SQL Server 2012 自动增长列,值跳跃问题(自增增加1000)
介绍
从 SQL Server 2012 版本开始, 当SQL Server 实例重启之后,表格的自动增长列的值会发生跳跃,而具体的跳跃值的大小是根据增长列的数据类型而定的。如果数据类型是 整型(int),那么跳跃值为 1000;如果数据类型为 长整型(bigint),那么跳跃值为 10000。从我们的项目来看,这种跳跃问题是不能被接受的,尤其是展示在客户端的时候。这个奇怪的问题只在 SQL Server 2012 及更高的版本中存在,SQL Server 2012之前版本不存在此问题。
背景
几天前,我们QA组的同事提出: 我们表格的自增列的值莫名奇妙的跳跃了 10000。也就是说,我们之前表格自增列的最后一个值为 2200,而现在新增一条记录,自增列的值却直接变成了 12200。在我们的业务逻辑中像这样的情况是不允许展现在客户端的,因此我们要解决此难题。
代码使用
刚开始我们都很奇怪,这是怎么发生的?我们通常不会手动向自增列插入任何值(向自增列手动插入值是可以的),自增列的值是由数据库自行维护的。我们核心团队的一位成员开始研究这个问题并找到了答案。现在,我想详细讲解下这个问题,以及我同事找到的解决方案。
如何重现此bug
你需要安装SQL Server 2012 然后创建一个测试数据库。之后再创建一个带有自增列的表格:
create table MyTestTable(Id int Identity(1,1), Name varchar(255));
现在插入两条数据:
insert into MyTestTable(Name) values ('Mr.Tom');
insert into MyTestTable(Name) values ('Mr.Jackson');
查看结果:
SELECT Id, Name FROM MyTestTable;

此时结果和我们预期的一样。 现在重启你的 SQL Server Service。重启SQL服务有多种方法,我们这里通过 SQL Server 管理器来重启:
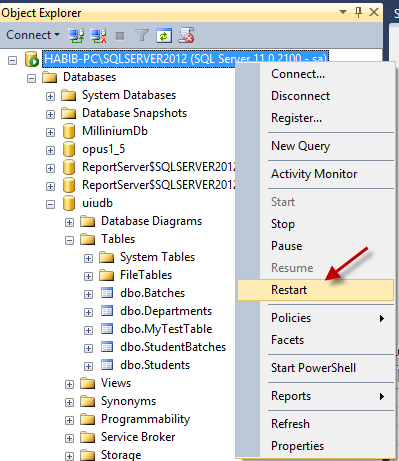
重启之后,我们向刚才的表格再插入2条数据:
insert into MyTestTable(Name) values ('Mr.Tom2');
insert into MyTestTable(Name) values ('Mr.Jackson2');
查看结果:
SELECT Id, Name FROM MyTestTable;
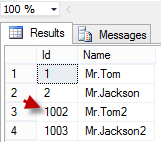
现在你看到重启SQL Server 2012 之后的结果,它的自增列的值从1002开始了。 也就是跳跃了 1000。之前说过,如果我们自增列的数据类型是 长整型(bigint)的话,它的跳跃值就将会是 10000。
它真的是个BUG吗?
微软声明这是一个功能而并非bug, 在很多场景下是很有用处的。 但是在我们的案例中,我们并不需要这样的一个功能,因为这个自增数据是要展示给客户的,客户如果看到这样跳跃性的数据,他们会感到很奇怪。并且跳跃值是根据你重启SQL Server的次数决定的。如果此数据不向客户展示,或许还可以接受。因此此功能通常只适合在内部使用。
解决方案
如果我们对微软提供的这个 “功能” 不感兴趣,我们可以通过两种途径来关闭它。
1. 使用序列 (Sequence)
2. 为SQL Server 注册启动参数 -t272
使用序列
首先,我们需要移除表格的自增列。然后创建一个不带缓存功能的序列,根据此序列插入数值。 下面是示例代码:

CREATE SEQUENCE Id_Sequence
AS INT
START WITH 1
INCREMENT BY 1
MINVALUE 0
NO MAXVALUE
NO CACHE
insert into MyTestTable values(NEXT VALUE FOR Id_Sequence, 'Mr.Tom');
insert into MyTestTable values(NEXT VALUE FOR Id_Sequence, 'Mr.Jackson');
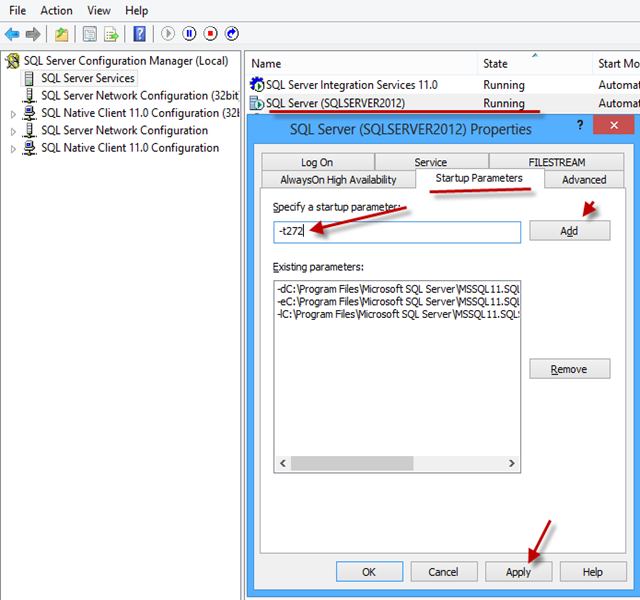
注册启动参数 -t272
打开SQL Server配置管理器。 选择 SQL Server 2012 实例,右键, 选择属性菜单。在弹出的窗口中找到启动参数,然后注册 -t272。 完成之后重启下图中的SQL Server(SQLSERVER2012), 之后进行bug重现的操作,验证问题是否已解决。
额外说明
如果在你的数据库中有很多自增列的表,并且这些表都存在数值跳跃问题,那么采用第2种方案更好一些。因为它非常简单,并且作用域是服务器级别的。采用第2种解决方案将会影响此服务实例上的所有数据库。
SQL Server 2012 自动增长列,值跳跃问题(自增增加1000)的更多相关文章
- SQL Server 2012 自动增长列,值跳跃问题
介绍 从 SQL Server 2012 版本开始, 当SQL Server 实例重启之后,表格的自动增长列的值会发生跳跃,而具体的跳跃值的大小是根据增长列的数据类型而定的.如果数据类型是 整型(in ...
- SQL SERVER重置自动编号列(标识列)
两种方法: 一种是用Truncate TRUNCATE TABLE name 可以删除表内所有值并重置标识值 二是用DBCC CHECKIDENT DBCC CHECKIDENT ('table_na ...
- SQL Server 文件自动增长那些事
方法 1. 把文件的增长设置为按照固定大小增长. 如filegrowth = 100MB; ------------------------------------------------------ ...
- SQL Server 2012自动备份
SQL 2012和2008一样,都可以做维护计划,来对数据库进行自动的备份. 现在做这样一个数据库维护的计划,每天0点对数据库进行差异备份,每周日0点对数据库进行完全备份,并且每天晚上10点删除一次过 ...
- sql server中将自增长列归零
一个项目完成后数据库中会有很多无用的测试数据,可以使用delete * 将数据全部删除,但自增长列(一般是主键)基数不会归零,使用TRUNCATE函数可以将表中数据全部删除,并且将自增长列基数归零.一 ...
- Sql Server实现自动增长
在学习中遇到这个问题 数据库里有编号字段 BH00001 BH00002 BH00003 BH00004 如何实现自动增长 --下面的代码生成长度为8的编号,编号以BH开头,其余6位为流水号. --得 ...
- sql server生成自动增长的字母数字字符串
在开发的过程中,我们经常会遇到要生成一些固定格式字符串,例如“BX201903150001”,结构为:BX+日期+N位序号,类似这种的字符串我们很难生成,在这里我们借助一个存储过程来实现这个功能. 1 ...
- 使用sql语句创建修改SQL Server标识列(即自动增长列)
一.标识列的定义以及特点SQL Server中的标识列又称标识符列,习惯上又叫自增列.该种列具有以下三种特点:1.列的数据类型为不带小数的数值类型2.在进行插入(Insert)操作时,该列的值是由系统 ...
- SQL获取刚插入的记录的自动增长列ID的值
假设表结构如下: CREATE TABLE TestTable ( id int identity, CreatedDate datetime ) SQL2005获得新增行的自动增长列的语句如下: i ...
随机推荐
- python selenium 报错unknown error: cannot focus element 解决办法
登录框由于js限制,定位到元素后无法sendkey ,sendky报错如下: selenium.common.exceptions.WebDriverException: Message: unkno ...
- Linux 密码过期(WARNING:Your password has expired )
最近遇到两次这个问题,我们公司用的是开源的堡垒机Jumpserver但是最近有两个同学遇到了 WARNING:Your password has expired 第一次遇到这个问题也没有往深了去查,当 ...
- NSString和NSMutablestring,copy和strong(转载)
1.http://www.cocoachina.com/ios/20150512/11805.html 2.http://blog.csdn.net/winzlee/article/details/5 ...
- 给Java开发人员的Play Framework(2.4)介绍 Part1:Play的优缺点以及适用场景
1. 关于这篇系列 这篇系列不是Play框架的Hello World,由于这样的文章网上已经有非常多. 这篇系列会首先结合实际代码介绍Play的特点以及适用场景.然后会有几篇文章介绍Play与Spri ...
- [Leet Code]Path Sum II
此题如果 #1 和 #4 判断分支交换,大集合就会超时(因为每次对于非叶子节点都要判断是不是叶子节点).可见,有时候if else判断语句也会对于运行时间有较大的影响. import java.uti ...
- Viewpager 的相关总结
1.修改切换item的时间 public class FixedSpeedScroller extends Scroller { ; public FixedSpeedScroller(Context ...
- vue.js 首屏优化
我们以 vue-cli 工具为例,使用 vue-router 搭建SPA应用,UI框架选用 element-ui , ajax方案选用 axios, 并引入 vuex ,使用 vuex-router- ...
- JAVA中INSTANCEOF关键字的用法总结
https://www.cnblogs.com/jay36/p/7519145.html https://www.cnblogs.com/zjxynq/p/5882756.html https://b ...
- FFmpeg(7)-av_read_frame()读取帧数据AVPacket和av_seek_frame()改变播放进度
一.av_read_frame() 该函数用于读取具体的音/视频帧数据 int av_read_frame(AVFormatContext *s, AVPacket *pkt); 参数说明: AVFo ...
- django rest_framework入门三-Requests和Responses
这一节,我们介绍rest_framework的Requests和Responses对象,来替代django.http的HttpRequest和HttpResponse对象 1.Requests和Res ...