算法,先使用hashCode()判断哈希值是否相同,如果相同,再使用equals(),如果再相同,则会替换掉原先的值,如不同则形成链表,后来的放前,原先的被挤到后面去,这种情况叫碰撞,我们应该要尽量避免这种情况,所以我们要通过改进hashCode()和equals(),当然我们无法完全避免这种情况。
为了不让链表太长,HashMap提供了加载因子,0.75,当元素到达哈希表的75%时,进行扩容,如果设定到100%扩容,也许算出的哈希值就只有那几个,比如长度为16的哈希表,一直只存3,5,7,8,其他的哈希值所在的位置无人问津,这样就会产生很长的链影响性能。那么哈希值可以取很小吗?也不可以,这样会频繁扩容,浪费空间。
一旦扩容,会将链表里的元素,每个重新计算新的位置,这样碰撞概率就会变低。
即使有这种扩容机制,但是碰撞依旧避免不了,所以意味着效率变低,打个比方,在1.8之前Java采用数组+链表方式,如果产生了冲突情况,比如我找哈希值为3的值,就要从数组索引值为3的链表头开始找,最糟糕的情况是找到这个链表的尾部,因此1.8将这种结构改进,变成数组+链表+红黑树 。
当链表上碰撞的个数大于8,总容量大于64,就会将链表转换成红黑树,这样的好处,除了添加,其他操作都要比链表快。

ConcurrentHashMap
1.7之前,并发级别默认为16,concurrentLevel=16;现在来介绍一下ConcurrentHashMap:
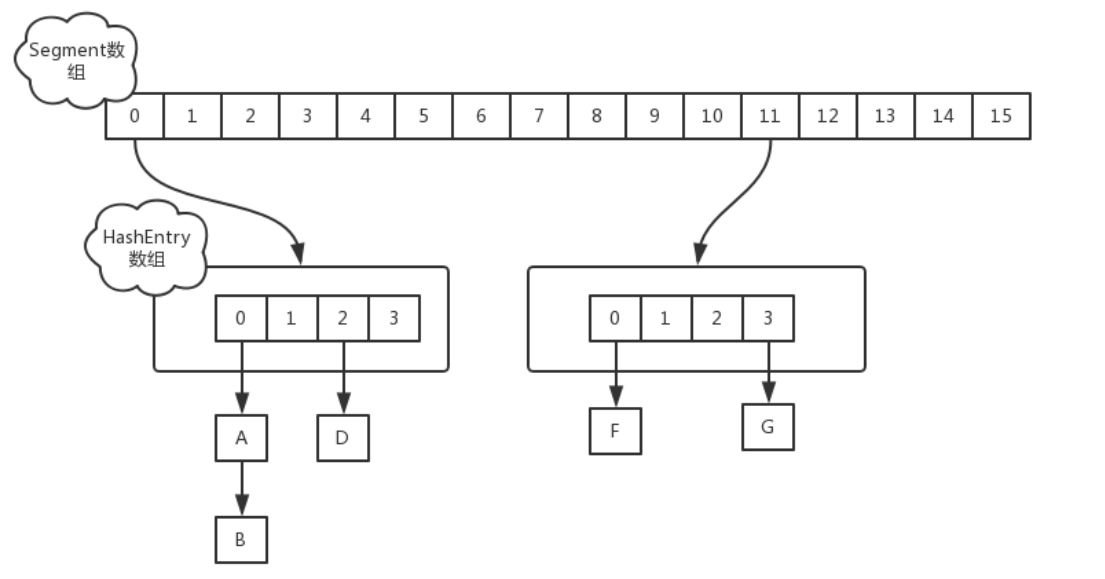
ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,主要实现原理是实现了锁分离的思路解决了多线程的安全问题,如下图所示:
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表。
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
内存改进
内存分为三大块,栈、堆、方法区,之前方法区其实属于堆的永久区的一部分,可是我们平常都把它分开画,因为JDK1.8取消这块方法区,取而代之的是MetaSpace(元空间),最大特色是它直接使用物理内存,而不是使用分配内存,这说明垃圾回收机制运行机制概率变低,效率提升。也就是说OutOfMemoryError,几乎不会发生。
既然如此,一些调优条件就无效了,比如PremGenSize、MaxPremGenSize,取而代之的是MetaspaceSize MaxMetaspaceSize

参考博文:
https://www.cnblogs.com/duanxz/p/3520829.html
https://www.jianshu.com/p/a7767e6ff2a2
Java8 Hash改进/内存改进的更多相关文章
- 为什么hash作为内存使用的经典数据结构?
听到这样说法:hash是内存中使用的经典数据结构.内存是典型的随机访问设备. 为什么hash这种数据结构很适合内存使用呢?如何理解内存是随机访问设备呢? 因为我想知其所以然,如何理解背后的原因,我花费 ...
- Java8 读写锁的改进:StampedLock(笔记)
StampedLock是Java8引入的一种新的所机制,简单的理解,可以认为它是读写锁的一个改进版本,读写锁虽然分离了读和写的功能,使得读与读之间可以完全并发,但是读和写之间依然是冲突的,读 ...
- java8新特性:内存和lambda表达式
1.内存变化 取消了永久区和方法区,取而代之的是MetaSpace元空间,即直接使用物理内存,即电脑内存8G则直接使用8g内存,而不是分配内存.因为内存改变,所以调整性能对应的调整参数也随之改变. 2 ...
- 美团分布式ID生成框架Leaf源码分析及优化改进
本文主要是对美团的分布式ID框架Leaf的原理进行介绍,针对Leaf原项目中的一些issue,对Leaf项目进行功能增强,问题修复及优化改进,改进后的项目地址在这里: Leaf项目改进计划 https ...
- 【译】ASP.NET Core 6 中的性能改进
原文 | Brennan Conroy 翻译 | 郑子铭 受到 Stephen Toub 关于 .NET 性能的博文的启发,我们正在写一篇类似的文章来强调 6.0 中对 ASP.NET Core 所做 ...
- Fedora 24最新工作站版本之四大重要改进
导读 2014年,Fedora.next倡议正式开始建立Fedora Linux未来十年的发展规划.从本质上讲,这项规划旨在进一步使Fedora不再只是一套汇聚多种开源产品的通用库(例如Debian) ...
- 改进的newlisp编译脚本,只需要配置
前面有一篇Say bye to CMake and Makefile我开始用自己编写的newlisp脚本替代CMake,今天对前面的进行改进. 改进部分是: 1. newlisp armory模块的引 ...
- 团队作业3-需求改进&原型设计
选题:实验室报修系统 实验室设备经常会发生这样或那样的故障,靠值班人员登记设备故障现象,维护人员查看故障记录,进行维修,然后登记维修过程与内容,以备日后复查,用这种方式进行设备运营管理,它仅仅起到一个 ...
- k-means算法的优缺点以及改进
大家接触的第一个聚类方法,十有八九都是K-means聚类啦.该算法十分容易理解,也很容易实现.其实几乎所有的机器学习和数据挖掘算法都有其优点和缺点.那么K-means的缺点是什么呢? 总结为下: (1 ...
随机推荐
- UVA1607-Gates(思维+二分)
Problem UVA1607-Gates Accept: 111 Submit: 767Time Limit: 3000 mSec Problem Description Input The fi ...
- 51nod 省选联测 R2
51nod 省选联测 R2 上场的题我到现在一道都没A,等哪天改完了再写题解吧,现在直接写第二场的. 第二场比第一场简单很多(然而这并不妨碍我不会做). A.抽卡大赛:http://www.51nod ...
- USB知识汇总
概述 通用串行总线(英语:Universal Serial Bus,缩写:USB)是连接计算机系统与外部设备的一种串口总线标准,也是一种输入输出接口的技术规范,被广泛地应用于个人电脑和移动设备等信息通 ...
- CF369E Valera and Queries
嘟嘟嘟 这题刚开始以为是一个简单题,后来越想越不对劲,然后就卡住了. 瞅了一眼网上的题解(真的只瞅了一眼),几个大字令人为之一振:正难则反! 没错,把点看成区间,比如2, 5, 6, 9就是[1, 1 ...
- Oracle常用性能监控语句解析
转:http://www.cnblogs.com/preftest/archive/2010/11/14/1876856.html 1.监控等待事件select event,sum(decode(wa ...
- 003_python学习之 字符串前'r'的用法
在打开文件的时候open(r'c:\....') 加r和不加''r是有区别的 'r'是防止字符转义的 如果路径中出现'\t'的话 不加r的话\t就会被转义 而加了'r'之后'\t'就能保留原有的样子 ...
- (七)JavaScript 函数
带有返回值的函数 JavaScript 变量的生存期 JavaScript 变量的生命期从它们被声明的时间开始. 局部变量会在函数运行以后被删除. 全局变量会在页面关闭后被删除.
- upper_bound
头文件: #include<algorithm> 作用: 查找第一个大于给定数的元素或位置 在从小到大的排序数组中, 1.容器 (1).返回元素 #include<cstdio> ...
- 在其他Activity中展示自定义相机拍的照片
在使用相机拍照中,我们需要当点击了确定按钮之后,拍的照片展示在其他Activity的ImageView中,代码如下: 1.首先在自定义相机的Activity中,处理点击拍照确定按钮后的逻辑功能:将图片 ...
- [intoj#7]最短距离
190227模拟 题目描述 给定一张 N 个点的有向图,点 i 到点 j 有一条长度为 i/gcd(i,j) 的边. 有个 Q 询问,每个询问包含两个数 x, y,求从点 x 出发到点 y 的最短距离 ...