tensorflow(3):神经网络优化(ema,regularization)
1.指数滑动平均 (ema)


描述滑动平均:

with tf.control_dependencies([train_step,ema_op]) 将计算滑动平均与 训练过程绑在一起运行
train_op=tf.no_op(name='train') 使它们合成一个训练节点
#定义变量一级滑动平均类
#定义一个32位浮点变量,初始值为0.0, 这个代码就是在不断更新w1参数,优化 w1,滑动平均做了一个w1的影子
w1=tf.Variable(0,dtype=tf.float32)
#定义num_updates(NN 的迭代次数)初始值为0, global_step不可被优化(训练) 这个额参数不训练
global_step=tf.Variable(0,trainable=False)
#设置衰减率0.99 当前轮数global_step
MOVING_AVERAGE_DECAY=0.99
ema=tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
#ema.apply后面的括号是更新列表,每次运行sess.run(ema_op)时,对更新列表中的元素求滑动平均值,
#在实际应用中会使用tf.trainable_variable()自动将所有待训练的参数汇总为列表
#ema_op=ema.apply([w1])
ema_op=ema.apply(tf.trainable_variables()) #查看不同迭代中变量的取值变化
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
#ema_op=ema.apply([w1])获取w1 的滑动平均值,
print(sess.run([w1,ema.average(w1)])) #打印当前参数w1和w1 的滑动平均值 (0,0)
sess.run(tf.assign(w1,1))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)])) #(1,0.9)
#跟新step w1的值,模拟出100轮迭代后,参数w1 变为10
sess.run(tf.assign(global_step,100))
sess.run(tf.assign(w1,10))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)])) #(10,1.644) #每次sess.run会更新一次w1的滑动平均值
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
结果:
[0.0, 0.0]
[1.0, 0.9]
[10.0, 1.6445453]
[10.0, 2.3281732]
[10.0, 2.955868]
[10.0, 3.532206]
[10.0, 4.061389]
[10.0, 4.547275]
w1的移动平均会越来越趋近于w1 ...
2.正则化regularization
有时候模型对训练集的正确率很高, 却对新数据很难做出正确的相应, 这个叫过拟合现象.

加入噪声后,loss变成了两个部分,前者是以前讲过的普通loss,
后者的loss(w)有两种求法,分别称为L1正则化与 L2正则化
以下举例说明:

代码:
atch_size=30
#建立数据集
seed=2
rdm=np.random.RandomState(seed)
X=rdm.randn(300,2)
Y_=[int(x0*x0+x1*x1<2) for (x0,x1) in X]
Y_c=[['red' if y else 'blue'] for y in Y_] #1则红色,0则蓝色
X=np.vstack(X).reshape(-1,2) #整理为n行2列,按行的顺序来
Y_=np.vstack(Y_).reshape(-1,1)# 整理为n行1列
#print(X)
#print(Y_)
#print(Y_c)
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))#np.squeeze(Y_c)变成一个list
plt.show()
#print(np.squeeze(Y_c)) #定义神经网络的输入 输出 参数, 定义前向传播过程
def get_weight(shape,regularizer): #w的shape 和w的权重
w=tf.Variable(tf.random_normal(shape),dtype=tf.float32)
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))
return w def get_bias(shape): #b的长度
b=tf.Variable(tf.constant(0.01,shape=shape))
return b
#
x=tf.placeholder(tf.float32,shape=(None,2))
y_=tf.placeholder(tf.float32,shape=(None,1))
w1=get_weight([2,11],0.01)
b1=get_bias([11])
y1=tf.nn.relu(tf.matmul(x,w1)+b1) #relu 激活函数 w2=get_weight([11,1],0.01)
b2=get_bias([1])
y=tf.matmul(y1,w2)+b2 #输出层不过激活函数 #定义损失函数loss
loss_mse=tf.reduce_mean(tf.square(y-y_))
loss_total=loss_mse+tf.add_n(tf.get_collection('losses')) #定义反向传播方法, 不含正则化, 要是使用正则化,则 为loss_total
train_step=tf.train.AdamOptimizer(0.0001).minimize(loss_mse)
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
steps=40000
for i in range(steps):
start=(i*batch_size)%300
end=start+batch_size
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%10000==0:
loss_mse_v=sess.run(loss_mse,feed_dict={x:X,y_:Y_})
print('after %d steps,loss is:%f'%(i,loss_mse_v))
xx,yy=np.mgrid[-3:3:0.01,-3:3:0.01]
grid=np.c_[xx.ravel(),yy.ravel()]
probs=sess.run(y,feed_dict={x:grid})
probs=probs.reshape(xx.shape) #调整成xx的样子
print('w1:\n',sess.run(w1))
print('b1:\n',sess.run(b1))
print('w2:\n',sess.run(w2))
print('b2:\n',sess.run(b2))
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[.5]) #给probs=0.5的值上色 (显示分界线)
plt.show() #使用个正则化
train_step=tf.train.AdamOptimizer(0.0001).minimize(loss_total)
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
steps=40000
for i in range(steps):
start=(i*batch_size)%300
end=start+batch_size
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%10000==0:
loss_v=sess.run(loss_total,feed_dict={x:X,y_:Y_})
print('after %d steps,loss is:%f'%(i,loss_v))
xx,yy=np.mgrid[-3:3:0.01,-3:3:0.01]
grid=np.c_[xx.ravel(),yy.ravel()]
probs=sess.run(y,feed_dict={x:grid})
probs=probs.reshape(xx.shape) #调整成xx的样子
print('w1:\n',sess.run(w1))
print('b1:\n',sess.run(b1))
print('w2:\n',sess.run(w2))
print('b2:\n',sess.run(b2))
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[.5]) #给probs=0.5的值上色
plt.show()
结果显示:

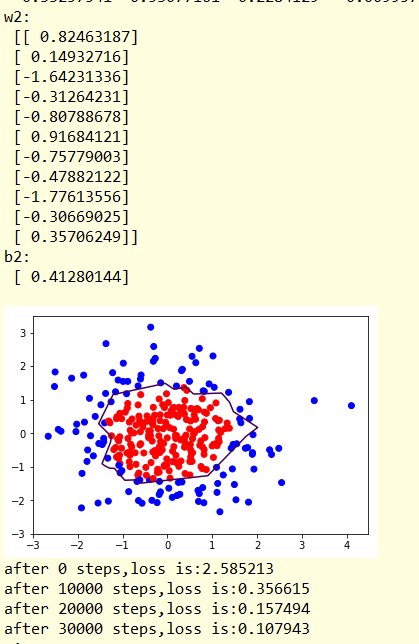

显然 经过正则化,分割线更加平滑,数据集中的噪声对模型的影响更小,
tensorflow(3):神经网络优化(ema,regularization)的更多相关文章
- tensorflow(2):神经网络优化(loss,learning_rate)
案例: 预测酸奶的日销量, 由此可以准备产量, 使得损失小(利润大),假设销量是y , 影响销量的有两个因素x1, x2, 需要预先采集数据,每日的x1,x2和销量y_, 拟造数据集X,Y_, 假设y ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- 通过TensorFlow训练神经网络模型
神经网络模型的训练过程其实质上就是神经网络参数的设置过程 在神经网络优化算法中最常用的方法是反向传播算法,下图是反向传播算法流程图: 从上图可知,反向传播算法实现了一个迭代的过程,在每次迭代的开始,先 ...
- 深度学习之TensorFlow构建神经网络层
深度学习之TensorFlow构建神经网络层 基本法 深度神经网络是一个多层次的网络模型,包含了:输入层,隐藏层和输出层,其中隐藏层是最重要也是深度最多的,通过TensorFlow,python代码可 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- Halide视觉神经网络优化
Halide视觉神经网络优化 概述 Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言.主要的作用为在软硬层面上( ...
- tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)
1.学习率的设置既不能太小,又不能太大,解决方法:使用指数衰减法 例如: 假设我们要最小化函数 y=x2y=x2, 选择初始点 x0=5x0=5 1. 学习率为1的时候,x在5和-5之间震荡. im ...
随机推荐
- IDEA-使用技巧
IDEA--个性化配置 - 心飞扬的博客 - CSDN博客--里面很好,http://blog.csdn.net/afzaici/article/details/71524643 IntelliJ I ...
- 打印手机当前界面(位于栈顶)的activity
adb shell dumpsys activity activities | grep "Hist #0" 一般第一条就是当前页(位于栈顶)的activity
- setInterval 传值设参数
<script type="text/javascript" > window.onload=function(){ for(var i=1;i<3;i++){ ...
- Qemu-KVM管理
内容: 一.KVM基本配置 二.KVM网络的桥接 三.创建虚拟机 四.虚拟机的关闭和启动 关于KVM: 1).KVM是开源软件,全称是kernel-based virtual machine(基于内核 ...
- OGG初始化之使用Oracle Data Pump加载数据
此方法使用Oracle Data Pump实用程序来建立目标数据.将副本应用于目标后,您将记录副本停止的SCN.包含在副本中的交易将被跳过以避免完整性违规冲突.从流程起点,Oracle GoldenG ...
- C++11 override 和 final 关键字
C++11之前,一直没有继承控制关键字.禁用一个类的进一步衍生是可能的但也很棘手.为避免用户在派生类中重载一个虚函数,你不得不向后考虑. C++ 11添加了两个继承控制关键字:override和fin ...
- [python] 基础工具介绍好文推荐
Github上有个哥们写的,还不错,mark一下: https://github.com/lijin-THU/notes-python/blob/master/index.ipynb 相对全面的介绍了 ...
- Windows下return,exit和ExitProcess的区别和分析
通常,我们为了使自己的程序结束,会在主函数中使用return或调用exit().在windows下还有ExitProcess()和TerminateProcess()等函数. 本文的目的是比较以上几种 ...
- Openssl编程--源码分析
Openssl编程 赵春平 著 Email: forxy@126.com 第一章 基础知识 8 1.1 对称算法 8 1.2 摘要算法 9 1.3 公钥算法 9 1.4 回调函数 11 第二章 ope ...
- $Django RESTful规范
一 什么是RESTful REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中文翻译为“表征状态转移” REST从资源的角度 ...