Hadoop基本介绍
1、Hadoop的整体框架
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。
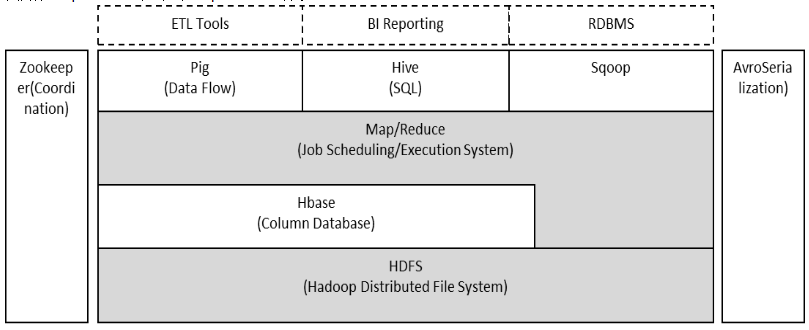
(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
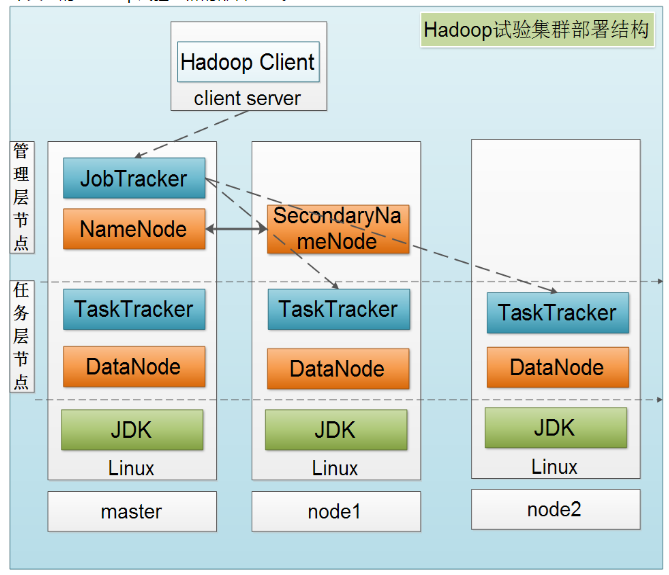
下图是一个典型的Hadoop集群的部署结构:
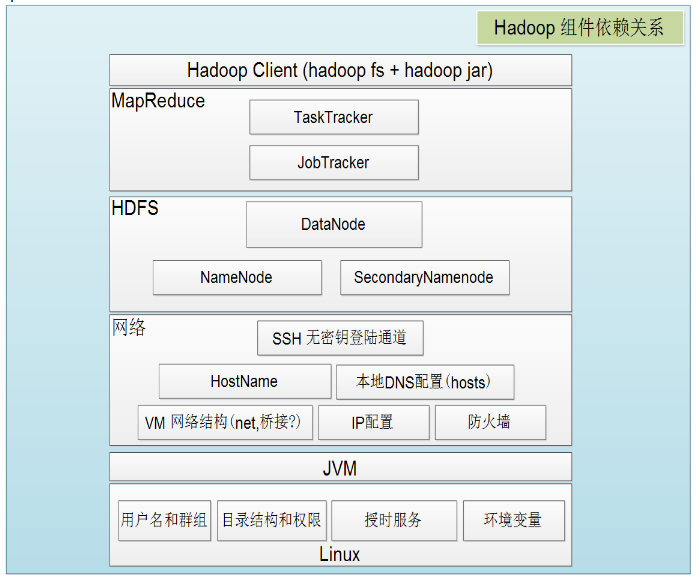
接着给出Hadoop各组件依赖共存关系:
2、Hadoop的核心设计
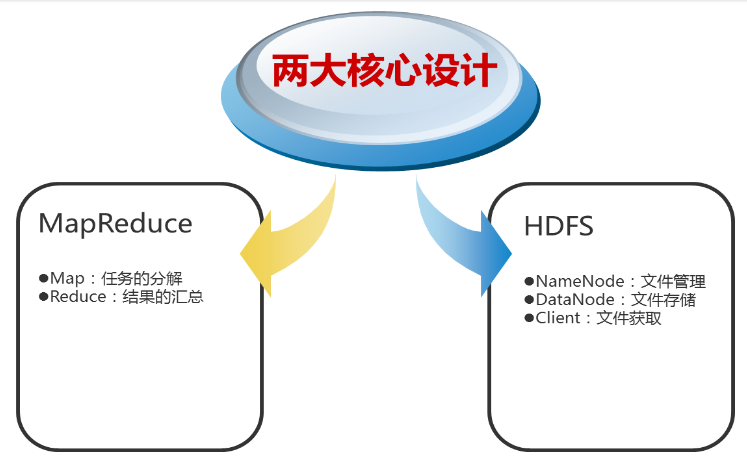
(1)HDFS
HDFS是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC上。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
HDFS的架构如图所示。HDFS架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode节点和多个DataNode节点。NameNode节点负责整个HDFS文件系统中的文件的元数据的保管和管理,集群中通常只有一台机器上运行NameNode实例,DataNode节点保存文件中的数据,集群中的机器分别运行一个DataNode实例。在HDFS中,NameNode节点被称为名称节点,DataNode节点被称为数据节点。DataNode节点通过心跳机制与NameNode节点进行定时的通信。 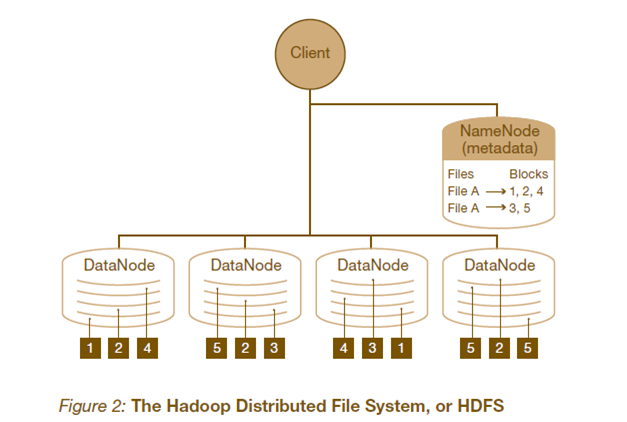
•NameNode
可以看作是分布式文件系统中的管理者,存储文件系统的meta-data,主要负责管理文件系统的命名空间,集群配置信息,存储块的复制。
•DataNode
是文件存储的基本单元。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报告给NameNode。
•Client
就是需要获取分布式文件系统文件的应用程序。
以下来说明HDFS如何进行文件的读写操作:
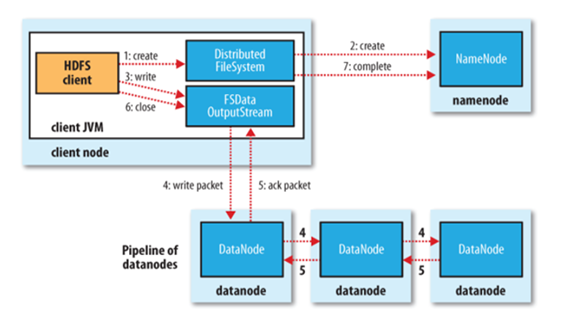
文件写入:
1. Client向NameNode发起文件写入的请求
2. NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
3. Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
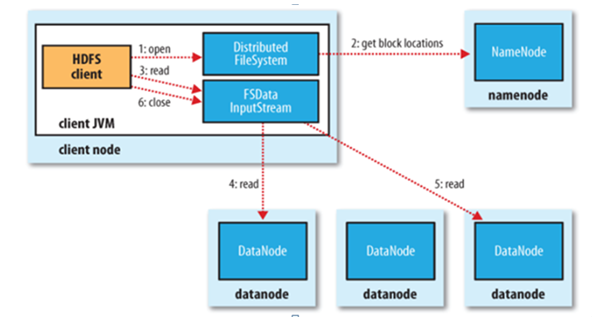
文件读取:
1. Client向NameNode发起文件读取的请求
2. NameNode返回文件存储的DataNode的信息。
3. Client读取文件信息。
(2)MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
下图是MapReduce的处理过程:
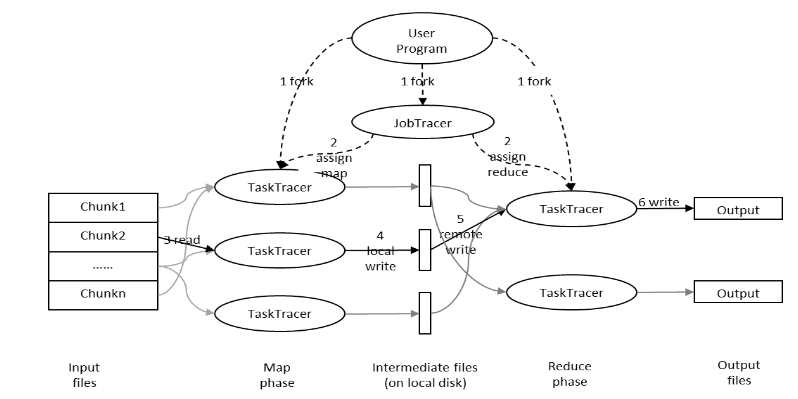
用户提交任务给JobTracer,JobTracer把对应的用户程序中的Map操作和Reduce操作映射至TaskTracer节点中;输入模块负责把输入数据分成小数据块,然后把它们传给Map节点;Map节点得到每一个key/value对,处理后产生一个或多个key/value对,然后写入文件;Reduce节点获取临时文件中的数据,对带有相同key的数据进行迭代计算,然后把终结果写入文件。
如果这样解释还是太抽象,可以通过下面一个具体的处理过程来理解:(WordCount实例)
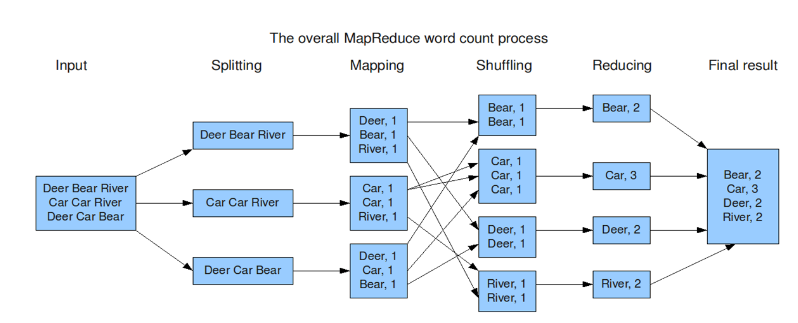
Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
map函数:接受一个键值对(key-value pair)(例如上图中的Splitting结果),产生一组中间键值对(例如上图中Mapping后的结果)。Map/Reduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值(例如上图中Shuffling后的结果),将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)(例如上图中Reduce后的结果)
但是,Map/Reduce并不是万能的,适用于Map/Reduce计算有先提条件:
(1)待处理的数据集可以分解成许多小的数据集;
(2)而且每一个小数据集都可以完全并行地进行处理;
若不满足以上两条中的任意一条,则不适合适用Map/Reduce模式。
本文转载自http://www.cnblogs.com/edisonchou/p/3485135.html
Hadoop基本介绍的更多相关文章
- hadoop生态圈介绍
原文地址:大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用户可以在不了解分 ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- Hadoop数据类型介绍
我们知道hadoop是由Java 编程写的.因此我们使用Java开发环境来操作HDFS,编写mapreduce也是很自然的事情.但是这里面hadoop却对Java数据类型进行了包装,那么hadoop的 ...
- 【转】大数据以及Hadoop相关概念介绍
原博文出自于: http://www.cnblogs.com/xdp-gacl/p/4230220.html 感谢! 一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以 ...
- 大数据以及Hadoop相关概念介绍
一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以上的数据.大数据是以TB级别起步的.在计算机当中,存放到硬盘上面的文件都会占用一定的存储空间,例如: 文件占用的存储空 ...
- Hadoop生态圈介绍及入门(转)
本帖最后由 howtodown 于 2015-4-2 23:15 编辑 问题导读 1.Hadoop生态圈介绍了哪些组件,分别都是什么? 2.大数据与Hadoop是什么关系? 本章主要内容: 理解大数据 ...
- Hadoop数据管理介绍及原理分析
Hadoop数据管理介绍及原理分析 最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个 ...
- 一 hadoop 相关介绍
hadoop 相关介绍 hadoop的首页有下面这样一段介绍.对hadoop是什么这个问题,做了简要的回答. The Apache™ Hadoop® project develops open-sou ...
- Hadoop学习总结(1)——大数据以及Hadoop相关概念介绍
一.大数据的基本概念 1.1.什么是大数据 大数据指的就是要处理的数据是TB级别以上的数据.大数据是以TB级别起步的.在计算机当中,存放到硬盘上面的文件都会占用一定的存储空间,例如: 文件占用的存储空 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
随机推荐
- 在Activity中响应ListView内部按钮的点击事件的两种方法
转载:http://www.cnblogs.com/ivan-xu/p/4124967.html 最近交流群里面有人问到一个问题:如何在Activity中响应ListView内部按钮的点击事件,不要在 ...
- HDU 5744 Keep On Movin 贪心
Keep On Movin 题目连接: http://acm.hdu.edu.cn/showproblem.php?pid=5744 Description Professor Zhang has k ...
- 用runtime来重写Coder和deCode方法 归档解档的时候使用
当我们归档自定义对象的时候,可以重写自定义Model的的encodeWithCoder和initWithCoder 开始的大概是这样的,当属性非常多的时候 这种方式就会觉得不还好 好像重复在做一样的事 ...
- Android笔记(二):savedIndstanceState 和 Bundle
savedIndstanceState savedIndstanceState 位于 Activity onCreate(Bundle savedInstanceState)方法的参数中.对这个参数的 ...
- Tomcat无法启动8005端口,提示:java.net.ConnectException: 拒绝连接 (Connection refused)
修改$JAVA_HOME/jre/lib/security/Java.security 文件中 securerandom.source 配置项: 将 securerandom.source=file: ...
- SQL Server、Oracle和MySQL中查出值为NULL的替换
参考文献: http://database.51cto.com/art/200803/67397.htm 正文 在SQL Server Oracle MySQL当数据库中查出某值为NULL怎么办? 1 ...
- 采用ASP.NET IIS 注册工具 (Aspnet_regiis.exe)对web.config实行本地加密
加密原因:我们通常将一些重要的配置信息写在Web.config里面,其中数据库链接就是这样的信息.将这些数据直接明文显示,显然不太安全. 工具: 采用ASP.NET IIS 注册工具 (Aspnet_ ...
- 打印 Go 结构体(struct)信息:fmt.Printf("%+v", user)
package main import "fmt" // 用户 type User struct { Id int Name string Age int } func main( ...
- WebService使用实例
近期刚刚開始学习使用WebService的方法进行server端数据交互,发现网上的资料不是非常全, 眼下就结合收集到的一些资料做了一个小样例和大家分享一下~ 我们在PC机器javaclient中.须 ...
- [Winform]缓存处理
摘要 在对winform做的项目优化的时候,首先想到的是对查询,并不经常变化的数据进行缓存,但对web项目来说有System.Web.Caching.Cache类进行缓存,那么winform端该如何呢 ...