(数据科学学习手札16)K-modes聚类法的简介&Python与R的实现
我们之前经常提起的K-means算法虽然比较经典,但其有不少的局限,为了改变K-means对异常值的敏感情况,我们介绍了K-medoids算法,而为了解决K-means只能处理数值型数据的情况,本篇便对K-means的变种算法——K-modes进行简介及Python、R的实现:
K-modes是数据挖掘中针对分类属性型数据进行聚类采用的方法,其算法思想比较简单,时间复杂度也比K-means、K-medoids低,大致思想如下:
假设有N个样本,共有M个属性,均为离散的,对于聚类数目标K:
step1:随机确定k个聚类中心C1,C2...Ck,Ci是长度为M的向量,Ci=[C1i,C2i,...,CMi]
step2:对于样本xj(j=1,2,...,N),分别比较其与k个中心之间的距离(这里的距离为不同属性值的个数,假如x1=[1,2,1,3],C1=[1,2,3,4]x1=[1,2,1,3],C1=[1,2,3,4],那么x1与C1之间的距离为2)
step3:将xj划分到距离最小的簇,在全部的样本都被划分完毕之后,重新确定簇中心,向量Ci中的每一个分量都更新为簇i中的众数
step4:重复步骤二和三,直到总距离(各个簇中样本与各自簇中心距离之和)不再降低,返回最后的聚类结果
下面对一个简单的小例子在Python与R中的K-modes聚类过程为例进行说明:
Python
我们使用的是第三方包kmodes中的方法,具体过程如下:
import numpy as np
from kmodes import kmodes '''生成互相无交集的离散属性样本集'''
data1 = np.random.randint(1,6,(10000,10))
data2 = np.random.randint(6,12,(10000,10)) data = np.concatenate((data1,data2)) '''进行K-modes聚类'''
km = kmodes.KModes(n_clusters=2)
clusters = km.fit_predict(data) '''计算正确归类率'''
score = np.sum(clusters[:int(len(clusters)/2)])+(len(clusters)/2-np.sum(clusters[int(len(clusters)/2):]))
score = score/len(clusters)
if score >= 0.5:
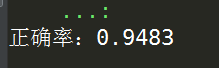
print('正确率:'+ str(score))
else:
print('正确率:'+ str(1-score))
R
在R中进行K-modes聚类的包为klaR,用其中的kmodes(data,modes=k)进行聚类,其中modes为指定的类数目k,具体示例如下:
> library(klaR)
>
> data1 <- matrix(sample(1:3,size=1000,replace = T),nrow=100)
> data2 <- matrix(sample(4:6,size=1000,replace = T),nrow=100)
> data <- rbind(data1,data2)
>
> km <- kmodes(data, modes=2)
> s <- km$cluster
> if(mean(s[1:100] < 1.5)){
+ score <- sum(s[1:100])+sum(s[101:200]-1)
+ score <- score/200
+ cat('正确率:',score)
+ }else{
+ score <- sum(s[1:100]-1)+sum(s[101:200])
+ score <- score/200
+ cat('正确率:',round(score,3))
+ }
正确率: 0.995
以上便是关于K-modes聚类的简要介绍,如有错误望指出。
(数据科学学习手札16)K-modes聚类法的简介&Python与R的实现的更多相关文章
- (数据科学学习手札13)K-medoids聚类算法原理简介&Python与R的实现
前几篇我们较为详细地介绍了K-means聚类法的实现方法和具体实战,这种方法虽然快速高效,是大规模数据聚类分析中首选的方法,但是它也有一些短板,比如在数据集中有脏数据时,由于其对每一个类的准则函数为平 ...
- (数据科学学习手札17)线性判别分析的原理简介&Python与R实现
之前数篇博客我们比较了几种具有代表性的聚类算法,但现实工作中,最多的问题是分类与定性预测,即通过基于已标注类型的数据的各显著特征值,通过大量样本训练出的模型,来对新出现的样本进行分类,这也是机器学习中 ...
- (数据科学学习手札14)Mean-Shift聚类法简单介绍及Python实现
不管之前介绍的K-means还是K-medoids聚类,都得事先确定聚类簇的个数,而且肘部法则也并不是万能的,总会遇到难以抉择的情况,而本篇将要介绍的Mean-Shift聚类法就可以自动确定k的个数, ...
- (数据科学学习手札11)K-means聚类法的原理简介&Python与R实现
kmeans法(K均值法)是麦奎因提出的,这种算法的基本思想是将每一个样本分配给最靠近中心(均值)的类中,具体的算法至少包括以下三个步骤: 1.将所有的样品分成k个初始类: 2.通过欧氏距离将某个样品 ...
- (数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)
聚类分析是数据挖掘方法中应用非常广泛的一项,而聚类分析根据其大体方法的不同又分为系统聚类和快速聚类,其中系统聚类的优点是可以很直观的得到聚类数不同时具体类中包括了哪些样本,而Python和R中都有直接 ...
- (数据科学学习手札23)决策树分类原理详解&Python与R实现
作为机器学习中可解释性非常好的一种算法,决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方 ...
- (数据科学学习手札34)多层感知机原理详解&Python与R实现
一.简介 机器学习分为很多个领域,其中的连接主义指的就是以神经元(neuron)为基本结构的各式各样的神经网络,规范的定义是:由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系 ...
- (数据科学学习手札15)DBSCAN密度聚类法原理简介&Python与R的实现
DBSCAN算法是一种很典型的密度聚类法,它与K-means等只能对凸样本集进行聚类的算法不同,它也可以处理非凸集. 关于DBSCAN算法的原理,笔者觉得下面这篇写的甚是清楚练达,推荐大家阅读: ht ...
- (数据科学学习手札10)系统聚类实战(基于R)
上一篇我们较为系统地介绍了Python与R在系统聚类上的方法和不同,明白人都能看出来用R进行系统聚类比Python要方便不少,但是光介绍方法是没用的,要经过实战来强化学习的过程,本文就基于R对2016 ...
随机推荐
- Oracle Dataguard 基本原理
转载-http://blog.sina.com.cn/s/blog_7c5a82970101prcx.html 1.DATAGUARD原理 DATAGUARD是通过建立一个PRIMARY和STANDB ...
- C4C Cloud Application Studio做ABSL开发的一些性能方面的最佳实践
Stefan Hagen在博文SAP Cloud Application Studio Performance Best Practices里介绍了在C4C里使用Cloud Application S ...
- Jmeter启动报错:unable to access jarfile ApacheJmeter.jar error 原因:下载的src包没有这个jar包,需下载binary包
安装好jdk并配置了环境变量,下载Jmeter包解压启动jemter.bat提示 unable to access jarfile ApacheJmeter.jar error 原因: 从官网 htt ...
- Python语言程序设计基础(6)—— 组合数据类型
tuple 元组(创建后不能修改) tuple = "cat","dog","tiger","human" print( ...
- Class<T>和Class<?>区别
Class<T>在实例化的时候,T要替换成具体类Class<?>它是个通配泛型,?可以代表任何类型
- js CheckBox只读
checkbox没有readOnly属性 所以我们要设置CHeckbox是只读的话就要设置其onclick方法并返回false checkbox.onclick=function(){return f ...
- Android学习笔记_JNI_c调用java代码
1.编写native方法(java2c)和非native方法(c2java): package com.example.provider; public class CallbackJava { // ...
- TDD: 解除依赖
1 A类依赖B 类,可以把B类提取成IB接口,解除AB 之间的依赖关系. 通过创建实现了IB接口的BStub 装代码,可以模拟B类进行测试. 这是针对接口编程的典型.适合构造代价大,变化多的情况.应 ...
- JavaScript:改变 HTML 样式
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- 缓存&跨域
一.前端本地缓存的几种实现方式了解一下 缓存的几种实现方式 序号 名称 参考资料 1 serviceWorker https://blog.csdn.net/ztguang/article/deta ...