Selenium2+python自动化31-生成测试报告【转载】
前言
最近小伙伴们总有一些测试报告的问题,网上的一些资料生成报告的方法,我试了都不行,完全生成不了,不知道他们是怎么生成的,同样的代码,有待研究。
今天小编写一下可以生成测试报告的方法。个人觉得也是最方便,最省事的,可批量执行测试用例,也比较容易理解的方法。另外一种用遍历的方法,小编在这边就不介绍了,有点麻烦,而且不可批量执行测试用例。
一、下载HTMLTestRunner.py
HTMLTestRunner 是 Python 标准库的 unittest 模块的一个扩展。它生成易于使用的 HTML 测试报告。HTMLTestRunner 是在 BSD 许可证下发布。
下载 地址:http://tungwaiyip.info/software/HTMLTestRunner.html(或者在我们群里下载)
Windows :将下载的文件放入...\Python27\Lib 目录下
二、生成报告
下面还是以百度为例,baidu.py代码如下:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchAttributeException
import unittest,time,re
import HTMLTestRunner
class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.verificationErrors = []
self.accept_next_alert = True
def test_baidu_search(self):
u"""百度搜索"""
driver = self.driver
driver.get(self.base_url + '/')
driver.find_element_by_id("kw").send_keys("selenium webdriver")
driver.find_element_by_id("su").click()
time.sleep(2)
driver.close()
def test_baidu_set(self):
u"""百度设置"""
driver = self.driver
#进入搜索设置页
driver.get(self.base_url + '/gaoji/preferences.html')
#设置每页搜索结果为 20 条
m=driver.find_element_by_name("NR")
m.find_element_by_xpath("//option[@value='20']").click()
time.sleep(2)
#保存设置的信息
driver.find_element_by_xpath("/html/body/form/div/input").click()
time.sleep(2)
driver.switch_to_alert().accept()
def tearDown(self):
self.driver.quit()
self.assertEqual([],self.verificationErrors)
if __name__ == "__main__":
unittest.main()
下面我们在上面baidu.py的目录下新建一个.py,用来执行测试用例集和生成测试报告。
代码如下:
#coding=utf-8
import unittest
#这里需要导入测试文件
import baidu
import HTMLTestRunner
testunit=unittest.TestSuite()
#将测试用例加入到测试容器(套件)中
testunit.addTest(unittest.makeSuite(baidu.Baidu)) #baidu.Baidu中的baidu为用例所在的.py文件的名称,Baidu为测试用例集的名称
#定义个报告存放路径,支持相对路径。
filename= "D:\\python\\report\\"+ u"测试报告正常" +"result.html"
fp = open(filename,"wb")
runner =HTMLTestRunner.HTMLTestRunner(stream=fp,title=u'测试报告',description=u'用例执行情况:')
#执行测试用例
runner.run(testunit)
执行完毕后,进入报告存放的路径,打开后如图:
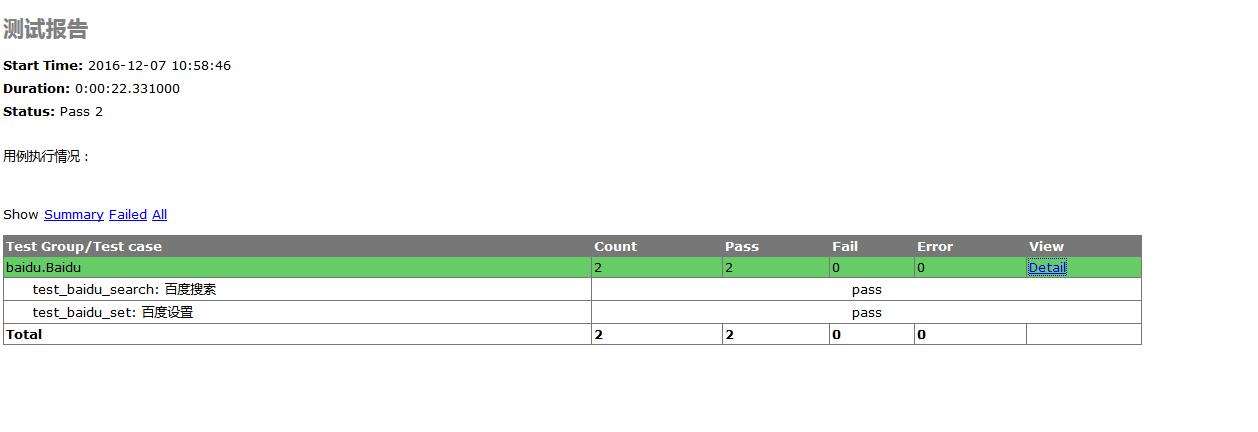
定义报告的路径还有一种方法也可以的,生成的html文件直接在该.py文件目录下,fp = file("my_report.html", "wb"),小伙伴们可以尝试下。
Selenium2+python自动化31-生成测试报告【转载】的更多相关文章
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)【转载】
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Selenium2+python自动化28-table定位【转载】
前言 在web页面中经常会遇到table表格,特别是后台操作页面比较常见.本篇详细讲解table表格如何定位. 一.认识table 1.首先看下table长什么样,如下图,这种网状表格的都是table ...
- Selenium2+python自动化7-xpath定位【转载】
前言 在上一篇简单的介绍了用工具查看目标元素的xpath地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到.这个时候就需要自己手动的去写xpath了,这一篇详细讲解xpath的一些语法. ...
- Selenium2+python自动化31-生成测试报告
前言 最近小伙伴们总有一些测试报告的问题,网上的一些资料生成报告的方法,我试了都不行,完全生成不了,不知道他们是怎么生成的,同样的代码,有待研究. 今天小编写一下可以生成测试报告的方法.个人觉得也是最 ...
- Python自动化 unittest生成测试报告(HTMLTestRunner)03
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Selenium3+python自动化011-unittest生成测试报告(HTMLTestRunner)
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Selenium2+python自动化69-PhantomJS使用【转载】
前言 PhantomJS是一个没有界面的浏览器,本质上是它其实也就是一个浏览器,只是不在界面上展示. PhantomJS非常适合爬虫方面,很多玩爬虫的都喜欢用这个浏览器. 一.PhantomJS环境准 ...
- Selenium2+python自动化74-jquery定位【转载】
转至博客:上海-悠悠 前言 元素定位可以说是学自动化的小伙伴遇到的一道门槛,学会了定位也就打通了任督二脉,前面分享过selenium的18般武艺,再加上五种js的定位大法. 这些还不够的话,今天再分享 ...
随机推荐
- NO10——各种欧几里得
int gcd(int n,int m)//n>m { //最大公约数 int r; while(m) { r = n%m; n = m; m = r; } return n; } int kg ...
- [转]如何清空Chrome缓存和Cookie
当您使用浏览器(例如 Chrome)时,浏览器会将网站中的一些信息保存在其缓存和 Cookie 中. 清除这些内容可以解决某些问题,例如网站上的加载或格式设置问题. 在 Chrome 中 在计算机上打 ...
- (转载)MYSQL千万级数据量的优化方法积累
转载自:http://blog.sina.com.cn/s/blog_85ead02a0101csci.html MYSQL千万级数据量的优化方法积累 1.分库分表 很明显,一个主表(也就是很重要的表 ...
- 最短路径——Floyd算法(含证明)
通过dij,ford,spfa等算法可以快速的得到单源点的最短路径,如果想要得到图中任意两点之间的最短路径,当然可以选择做n遍的dij或是ford,但还有一个思维量较小的选择,就是floyd算法. 多 ...
- bbbbbeta
about beta 写在开头:(小声bb,无任何专业知识) 好了正文开始了 = = beta冲刺对于来说可能是让我觉得非常有成就感的叭,相比于alpha,每天都能写代码的感觉真好鸭(认真脸)(虽然天 ...
- Angular 2018 All in One
Angular 2018 https://cli.angular.io/ v7.0.6 https://angular.io/ https://angular.cn/ v7.0.4 $ npm i - ...
- 【python】Python中给List添加元素的4种方法分享
List 是 Python 中常用的数据类型,它一个有序集合,即其中的元素始终保持着初始时的定义的顺序(除非你对它们进行排序或其他修改操作). 在Python中,向List添加元素,方法有如下4种方法 ...
- 第一个贴上XMT标签的Hadoop程序
距离老板留给我并行化做属性约简的任务开始到今天,已是一周有余,期间经历过各种呕心沥血,通宵达旦,终于运行出了一个结果.其中在配置过程中,浪费了爷大量的时间,有时回想自己上个周干的事情,会觉得分明的本末 ...
- 【题解】POI2014FAR-FarmCraft
这题首先手玩一下一下数据,写出每个节点修建软件所需要的时间和到达它的时间戳(第一次到达它的时间),不难发现实际上就是要最小化这两者之和.然后就想到:一棵子树内,时间戳必然是连续的一段区间,而如果将访问 ...
- POJ3294 Life Forms 【后缀数组】
生命形式 时间限制: 5000MS 内存限制: 65536K 提交总数: 16660 接受: 4910 描述 你可能想知道为什么大多数外星人的生命形式与人类相似,不同的是表面特征,如身高,肤色 ...