第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器
1、

2、
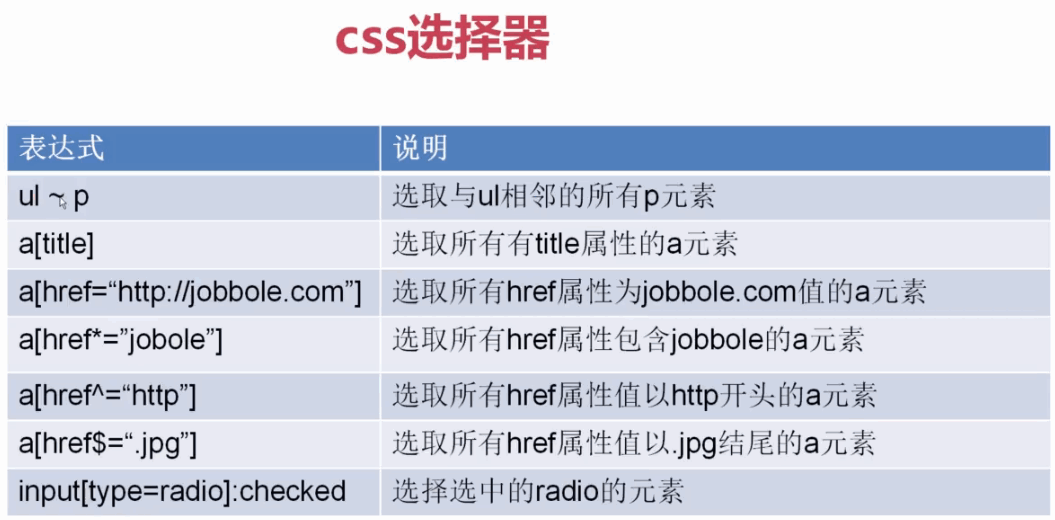
3、
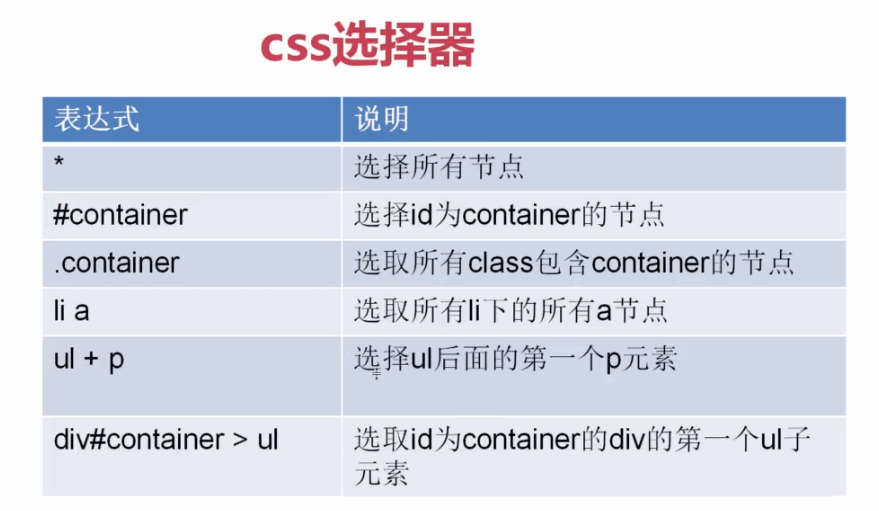
::attr()获取元素属性,css选择器
::text获取标签文本
举例:
extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如果没有数据默认是什么,一般我们设置为空字符串
extract()获取过滤后的数据,返回字符串列表
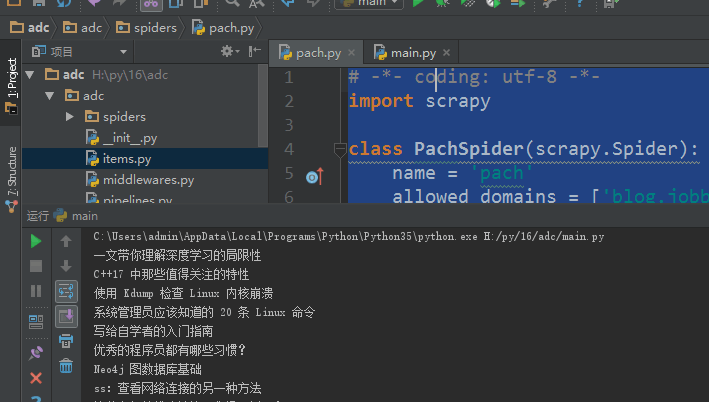
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): asd = response.css('.archive-title::text').extract() #这里也可以用extract_first('')获取返回字符串
# print(asd) for i in asd:
print(i)
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器的更多相关文章
- 十九 Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器 1. 2. 3. ::attr()获取元素属性,css选择器 ::text获取标签文本 举例: extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如 ...
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存 注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
- 三十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取 实现暂停与重启记录状态 1.首先cd进入到scrapy项目里 2.在scrapy项 ...
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- 三十四 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行一个函数 dispatcher.connect()信号分发器,第一个参数信号触发函数,第二 ...
- 三十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点:一个节点是集群中的一个服务器,由一个名字来标识,默认是一个随机的漫微角色的名字 3.分片:将索引(相当于数据库)划 ...
随机推荐
- Quartz.Net定时任务EF+MVC版的web服务
之前项目采用JAVA 的 Quartz 进行定时服调度务处理程序,目前在.NET下面使用依然可以完成相同的工作任务,其实什么语言不重要,关键是我们要学会利用语言实现价值.它是一个简单的执行任务计划的组 ...
- [AWS vs Azure] 云计算里AWS和Azure的探究(5) ——EC2和Azure VM磁盘性能分析
云计算里AWS和Azure的探究(5) ——EC2和Azure VM磁盘性能分析 在虚拟机创建完成之后,CPU和内存的配置等等基本上是一目了然的.如果不考虑显卡性能,一台机器最重要的性能瓶颈就是硬盘. ...
- (转)Maven学习-处理资源文件
转自:http://www.cnblogs.com/now-fighting/p/4888343.html 在前面两篇文章中,我们学习了Maven的基本使用方式和Maven项目的标准目录结构.接下来, ...
- EL表达式取值中文再发送请求时会乱码
问题描述: 在网站底部进行评论,点击提交按钮时,后台tomcat报错,通过火狐浏览器的firebug看到发送的POST请求体中,有一个title参数是乱码, 导致该字段超长违反了数据库字段的长度约束: ...
- 进入Linux救援(rescue)模式的四大法门
原文:http://blog.51cto.com/xxrenzhe/1272838 适用场景: 当误操作修改系统启动文件/etc/fstab, /etc/rc.d/rc.sysinit时,就会造成系统 ...
- EXCEL行倒叙
- JS实现多行文本最后是省略号紧随其后还有个超链接在同一行的需求
1.布局及样式如下图: 2.js获得上图的div对象,然后判断div对象的高度,如果大于一行的高度了表示内容有两行了,再获得span标签里面的内容并用正则将后六个字符替换成“......”这里的实现代 ...
- [转]ORA-01555错误总结(一)
原文地址:http://blog.csdn.net/sh231708/article/details/52935695 这篇文章算是undo相关问题总结的补充,因为ORA-01555错误与undo有着 ...
- APUE信号-程序汇总
APUE信号-程序汇总 近期重看APUE,发现对于非常多程序的要领还是没有全然理解.所以梳理下便于查看,并且有非常多值得思考的问题. 程序清单10- 1 捕获 SIGUSR1 和 SIGU ...
- kafka 面试题 无答案
kafka节点之间如何复制备份的? kafka消息是否会丢失?为什么? kafka最合理的配置是什么? kafka的leader选举机制是什么? kafka对硬件的配置有什么要求? kafka的消息保 ...