mysql实战优化之九:MySQL查询缓存总结
mysql Query Cache 默认为打开。从某种程度可以提高查询的效果,但是未必是最优的解决方案,如果有的大量的修改和查询时,由于修改造成的cache失效,会给服务器造成很大的开销。
mysql Query Cache 和 Oracle Query Cache 是不同的, oracle Query Cache 是缓存执行计划的,而MySql Query Cache 不缓存执行计划而是整个结果集。缓存整个结果集的好处不言而喻,但由于缓存的是结果集因此Query必须是完全一样的,这样带来的后果就是平均 Hit Rate 命中率一般不会太高。 Query Cache 对于一些小型应用程序或者数据表的数据量不大的情况下效果是最为明显的。
一、mysql Query Cache管理
1.1、query cache开关
可以通过query_cache_type来控制缓存的开关, query_cache_type的状态值有如下几种:
- 0(OFF):代表不使用缓冲;
- 1(ON):代表使用缓冲;
- 2(DEMAND):代表根据需要使用;
show variables like '%query_cache%';
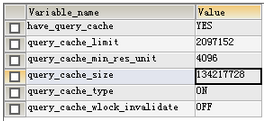
1.2、query_cache_size
默认情况下query_cache_size为0,表示为查询缓存预留的内存为0,则无法使用查询缓存。这个值必须是1024的整数倍。否则,mysql实际分配的数据会和你指定的不同。
所以我们需要设置query_cache_size的值:
SET GLOBAL query_cache_size = 134217728;
注意上面的值如果设得太小不会生效。比如我用下面的SQL设置query_cache_size大小:
SET GLOBAL query_cache_size = 4000;
query_cache_limit
mysql能够缓存的最大查询结果。如果查询结果大于这个值,则不会被缓存。缺省为1M。因为查询缓存在数据生成的时候就开始尝试缓存数据,所以只有当结果全部返回后,mysql才知道查询结果是否超出限制。
如果超出,mysql则增加状态值Qcache_not_cached,并将结果从查询缓存中删除。
如果你事先知道有很多这样的情况发生,那么建议在查询语句中加入SQL_NO_CACHE来避免查询缓存带来的额外消耗。
query_cache_wlock_invalidate
如果某个数据表被其他的连接锁住,是否还要从查询缓存中返回结果。这个参数默认是OFF,这可能在一定程度上回改变服务器的行为,因为这使得数据库可能返回其他线程锁住的数据。
如果设置为NO,则不会从缓存中读数据,但是这可能会增加锁等待。
query_cache_min_res_unit
是在4.1版本以后引入的,它指定分配缓冲区空间的最小单位,缺省为4K。检查状态值Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多,这就表明查询结果都比较小,此时需要减小 query_cache_min_res_unit。
1.3、SHOW WARNINGS;

二、mysql query cache规则
2.1、缓存条件(规则)
需要注意的是mysql query cache 是对大小写敏感的,因为Query Cache 在内存中是以 HASH 结构来进行映射,HASH 算法基础就是组成 SQL 语句的字符,所以 任何sql语句的改变重新cache,这也是项目开发中要建立sql语句书写规范的原因吧。
a) mysql query cache内容为 select 的结果集, cache 使用完整的 sql 字符串做 key, 并区分大小写,空格等。即两个sql必须完全一致才会导致cache命中。
b) prepared statement永远不会cache到结果,即使参数完全一样。据说在 5.1 之后会得到改善。
c) where条件中如包含了某些函数永远不会被cache, 比如current_date, now等。
d) date 之类的函数如果返回是以小时或天级别的,最好先算出来再传进去。
select * from foo where date1=current_date -- 不会被 cache
select * from foo where date1='2008-12-30' -- 被cache, 正确的做法
e) 太大的result set不会被cache (< query_cache_limit)
2.2、 缓存数据何时失效(invalidate)
在表的结构或数据发生改变时,查询缓存中的数据不再有效。有这些INSERT、UPDATE、 DELETE、TRUNCATE、ALTER TABLE、DROP TABLE或DROP DATABASE会导致缓存数据失效。所以查询缓存适合有大量相同查询的应用,不适合有大量数据更新的应用。
a) 一旦表数据进行任何一行的修改,基于该表相关cache立即全部失效。
b) 为什么不做聪明一点判断修改的是否cache的内容?因为分析cache内容太复杂,服务器需要追求最大的性能。
2.3、性能
a) cache 未必所有场合总是会改善性能
当有大量的查询和大量的修改时,cache机制可能会造成性能下降。因为每次修改会导致系统去做cache失效操作,造成不小开销。
另外系统cache的访问由一个单一的全局锁来控制,这时候大量>的查询将被阻塞,直至锁释放。所以不要简单认为设置cache必定会带来性能提升。
b) 大result set不会被cache的开销
太大的result set不会被cache, 但mysql预先不知道result set的长度,所以只能等到reset set在cache添加到临界值 query_cache_limit 之后才会简单的把这个cache 丢弃。这并不是一个高效的操作。如果mysql status中Qcache_not_cached太大的话, 则可对潜在的大结果集的sql显式添加 SQL_NO_CACHE 的控制。
query_cache_min_res_unit = (query_cache_size – Qcache_free_memory) / Qcache_queries_in_cache
2.4、内存池使用
mysql query cache 使用内存池技术,自己管理内存释放和分配,而不是通过操作系统。内存池使用的基本单位是变长的block, 一个result set的cache通过链表把这些block串起来。因为存放result set的时候并不知道这个resultset最终有多大。block最短长度为 query_cache_min_res_unit, resultset 的最后一个block会执行trim操作。
Query Cache 在提高数据库性能方面具有非常重要的作用。
其设定也非常简单,仅需要在配置文件写入两行: query_cache_type 和 query_cache _size,而且 MySQL 的 query cache 非常快!而且一旦命中,就直接发送给客户端,节约大量的 CPU 时间。
当然,非 SELECT 语句对缓冲是有影响的,它们可能使缓冲中的数据过期。一个 UPDATE 语句引起的部分表修改,将导致对该表所有的缓冲数据失效,这是 MySQL 为了平衡性能而没有采取的措施。因为,如果每次 UPDATE 需要检查修改的数据,然后撤出部分缓冲将导致代码的复杂度增加。
三、示例说明
3.1、如果query_cache_type为1而又不想利用查询缓存中的数据
可以用下面的SQL:
SELECT SQL_NO_CACHE * FROM my_table WHERE condition;
3.2、如果值为2,但想要使用缓存
SELECT SQL_CACHE * FROM my_table WHERE condition;
用 SHOW STATUS 可以查看缓冲的情况:
mysql> show status like 'Qca%';
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_queries_in_cache | 8 |
| Qcache_inserts | 545875 |
| Qcache_hits | 83951 |
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 2343256 |
| Qcache_free_memory | 33508248 |
| Qcache_free_blocks | 1 |
| Qcache_total_blocks | 18 |
+-------------------------+----------+
8 rows in set (0.00 sec)
如果需要计算命中率,需要知道服务器执行了多少 SELECT 语句:
mysql> show status like 'Com_sel%';
+---------------+---------+
| Variable_name | Value |
+---------------+---------+
| Com_select | 2889628 |
+---------------+---------+
1 row in set (0.01 sec)
在本例中, MySQL 命中了 2,889,628 条查询中的 83,951 条,而且 INSERT 语句只有 545,875 条。因此,它们两者的和和280万的总查询相比有很大差距,因此,我们知道本例使用的缓冲类型是 2 。
而在类型是 1 的例子中, Qcache_hits 的数值会远远大于 Com_select。
mysql实战优化之九:MySQL查询缓存总结的更多相关文章
- mysql实战优化之四:mysql索引优化
0. 使用SQL提示 用户可以使用use index.ignore index.force index等SQL提示来进行选择SQL的执行计划. 1.支持多种过滤条件 2.避免多个范围条件 应尽量避免在 ...
- mysql实战优化之一:sql优化
1.选取最适用的字段属性 MySQL 可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得 ...
- mysql实战优化之七:数据库侧配置优化
对于功能,我们可能知道必须改进什么:但对于性能问题,有时我们可能无从下手.其实,任何计算机应用系统最终队可以归结为: cpu消耗 内存使用 对磁盘,网络或其他I/O设备的输入/输出(I/O)操作. 但 ...
- mysql 开发进阶篇系列 24 查询缓存下
一. 查询缓存 1.开启缓存 [root@xuegod64 etc]# vim my.cnf 设置了缓存开启,缓存最大限制128M,重启服务后,再次查询 -- 开启查询缓存后 SHOW VARIABL ...
- mysql实战优化之三:表优化
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈.所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问. 如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理 ...
- mysql实战优化之八:关联查询优化
1. 多表连接类型 1. 笛卡尔积(交叉连接) 在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者使用',' 如: 由于其返回的结果为被连接的两个数据表的乘积,因此当有WHE ...
- MySQL事务、锁机制、查询缓存
MySQL事务 何为事务? 事务(Transaction)是访问并可能更新数据库中各种数据项的一个程序执行单元(unit). 一个事务可以是一条SQL语句,一组SQL语句或整个程序. 事务的特性: 事 ...
- mysql常见优化,更多mysql,Redis,memcached等文章
mysql常见优化 http://www.cnblogs.com/ggjucheng/archive/2012/11/07/2758058.html 更多mysql,Redis,memcached等文 ...
- Mybatis学习总结(九)——查询缓存
一.什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能.mybaits提供一级缓存和二级缓存. 1.一级缓存是sqlSession级别的缓存.在操作数据库时需要构造sqlSe ...
随机推荐
- (C/C++学习笔记) 十三. 引用
十三. 引用 ● 基本概念 引用: 就相当于为变量起了一个别名(alias), △与指针不同的是它不是一个数据类型 通过引用我们可以间接访问变量,指针也能间接访问变量,但引用在使用上相对指针更安全. ...
- DevExpress WPF入门指南:加载动画的应用
LoadingDecorator是一个容器控件用于显示 long-loading 的内容.内容还没加载完成的时候会显示一个加载指示器,加载完成后指示器消失,如下图所示: 开启LoadingDecora ...
- addslash()
php addslashes函数的作用是在预定义的字符前面加上反斜杠,这些预定义字符包括: 单引号(') 双引号(") 反斜杠(\) NULL addslashes函数经常使用在向数据库插入 ...
- Ubuntu下安装virtualbox失败解决方案
安装失败的截图: 因此使用常规方法:对依赖的两个包进行获取安装,依旧失败: 因此解决方法为在官网上下载相对应版本的virtualbox软件:下载地址为:https://www.virtualbox.o ...
- About RFC
RFC说明 Request For Comments (RFC),是一系列以编号排定的文件,几乎所有的因特网标准都收录在RFC文件之中,如果你想成为网络方面的专家,那么RFC无疑是最重要也是最经常需要 ...
- OC基础:属性.点语法.KVC 分类: ios学习 OC 2015-06-24 17:24 61人阅读 评论(0) 收藏
属性:快速生成setter和getter 属性也包括:声明和实现 1.属性的声明写在.h中 格式:@property 数据类型 变量名; 如果实例变量一致的时候,属性的声明可以合并,每一个属性之间使用 ...
- 《流畅的python》读书笔记
流畅的python 第1章 python数据模型 ---1.1 一摞Python风格的纸牌 特殊方法,即__method__,又被称为魔术方法(magic method)或者双下方法(dunder-m ...
- Vue CLI 3 配置兼容IE10
最近做了一个基于Vue的项目,需要兼容IE浏览器,目前实现了打包后可以在IE10以上运行,但是还不支持在运行时兼容IE10及以上. 安装依赖 yarn add --dev @babel/polyfil ...
- 1.1 Linux中的进程 --fork、孤儿进程、僵尸进程、文件共享分析
操作系统经典的三态如下: 1.就绪态 2.等待(阻塞) 3.运行态 其转换状态如下图所示: 操作系统内核中会维护多个队列,将不同状态的进程加入到不同的队列中,其中撤销是进程运行结束后,由内核收回. 以 ...
- Android_ndk_jni_hello-jni_hacking
/*************************************************************************** * Android_ndk_jni_hello ...