PyCharm+Eclipse共用Anaconda的数据科学环境
1.安装anaconda2
安装好之后,本地python环境就采用anaconda自带的python2.7的环境。
2.安装py4j
在本地ctrl+r打开控制台后,直接使用pip安装py4j,因为anaconda默认是安装了pip的,当然也可以使用conda安装。
安装命令:pip install py4j
如果不安装py4j可能出现的问题?
答:因为Spark的Python版本的API依赖于py4j,如果不安装运行程序会抛出如下错误。

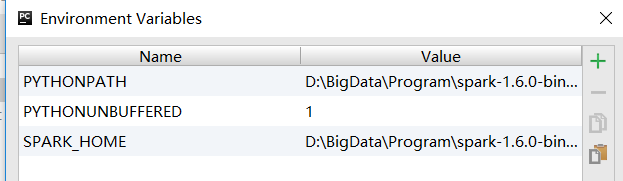
3.配置环境变量
(1).先打开Run Configurations

(2).编辑Environment variables

菜单:File-->Settings (图来源于互联网~这里我用的是python2)

(3).在Environment variables下增加spark和python的环境
增加SPARK_HOME目录与PYTHONPATH目录。
- SPARK_HOME:Spark安装目录
- PYTHONPATH:Spark安装目录下的Python目录
4.复制pyspark的包
编写Spark程序,复制pyspark的包,增加代码显示功能
为了让我们在PyCharm编写Spark程序时有代码提示和补全功能,需要将Spark的pyspark导入到Python中。在Spark的程序中有Python的包,叫做pyspark
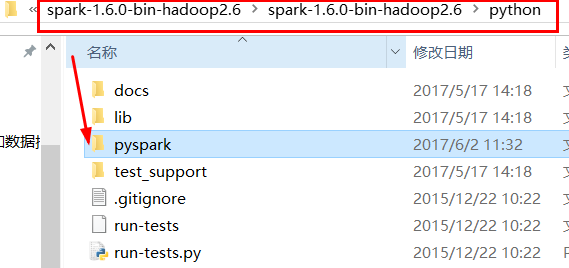
pyspark包
Python导入第三方的包也很容易,只需要把相应的模块导入到指定的文件夹就可以了。
windows中将pyspark拷贝到Python的site-packages目录下(这里使用的是anaconda)
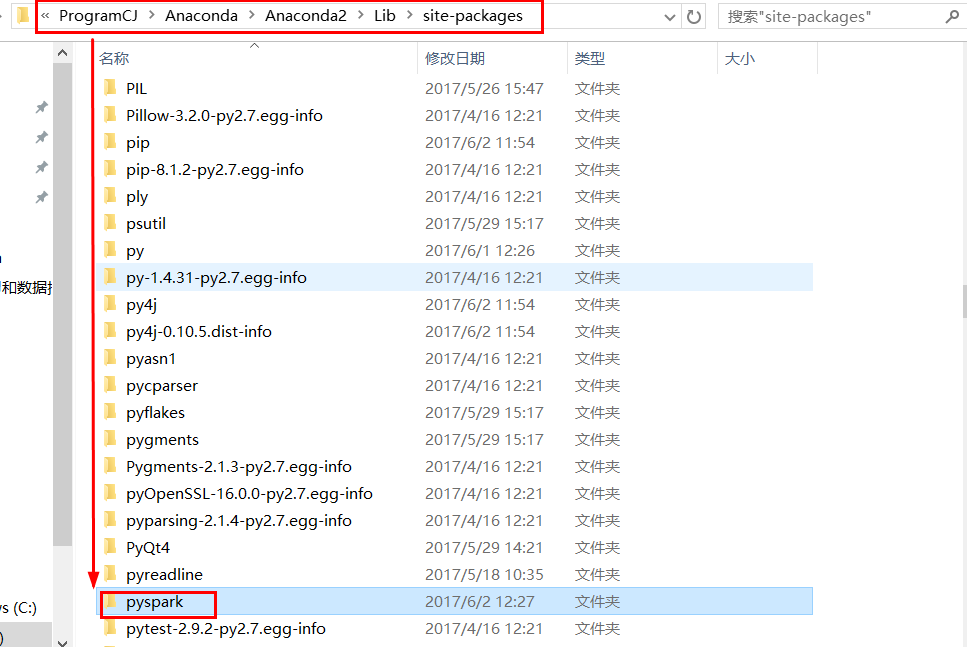
5.测试代码
import sys
from operator import add from pyspark import SparkContext
logFile = "D:\\BigData\\Workspace\\PycharmProjects\\MachineLearning1\\word.txt"
sc = SparkContext("local", "PythonWordCount")
logData = sc.textFile(logFile).cache() numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count() print("Lines with a: %i, lines with b: %i" % (numAs, numBs))

PyCharm+Eclipse共用Anaconda的数据科学环境的更多相关文章
- (数据科学学习手札81)conda+jupyter玩转数据科学环境搭建
本文示例yaml文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在使用Python进行数据分析时,很 ...
- Manjaro折腾笔记:我的数据科学环境搭建之路
ss并且开机启动 0. 安装shadowsocks sudo pip install shadowsocks 1. 建立配置文件ss.json 我的位置是:/home/ray/Documents/sh ...
- python和数据科学(Anaconda)
Python拥有着极其丰富且稳定的数据科学工具环境.遗憾的是,对不了解的人来说这个环境犹如丛林一般(cue snake joke).在这篇文章中,我会一步一步指导你怎么进入这个PyData丛林. 你可 ...
- 《Python数据科学手册》
<Python数据科学手册>[美]Jake VanderPlas著 陶俊杰译 Absorb what is useful, discard what is not, and add wh ...
- 干货!小白入门Python数据科学全教程
前言 本文讲解了从零开始学习Python数据科学的全过程,涵盖各种工具和方法 你将会学习到如何使用python做基本的数据分析 你还可以了解机器学习算法的原理和使用 说明 先说一段题外话.我是一名数据 ...
- python3 数据科学基础
第一章 1.Anaconda(最著名的python数据科学平台) 下面小伙伴们咱们来初初识下Anaconda吧 What is Anaconda???? 回答: (1).科学计算的平台 (2).有很多 ...
- Python数据科学“冷门”库
Python是一种神奇的语言.事实上,它是近几年世界上发展最快的编程语言之一,它一次又一次证明了它在开发工作和数据科学立场各行业的实用性.整个Python系统和库是对于世界各地的用户(无论是初学者或者 ...
- 9 个鲜为人知的 Python 数据科学库
除了 pandas.scikit-learn 和 matplotlib,还要学习一些用 Python 进行数据科学的新技巧. Python 是一种令人惊叹的语言.事实上,它是世界上增长最快的编程语言之 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
随机推荐
- [SLAM] 02. Some basic algorithms of 3D reconstruction
链接:http://www.zhihu.com/question/29885222/answer/100043031 三维重建 3D reconstruction的一个算法思路介绍,帮助理解 首先一切 ...
- php中实现记住密码下次自动登录的例子
这篇文章主要介绍了php中实现记住密码下次自动登录的例子,本文使用cookie实现记住密码和自动登录功能,需要的朋友可以参考下 做网站的时候经常会碰到要实现记住密码,下次自动登录,一周内免登陆,一个月 ...
- flexbox子盒子order属性
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 在eclipse中查看android源代码
自己写了一个类MainAcvitivity extends Activity, 按F12(我把转到定义改成了F12的快捷键),转到Activity的定义,弹出下面这样的界面 就是说没有找到androi ...
- python线程池(threadpool)
一.安装 pip install threadpool 二.使用介绍 (1)引入threadpool模块 (2)定义线程函数 (3)创建线程 池threadpool.ThreadPool() (4)创 ...
- Disruptor LMAX学习
http://lmax-exchange.github.io/disruptor/ http://bruce008.iteye.com/blog/1408075 http://code.google. ...
- 【译】Kafka学习之路
一直在思考写一些什么东西作为2017年开篇博客.突然看到一篇<Kafka学习之路>的博文,觉得十分应景,于是决定搬来这“他山之石”.虽然对于Kafka博客我一向坚持原创,不过这篇来自Con ...
- windows7内核分析之x86&x64第二章系统调用
windows7内核分析之x86&x64第二章系统调用 2.1内核与系统调用 上节讲到进入内核五种方式 其中一种就是 系统调用 syscall/sysenter或者int 2e(在 64 位环 ...
- C# 压缩 SharpZipLib
zip压缩与解压缩: 官方网站:http://icsharpcode.github.io/SharpZipLib/ 官网下载的资源并不是能够直接运行的,感觉是这个dll的编译,开源的 参考文档:htt ...
- 【docker】 centos7 安装docker
1.Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker 通过 uname -r 命令查看你当前的内核版本 unam ...