tensorflow(3):神经网络优化(ema,regularization)
1.指数滑动平均 (ema)


描述滑动平均:

with tf.control_dependencies([train_step,ema_op]) 将计算滑动平均与 训练过程绑在一起运行
train_op=tf.no_op(name='train') 使它们合成一个训练节点
#定义变量一级滑动平均类
#定义一个32位浮点变量,初始值为0.0, 这个代码就是在不断更新w1参数,优化 w1,滑动平均做了一个w1的影子
w1=tf.Variable(0,dtype=tf.float32)
#定义num_updates(NN 的迭代次数)初始值为0, global_step不可被优化(训练) 这个额参数不训练
global_step=tf.Variable(0,trainable=False)
#设置衰减率0.99 当前轮数global_step
MOVING_AVERAGE_DECAY=0.99
ema=tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY,global_step)
#ema.apply后面的括号是更新列表,每次运行sess.run(ema_op)时,对更新列表中的元素求滑动平均值,
#在实际应用中会使用tf.trainable_variable()自动将所有待训练的参数汇总为列表
#ema_op=ema.apply([w1])
ema_op=ema.apply(tf.trainable_variables()) #查看不同迭代中变量的取值变化
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
#ema_op=ema.apply([w1])获取w1 的滑动平均值,
print(sess.run([w1,ema.average(w1)])) #打印当前参数w1和w1 的滑动平均值 (0,0)
sess.run(tf.assign(w1,1))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)])) #(1,0.9)
#跟新step w1的值,模拟出100轮迭代后,参数w1 变为10
sess.run(tf.assign(global_step,100))
sess.run(tf.assign(w1,10))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)])) #(10,1.644) #每次sess.run会更新一次w1的滑动平均值
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1,ema.average(w1)]))
结果:
[0.0, 0.0]
[1.0, 0.9]
[10.0, 1.6445453]
[10.0, 2.3281732]
[10.0, 2.955868]
[10.0, 3.532206]
[10.0, 4.061389]
[10.0, 4.547275]
w1的移动平均会越来越趋近于w1 ...
2.正则化regularization
有时候模型对训练集的正确率很高, 却对新数据很难做出正确的相应, 这个叫过拟合现象.

加入噪声后,loss变成了两个部分,前者是以前讲过的普通loss,
后者的loss(w)有两种求法,分别称为L1正则化与 L2正则化
以下举例说明:

代码:
atch_size=30
#建立数据集
seed=2
rdm=np.random.RandomState(seed)
X=rdm.randn(300,2)
Y_=[int(x0*x0+x1*x1<2) for (x0,x1) in X]
Y_c=[['red' if y else 'blue'] for y in Y_] #1则红色,0则蓝色
X=np.vstack(X).reshape(-1,2) #整理为n行2列,按行的顺序来
Y_=np.vstack(Y_).reshape(-1,1)# 整理为n行1列
#print(X)
#print(Y_)
#print(Y_c)
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))#np.squeeze(Y_c)变成一个list
plt.show()
#print(np.squeeze(Y_c)) #定义神经网络的输入 输出 参数, 定义前向传播过程
def get_weight(shape,regularizer): #w的shape 和w的权重
w=tf.Variable(tf.random_normal(shape),dtype=tf.float32)
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))
return w def get_bias(shape): #b的长度
b=tf.Variable(tf.constant(0.01,shape=shape))
return b
#
x=tf.placeholder(tf.float32,shape=(None,2))
y_=tf.placeholder(tf.float32,shape=(None,1))
w1=get_weight([2,11],0.01)
b1=get_bias([11])
y1=tf.nn.relu(tf.matmul(x,w1)+b1) #relu 激活函数 w2=get_weight([11,1],0.01)
b2=get_bias([1])
y=tf.matmul(y1,w2)+b2 #输出层不过激活函数 #定义损失函数loss
loss_mse=tf.reduce_mean(tf.square(y-y_))
loss_total=loss_mse+tf.add_n(tf.get_collection('losses')) #定义反向传播方法, 不含正则化, 要是使用正则化,则 为loss_total
train_step=tf.train.AdamOptimizer(0.0001).minimize(loss_mse)
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
steps=40000
for i in range(steps):
start=(i*batch_size)%300
end=start+batch_size
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%10000==0:
loss_mse_v=sess.run(loss_mse,feed_dict={x:X,y_:Y_})
print('after %d steps,loss is:%f'%(i,loss_mse_v))
xx,yy=np.mgrid[-3:3:0.01,-3:3:0.01]
grid=np.c_[xx.ravel(),yy.ravel()]
probs=sess.run(y,feed_dict={x:grid})
probs=probs.reshape(xx.shape) #调整成xx的样子
print('w1:\n',sess.run(w1))
print('b1:\n',sess.run(b1))
print('w2:\n',sess.run(w2))
print('b2:\n',sess.run(b2))
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[.5]) #给probs=0.5的值上色 (显示分界线)
plt.show() #使用个正则化
train_step=tf.train.AdamOptimizer(0.0001).minimize(loss_total)
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
steps=40000
for i in range(steps):
start=(i*batch_size)%300
end=start+batch_size
sess.run(train_step,feed_dict={x:X[start:end],y_:Y_[start:end]})
if i%10000==0:
loss_v=sess.run(loss_total,feed_dict={x:X,y_:Y_})
print('after %d steps,loss is:%f'%(i,loss_v))
xx,yy=np.mgrid[-3:3:0.01,-3:3:0.01]
grid=np.c_[xx.ravel(),yy.ravel()]
probs=sess.run(y,feed_dict={x:grid})
probs=probs.reshape(xx.shape) #调整成xx的样子
print('w1:\n',sess.run(w1))
print('b1:\n',sess.run(b1))
print('w2:\n',sess.run(w2))
print('b2:\n',sess.run(b2))
plt.scatter(X[:,0],X[:,1],c=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[.5]) #给probs=0.5的值上色
plt.show()
结果显示:

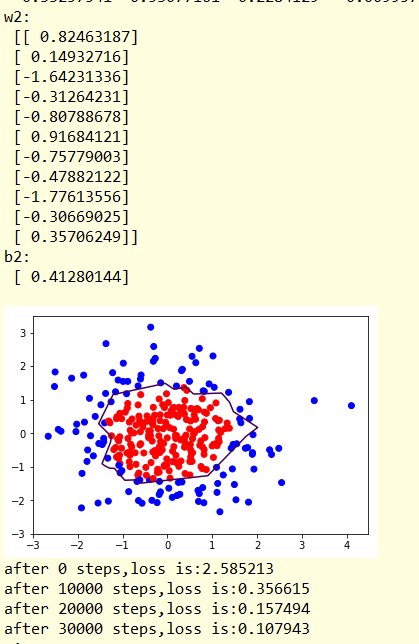

显然 经过正则化,分割线更加平滑,数据集中的噪声对模型的影响更小,
tensorflow(3):神经网络优化(ema,regularization)的更多相关文章
- tensorflow(2):神经网络优化(loss,learning_rate)
案例: 预测酸奶的日销量, 由此可以准备产量, 使得损失小(利润大),假设销量是y , 影响销量的有两个因素x1, x2, 需要预先采集数据,每日的x1,x2和销量y_, 拟造数据集X,Y_, 假设y ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
- 通过TensorFlow训练神经网络模型
神经网络模型的训练过程其实质上就是神经网络参数的设置过程 在神经网络优化算法中最常用的方法是反向传播算法,下图是反向传播算法流程图: 从上图可知,反向传播算法实现了一个迭代的过程,在每次迭代的开始,先 ...
- 深度学习之TensorFlow构建神经网络层
深度学习之TensorFlow构建神经网络层 基本法 深度神经网络是一个多层次的网络模型,包含了:输入层,隐藏层和输出层,其中隐藏层是最重要也是深度最多的,通过TensorFlow,python代码可 ...
- zz图像、神经网络优化利器:了解Halide
动图示例实在太好 图像.神经网络优化利器:了解Halide Oldpan 2019年4月17日 0条评论 1,327次阅读 3人点赞 前言 Halide是用C++作为宿主语言的一个图像处理相 ...
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- Halide视觉神经网络优化
Halide视觉神经网络优化 概述 Halide是用C++作为宿主语言的一个图像处理相关的DSL(Domain Specified Language)语言,全称领域专用语言.主要的作用为在软硬层面上( ...
- tensorflow:实战Google深度学习框架第四章02神经网络优化(学习率,避免过拟合,滑动平均模型)
1.学习率的设置既不能太小,又不能太大,解决方法:使用指数衰减法 例如: 假设我们要最小化函数 y=x2y=x2, 选择初始点 x0=5x0=5 1. 学习率为1的时候,x在5和-5之间震荡. im ...
随机推荐
- 【mmall】Guava框架
Guava 简介:http://www.yiibai.com/guava 本项目主要用到了Guava缓存
- mysql 架构 ~ MHA 总揽
一 简介:MHA相关二 版本 mha0.56 mha0.57 mha0.58三 切换流程 0 主库已不可达 阶段一 1 从集群选出新主,根据新主同步的binlog信息进行拷贝binl ...
- 调试 - Visual Studio调试
Visual Studio - 调试 异常处理机制 windows预定义了一系列的异常错误码,每种程序异常都有一个对应的错误码,windows系统将这些类似键值对关系的数据存储在异常处理表中(称为SE ...
- scrapy基础 之 静态网页实例
1,scrapy爬虫基本流程: 1. 创建一个新的Scrapy Project > scrapy startproject 项目名称 #系统会在当前目录下创建一个项目名称命名的文件夹,其下 ...
- 第五节,K-近邻算法(KNN)
收集数据——>准备数据——>分析数据——>训练算法——>测试算法——>使用算法 K-近邻算法: (1)计算已知类别数据集中的点与当前点之间的距离 (2)按照距离递增次序排 ...
- Linux将rm命令设置为回收站【转】
一个方案就是重定向 rm 命令以嫁接为 mv 命令,相当于给 Linux 系统定制了一个回收站. 实现方式如下: ### 重定义rm命令 ### # 定义回收站目录 trash_path='~/.tr ...
- python之async-timeout模块
async-timeout 兼容async的超时的上下文管理器 async-timeout的timeout和asyncio的wiat_for比较 首先从使用上来说asyncio.wait_for(aw ...
- sublime修改侧边栏字体
安装了sublime的material主题后,侧边栏的字体特别小,设置方法如下: 安装插件 用上面的插件打开 Material-Theme.sublime-theme 如下 { "class ...
- 设计模式C++学习笔记之十七(Chain of Responsibility责任链模式)
17.1.解释 概念:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系.将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止. main(),客户 IWom ...
- page.isvalid
背景 看到这个标题,想了半天,为啥用的.应该是当初前台要动态增加行这个事情,当初用.net真是用傻了,竟然对html.aspx原理不大清楚,对于html也想着后台生成.真是弱智啊.谈到这里,想到c#这 ...