TensorFlow池化层-函数
池化层的作用如下-引用《TensorFlow实践》:
池化层的作用是减少过拟合,并通过减小输入的尺寸来提高性能。他们可以用来对输入进行降采样,但会为后续层保留重要的信息。只使用tf.nn.conv2d来减小输入的尺寸也是可以的,但是池化层的效率更高。
常见的TensorFlow提供的激活函数如下:(详细请参考http://www.tensorfly.cn/tfdoc/api_docs/python/nn.html)
1.tf.nn.max_pool(value, ksize, strides, padding, name=None)
Performs the max pooling on the input.
value: A 4-DTensorwith shape[batch, height, width, channels]and typefloat32,float64,qint8,quint8,qint32.ksize: A list of ints that has length >= 4. The size of the window for each dimension of the input tensor.strides: A list of ints that has length >= 4. The stride of the sliding window for each dimension of the input tensor.padding: A string, either'VALID'or'SAME'. The padding algorithm.name: Optional name for the operation.
 当我们的ksize=[1 3 3 1]式,我们取3X3模板池pool当中最大的数据当做中心点的值,strides作为滑动跳跃的间隔,代码如下所示:
当我们的ksize=[1 3 3 1]式,我们取3X3模板池pool当中最大的数据当做中心点的值,strides作为滑动跳跃的间隔,代码如下所示:
import tensorflow as tf batch_size = 1
input_height = 3
input_width = 3
input_channels = 1
layer_input = tf.constant([
[
[[1.0],[0.2],[1.5]],
[[0.1],[1.2],[1.4]],
[[1.1],[0.4],[0.4]]
]
])
kernel = [batch_size, input_height, input_width,input_channels]
max_pool = tf.nn.max_pool(layer_input,kernel,[1,1,1,1],padding='VALID',name=None)
sess = tf.Session()
sess.run(max_pool)
输出结果如下(注意max_pool的输入的参数的维数一定要正确,否则会报错):

2.tf.nn.avg_pool(value, ksize, strides, padding, name=None)
Performs the average pooling on the input.
Each entry in output is the mean of the corresponding size ksize window in value.
value: A 4-DTensorof shape[batch, height, width, channels]and typefloat32,float64,qint8,quint8, orqint32.ksize: A list of ints that has length >= 4. The size of the window for each dimension of the input tensor.strides: A list of ints that has length >= 4. The stride of the sliding window for each dimension of the input tensor.padding: A string, either'VALID'or'SAME'. The padding algorithm.name: Optional name for the operation.
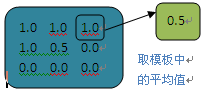 跳跃遍历一个张量,并将被卷积核覆盖的各深度值去平均。当整个卷积核都非常重要时,若需要实现值的缩减,平均池化非常有用,例如输入张量宽度和高度很大,但深度很小的情况。
跳跃遍历一个张量,并将被卷积核覆盖的各深度值去平均。当整个卷积核都非常重要时,若需要实现值的缩减,平均池化非常有用,例如输入张量宽度和高度很大,但深度很小的情况。
import tensorflow as tf batch_size = 1
input_height = 3
input_width = 3
input_channels = 1
layer_input = tf.constant([
[
[[1.0],[1.0],[1.0]],
[[1.0],[0.5],[0.0]],
[[0.0],[0.0],[0.0]]
]
])
kernel = [batch_size, input_height, input_width,input_channels]
avg_pool = tf.nn.mavg_pool(layer_input,kernel,[1,1,1,1],padding='VALID',name=None)
sess = tf.Session()
sess.run(avg_pool)
输出结果如下:(1.0+1.0+1.0+0.5+0.0+0.0+0.0+0.0)/9=0.5

TensorFlow池化层-函数的更多相关文章
- TensorFlow 池化层
在 TensorFlow 中使用池化层 在下面的练习中,你需要设定池化层的大小,strides,以及相应的 padding.你可以参考 tf.nn.max_pool().Padding 与卷积 pad ...
- tensorflow 1.0 学习:池化层(pooling)和全连接层(dense)
池化层定义在 tensorflow/python/layers/pooling.py. 有最大值池化和均值池化. 1.tf.layers.max_pooling2d max_pooling2d( in ...
- tensorflow的卷积和池化层(二):记实践之cifar10
在tensorflow中的卷积和池化层(一)和各种卷积类型Convolution这两篇博客中,主要讲解了卷积神经网络的核心层,同时也结合当下流行的Caffe和tf框架做了介绍,本篇博客将接着tenso ...
- tensorflow中的卷积和池化层(一)
在官方tutorial的帮助下,我们已经使用了最简单的CNN用于Mnist的问题,而其实在这个过程中,主要的问题在于如何设置CNN网络,这和Caffe等框架的原理是一样的,但是tf的设置似乎更加简洁. ...
- tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图
tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图 因为很多 demo 都比较复杂,专门抽出这两个函数,写的 demo. 更多教程:http://www.tensorflown ...
- 『TensorFlow』卷积层、池化层详解
一.前向计算和反向传播数学过程讲解
- 第十三节,使用带有全局平均池化层的CNN对CIFAR10数据集分类
这里使用的数据集仍然是CIFAR-10,由于之前写过一篇使用AlexNet对CIFAR数据集进行分类的文章,已经详细介绍了这个数据集,当时我们是直接把这些图片的数据文件下载下来,然后使用pickle进 ...
- 学习笔记TF014:卷积层、激活函数、池化层、归一化层、高级层
CNN神经网络架构至少包含一个卷积层 (tf.nn.conv2d).单层CNN检测边缘.图像识别分类,使用不同层类型支持卷积层,减少过拟合,加速训练过程,降低内存占用率. TensorFlow加速所有 ...
- 基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转) 深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件.不过 Tens ...
随机推荐
- 自定义Dialog的详细步骤(实现自定义样式一般原理)
现在很多App的提示对话框都非常有个性,然而你还用系统的对话框样式,是不是觉得很落后呢,今天我就给大家讲讲怎样自定义自己的Dialog,学会了之后,你就会根据自家app的主题,设计出相应的Dialog ...
- 设置外部查找工具来索引 Confluence 6
任何网页的 crawler 工具都可以被用来索引你的 Confluence 站点中的内容.如果你希望注册用户才能够查看的内容也被索引的话,你需要为你的 Confluence 创建一个只被 crawl ...
- Confluence 6 降级你的许可证
如果你决定降级你 Confluence 的许可证而削减你的许可证开支,你需要确定当前已经直排的用户许可证数量(在用户许可证页面中)要少于你希望应用的新的许可证的允许用户数量,在你应用新许可证的时候. ...
- Confluence 6 在初始化配置时候的问题
提交一个 服务器请求(support request) 然后在你的服务请求中同时提供下面的信息. 下载一个 LDAP 浏览器,你可以通过这个确定你的 LDAP 服务器配置正确.Atlassian 推荐 ...
- MobileNet V2
https://zhuanlan.zhihu.com/p/33075914 http://blog.csdn.net/u011995719/article/details/79135818 https ...
- Unnamed namespaces
Unnamed namespaces The unnamed-namespace-definition is a namespace definition of the form inline(o ...
- GoLang函数参数的传递练习
春节买的GO方面的书,看了一次.现在撸一些代码,作为练习. // Copyright © 2019 NAME HERE <EMAIL ADDRESS> // // Licensed und ...
- web应用启动后发现被自动访问
为了找到原因,做了以下操作,发现是eclipse访问的,但是具体原因未知
- 想要将我们的OSGi框架中的批量日志单独打印到文件中
我们的日志虽然没有直接依赖logback,但遗憾的是也没有使用slf4j,而是使用了Apache Common-Logging slf4j 和 common-logging有什么区别呢 common- ...
- Linux查找当前目录5天的文件并打包
find . -name "*.sh" -mtime -5 |xargs tar zcvf /tmp/log.tar.gz 解释: *.sh是查找以.sh结尾的文件,也可以是其他如 ...