Hive(四)Hive的3种连接方式与DbVisualizer连接Hive
一、CLI连接
进入到 bin 目录下,直接输入命令:
[root@node21 ~]# hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive-2.3./lib/log4j-slf4j-impl-2.6..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Logging initialized using configuration in file:/opt/module/hive-2.3./conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive .X rel
eases.hive (default)> show databases;
OK
database_name
default
Time taken: 10.52 seconds, Fetched: row(s)
hive (default)> quit;
启动成功的话如上所示,接下来便可以做 hive 相关操作
补充:
1、上面的 hive 命令相当于在启动的时候执行:hive --service cli
2、使用 hive --help,可以查看 hive 命令可以启动那些服务
3、通过 hive --service serviceName --help 可以查看某个具体命令的使用方式
二、HiveServer2/beeline
在现在使用的最新的 hive-2.3.3 版本中:都需要对 hadoop 集群做如下改变,否则无法使用
1、修改 hadoop 集群的 hdfs-site.xml 配置文件
加入一条配置信息,表示启用 webhdfs
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
2、修改 hadoop 集群的 core-site.xml 配置文件
加入两条配置信息:表示设置 hadoop 的代理用户
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
以上操作做好了之后(最好重启一下HDFS集群),请继续做如下两步:
第一步:先启动 hiveserver2 服务
启动方式,(假如是在 node22 上):
启动为前台:hiveserver2
[root@node22 ~]# hiveserver2
-- ::: Starting HiveServer2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hive-2.3./lib/log4j-slf4j-impl-2.6..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
启动会多出一个RunJar的进程
启动为后台:
nohup hiveserver2 >/opt/module/hive-2.3./logs/hiveserver.log >/opt/module/hive-2.3./logs/hiveserver.log &
或者:nohup hiveserver2 >/dev/null >/dev/null &
或者:nohup hiveserver2 >/dev/null >& &
以上 3 个命令是等价的,第一个表示记录日志,第二个和第三个表示不记录日志
命令中的 1 和 2 的意义分别是:
1:表示标准日志输出
2:表示错误日志输出 如果我没有配置日志的输出路径,日志会生成在当前工作目录,默认的日志名称叫做: nohup.xxx

PS:nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束, 那么可以使用 nohup 命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。 nohup 就是不挂起的意思(no hang up)。 该命令的一般形式为:nohup command &
第二步:然后启动 beeline 客户端去连接:
执行命令:
[root@node23 ~]$ beeline -u jdbc:hive2//node23:10000 -n root
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
scan complete in 1ms
scan complete in 2374ms
No known driver to handle "jdbc:hive2//node23:10000"
Beeline version 2.3.3 by Apache Hive
beeline>
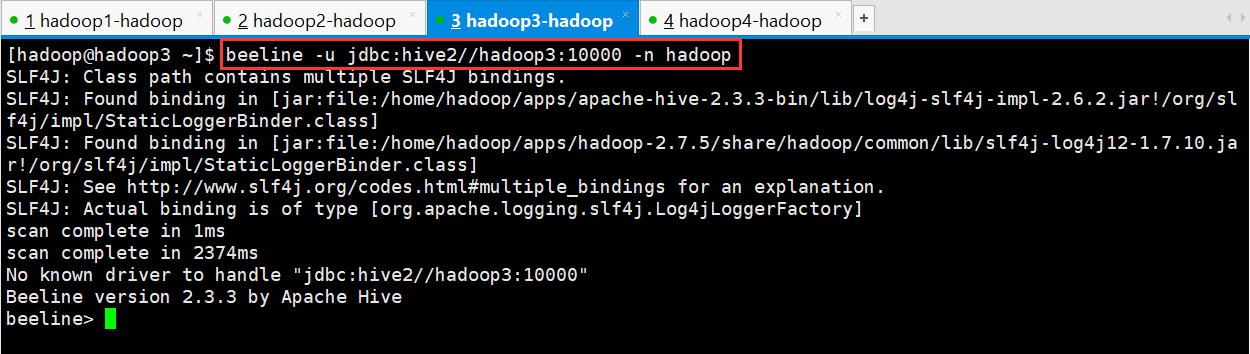
-u : 指定元数据库的链接信息
-n : 指定用户名和密码
另外还有一种方式也可以去连接:
先执行 beeline
然后按图所示输入:!connect jdbc:hive2://hadoop02:10000
按回车,然后输入用户名,这个 用户名就是安装 hadoop 集群的用户名
[hadoop@hadoop3 ~]$ beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.3 by Apache Hive
beeline> !connect jdbc:hive2://hadoop3:10000
Connecting to jdbc:hive2://hadoop3:10000
Enter username for jdbc:hive2://hadoop3:10000: hadoop
Enter password for jdbc:hive2://hadoop3:10000: ******
Connected to: Apache Hive (version 2.3.3)
Driver: Hive JDBC (version 2.3.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop3:10000>
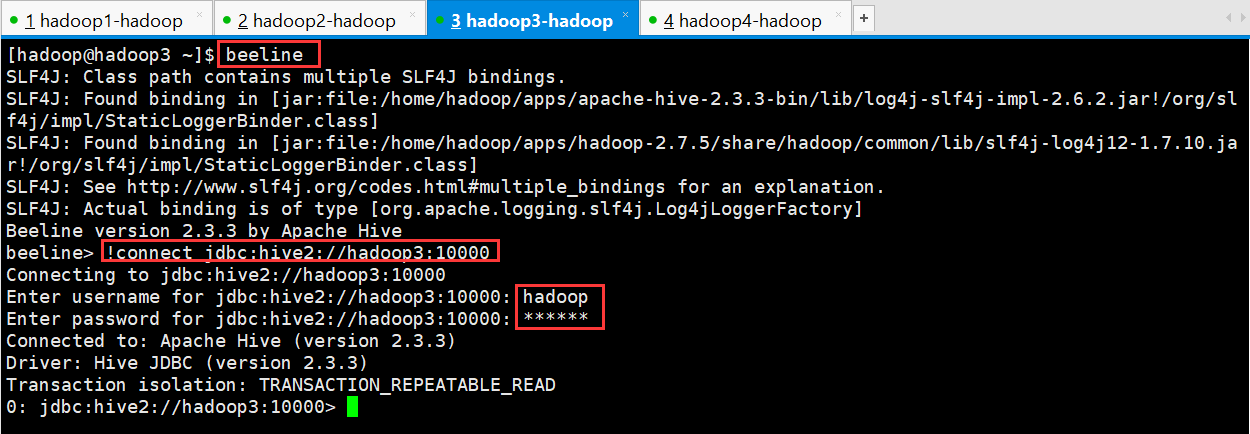
接下来便可以做 hive 操作
三、Web UI
1、 下载对应版本的 src 包:apache-hive-2.3.2-src.tar.gz
2、 上传,解压
tar -zxvf apache-hive-2.3.2-src.tar.gz
3、 然后进入目录${HIVE_SRC_HOME}/hwi/web,执行打包命令:
jar -cvf hive-hwi-2.3.2.war *
在当前目录会生成一个 hive-hwi-2.3.2.war
4、 得到 hive-hwi-2.3.2.war 文件,复制到 hive 下的 lib 目录中
cp hive-hwi-2.3.2.war ${HIVE_HOME}/lib/
5、 修改配置文件 hive-site.xml
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
<description>监听的地址</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>监听的端口号</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-2.3.2.war</value>
<description>war 包所在的地址</description>
</property>
6、 复制所需 jar 包
1、cp ${JAVA_HOME}/lib/tools.jar ${HIVE_HOME}/lib
2、再寻找三个 jar 包,都放入${HIVE_HOME}/lib 目录:
commons-el-1.0.jar
jasper-compiler-5.5.23.jar
jasper-runtime-5.5.23.jar
不然启动 hwi 服务的时候会报错。
7、 安装 ant
1、 上传 ant 包:apache-ant-1.9.4-bin.tar.gz
2、 解压 tar -zxvf apache-ant-1.9.4-bin.tar.gz -C ~/apps/
3、 配置环境变量 vi /etc/profile 在最后增加两行: export ANT_HOME=/home/hadoop/apps/apache-ant-1.9.4 export PATH=$PATH:$ANT_HOME/bin 配置完环境变量别忘记执行:source /etc/profile
4、 验证是否安装成功

8、上面的步骤都配置完,基本就大功告成了。进入${HIVE_HOME}/bin 目录:
${HIVE_HOME}/bin/hive --service hwi
或者让在后台运行: nohup bin/hive --service hwi > /dev/null 2> /dev/null &
9、 前面配置了端口号为 9999,所以这里直接在浏览器中输入: hadoop02:9999/hwi
10、至此大功告成

一、安装DbVisualizer
也可以从网上下载破解版程序,此处使用的版本是DbVisualizer 9.1.1
具体的安装步骤可以百度,或是修改安装目录之后默认安装就可以
二、配置DbVisualizer里的hive jdbc
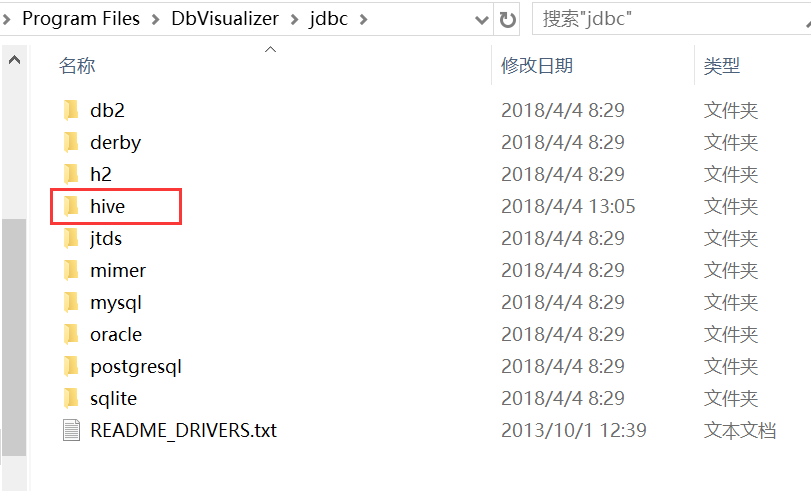
1、在DbVisualizer的安装目录jdbc文件夹下新建hive文件夹
D:\Program Files\DbVisualizer\jdbc
2、拷贝Hadoop的相关jar包放入新建的hive文件夹里面
jar包位置:
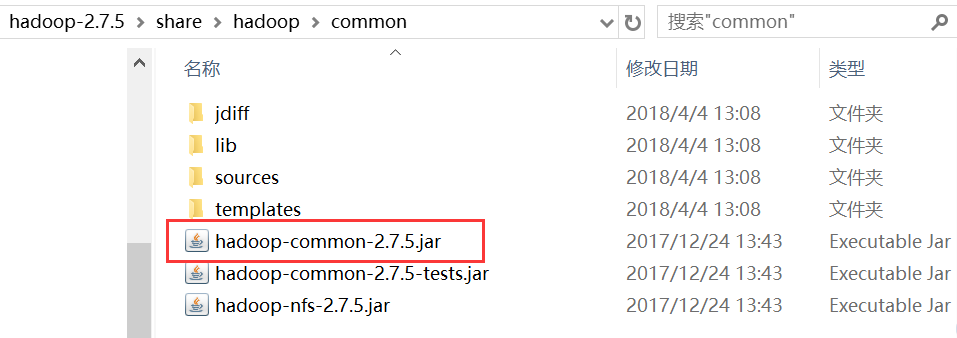
(1) hadoop-2.7.5/share/hadoop/common/hadoop-common-2.7.5.jar
把图中红框中的jar包拷贝到新建的hive文件夹里面
(2) hadoop-2.7.5/share/hadoop/common/lib/
把图中涉及到的jar包拷贝到新建的hive文件夹里面
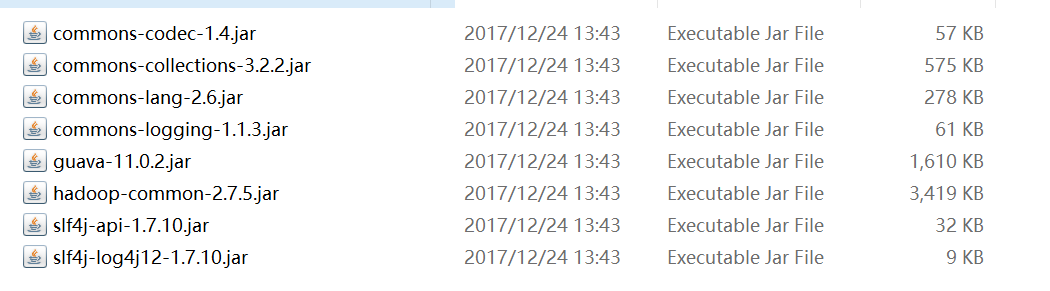
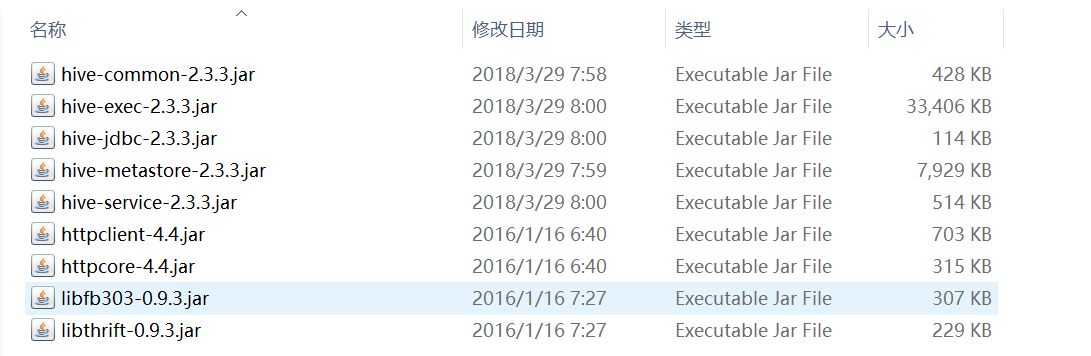
3、拷贝Hive的相关jar包放入新建的hive文件夹里面
jar包位置:
(1) apache-hive-2.3.3-bin/jdbc/lib
把图中涉及到的jar包拷贝到新建的hive文件夹里面
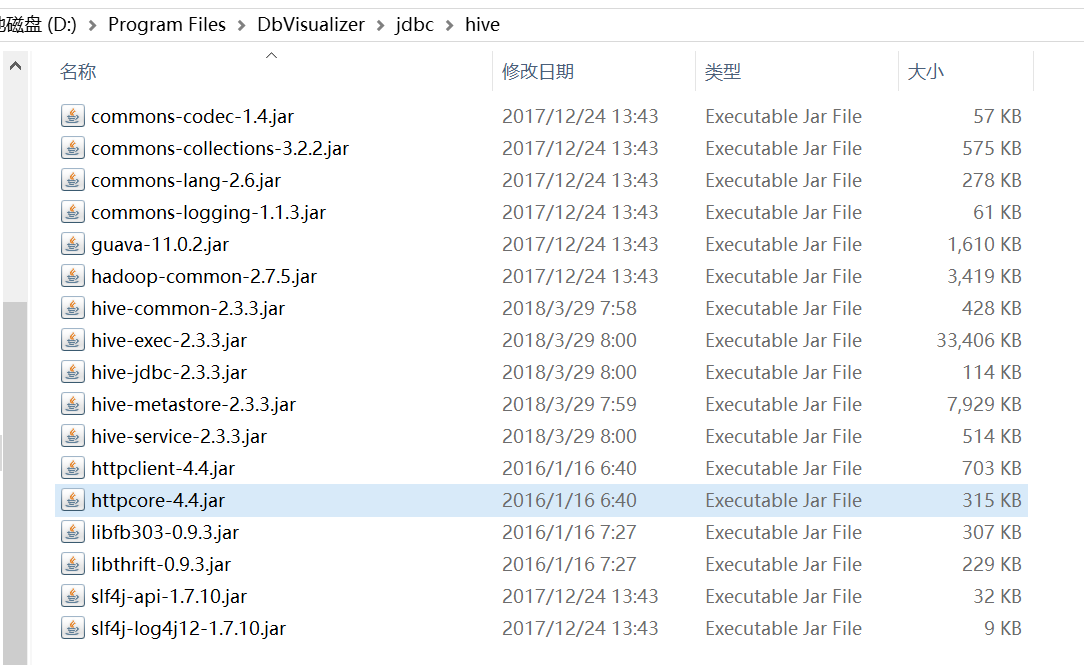
4、结果
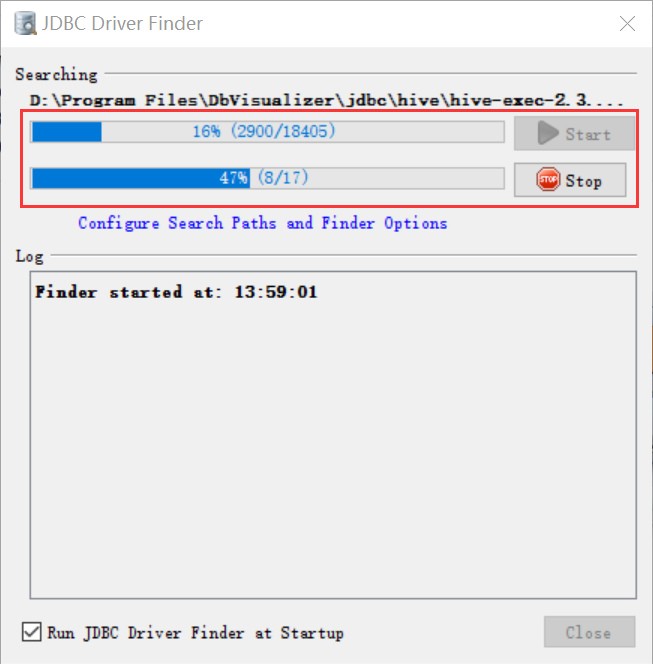
5、在tools/Driver manager中进行配置
打开DbVisualizer,此时会进行加载刚添加的jar包
6、在Tool--Driver manager中进行配置
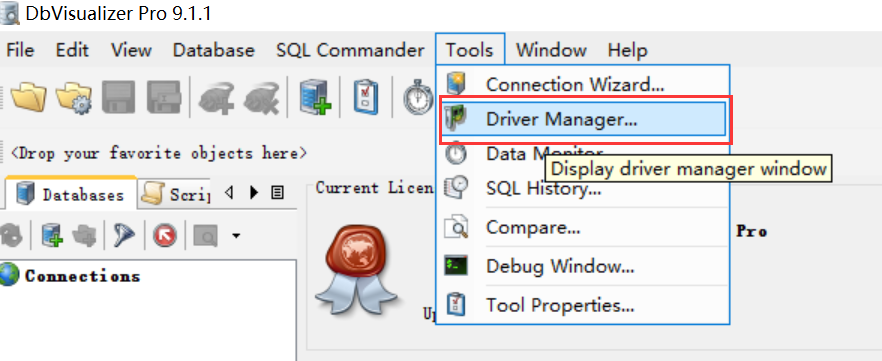
点击左上角的添加

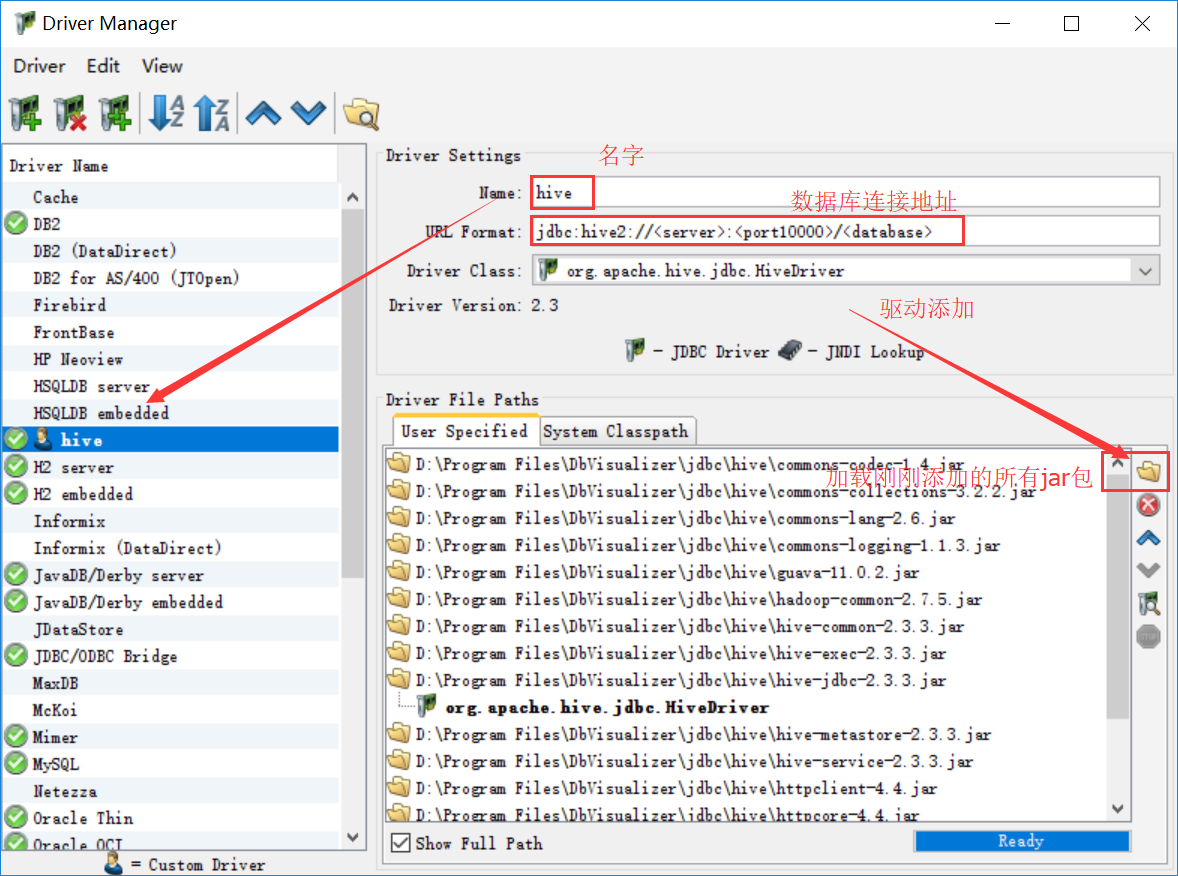
完成之后关闭窗口
点击添加连接数据库
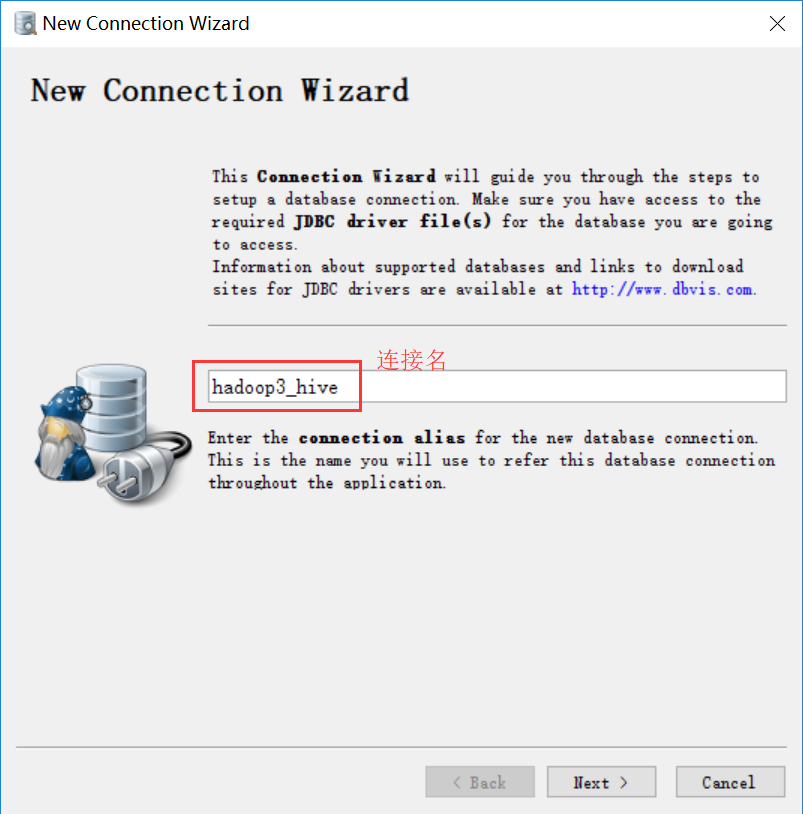
选择驱动

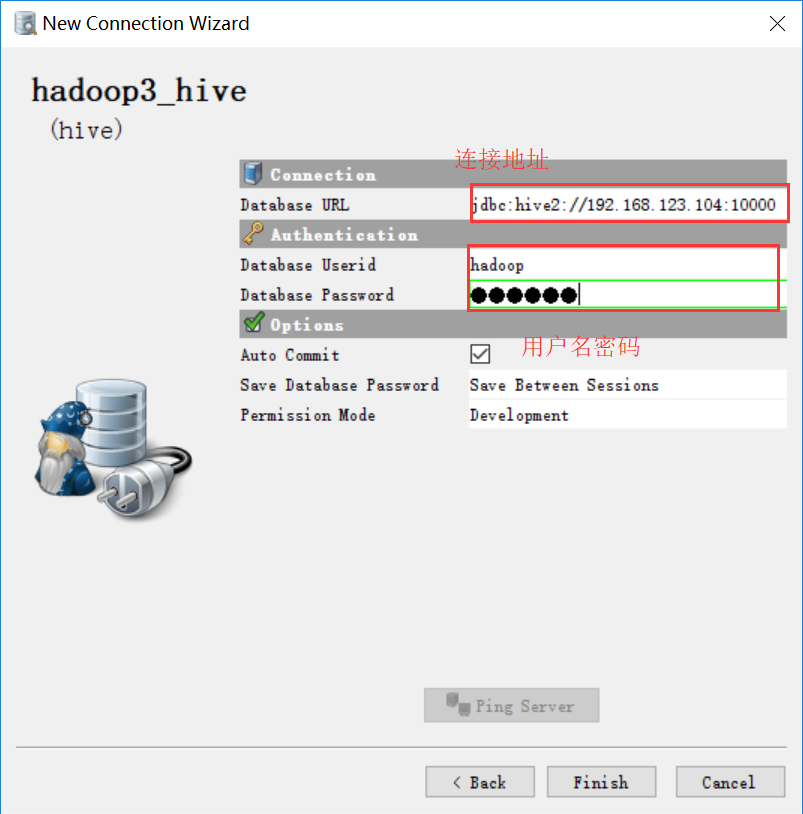
点击完成
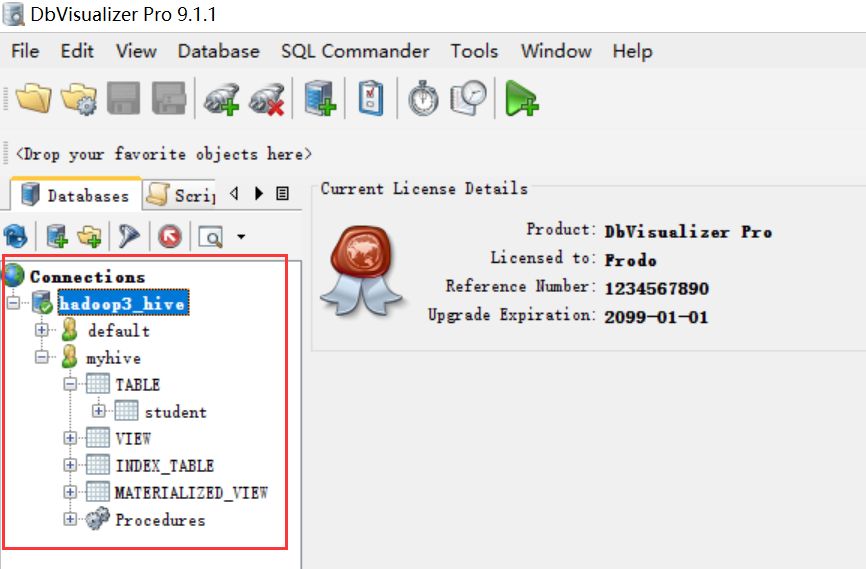
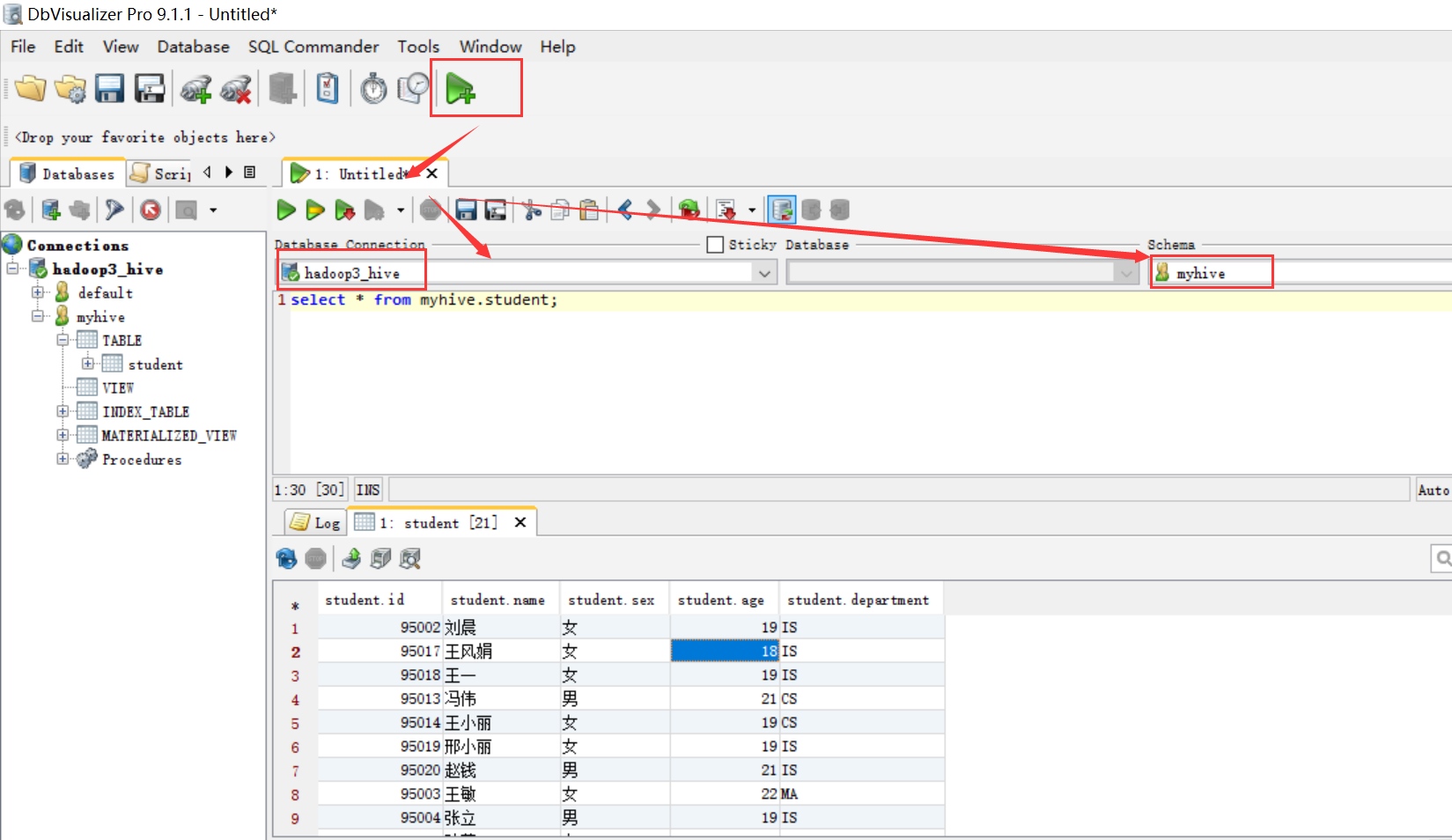
Hive(四)Hive的3种连接方式与DbVisualizer连接Hive的更多相关文章
- FTP的PORT和PASV的连接方式以及数据连接端口号计算
FTP的PORT和PASV的连接方式以及数据连接端口号计算 PORT(自动)方法的连接途中是: 客户端向服务器的FTP端口(原始是21)发送连接请求,服务器领受连接,建立一条command链路. ...
- SQL连接方式(内连接,外连接,交叉连接)
1.内连接.左连接.右连接.全连接介绍 內连接仅选出两张表中互相匹配的记录.因此,这会导致有时我们需要的记录没有包含进来.内部连接是两个表中都必须有连接字段的对应值的记录,数据才能检索出来. 左连 ...
- Hive两种访问方式:HiveServer2 和 Hive Client
老版HiveClient: 要求比较多,需要Hive和Hadoop的jar包,各配置环境. HiveServer2: 使得与YARN和HDFS的连接从Client中独立出来, ...
- Java开发学习(四)----bean的三种实例化方式
一.环境准备 准备开发环境 创建一个Maven项目 pom.xml添加依赖 resources下添加spring的配置文件applicationContext.xml 最终项目的结构如下: 二. ...
- Spring第一课:基于XML装配bean(四),三种实例化方式:默认构造、静态工厂、实例工厂
Spring中基于XML中的装配bean有三种方式: 1.默认构造 2.静态工厂 3.实例工厂 1.默认构造 在我们在Spring的xml文件中直接通过: <bean id=" ...
- mybatis学习四 mybatis的三种查询方式
<select id="selAll" resultType="com.caopeng.pojo.Flower"> select * from fl ...
- Hive——连接方式
Hive--连接方式 一.CLI连接 直接通过CLI连接hive,进行相关hive sql 操作. 直接使用 hive-1.1.0-cdh5.7.0/bin/hive 命令即可 hive> ...
- oracle Hash Join及三种连接方式
在Oracle中,确定连接操作类型是执行计划生成的重要方面.各种连接操作类型代表着不同的连接操作算法,不同的连接操作类型也适应于不同的数据量和数据分布情况. 无论是Nest Loop Join(嵌套循 ...
- Oracle 表连接方式分析 .
一 引言 数据仓库技术是目前已知的比较成熟和被广泛采用的解决方案,用于整和电信运营企业内部所有分散的原始业务数据,并通过便捷有效的数据访问手段,可以支持企业内部不同部门,不同需求,不同层次的用户随时获 ...
随机推荐
- django中的认证与登录
认证登录 django.contrib.auth中提供了许多方法,这里主要介绍其中的三个: 1 authenticate(**credentials) 提供了用户认证,即验证用户名以及密码是否 ...
- Hadoop部署方式-本地模式(Local (Standalone) Mode)
Hadoop部署方式-本地模式(Local (Standalone) Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop总共有三种运行方式.本地模式(Local ...
- npm 5.4.2 更新后就不能用了
今天刚,npm run dev 就出现更新提示,没多想就更了, 更新用了49S,下来npm 的所以命令包一个semer的插件 ... 最后下载新node 8.5覆盖安装, 就解决了, node 8.5 ...
- wav文件格式及ffmpeg处理命令
wav文件头详解 符合RIFF(Resource Interchange File Format)规范的wav文件的文件头记录了音频流的编码参数等基本信息.wav文件由多个块组成,至少包含RIFF标志 ...
- C++的一些不错开源框架,可以学习和借鉴
from https://www.cnblogs.com/charlesblc/p/5703557.html [本文系外部转贴,原文地址:http://coolshell.info/c/c++/201 ...
- mysql自学路线
入门: -Head First:PHP & MySQL.Lynn Beighley -MySQL必知必会 -MySQL5.5从零开始学.刘增杰 -MYSQL完全手册 (the Complete ...
- XML学习(1)
什么是XML? XML是可拓展标记语言,类似HTML,它的设计宗旨是为了传输数据,而不是像HTML那样显示数据.XML标签没有被预定义,需要用户自定义标签. xml文档必须包含根元素,它是其他所有元素 ...
- Ubuntu 15.04 双击运行 *.sh、*.py文件
源 起 之前一直在Windows下用AndoridStudio,今天试了一下在Linux系统Ubuntu 15.04中配置Android Studio: 过程和Windws下差不多,但是最后没有生成桌 ...
- 【leetcode 简单】 第九十九题 字符串相加
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和. 注意: num1 和num2 的长度都小于 5100. num1 和num2 都只包含数字 0-9. num1 和num2 都不包 ...
- 在mac环境下用QT使用OpenGL,glut,glfw
只需要在新建工程中.pro文件中添加: #opengl glut LIBS+= -framework opengl -framework glut 就可以使用glut了. 继续添加: ##glfw L ...