数据挖掘的标准流程-CRISP-DM
1、起源
CRISP-DM (cross-industry standard process for data mining), 即为"跨行业数据挖掘过程标准"。此KDD(knowledge discovery in database,KDD, 数据库知识发现)过程模型于1999年欧盟机构联合起草. 通过近几年的发展,CRISP-DM 模型在各种KDD过程模型中占据领先位置,采用量达到近60%.(数据引自Cios and Kurgan于2005年合著的论文trends in data mining and knowledge discovery中 )
在1996年,当时数据挖掘市场是年轻而不成熟的,但是这个市场显示了爆炸式的增长。三个在这方面经验丰富的公司DaimlerChrysler、SPSS、NCR发起建立一个社团,目的建立数据挖掘方法和过程的标准。在获得了EC(European Commission)的资助后,他们开始实现他们的目标。为了征集业界广泛的意见共享知识,他们创建了CRISP-DM Special Interest Group(简称为SIG)。
大概在1999年,SIG(CRISP-DM Special Interest Group)组织开发并提炼出CRISP-DM(CRoss-Industry Standard Process for Data Mining),同时在Mercedes-Benz和OHRA(保险领域)企业进行了大规模数据挖掘项目的实际试用。SIG还将CRISP-DM和商业数据挖掘工具集成起来。SIG组织目前在伦敦、纽约、布鲁塞尔已经发展到200多个成员。
当前CRISP-DM提供了一个数据挖掘生命周期的全面评述。他包括项目的相应周期,他们的各自任务和这些任务的关系。在这个描述层,识别出所有关系是不可能的。所有数据挖掘任务之间关系的存在是依赖用户的目的、背景和兴趣,最重要的还有数据。SIG 组织已经发布了CRISP-DM Version 1.0 Process Guide and User Manual的电子版,这个可以免费使用。
事实上,就方法学而言,CRISP-DM并不是什么新观念,本质来看就是在分析应用中提出问题、分析问题和解决问题的过程。而可贵之处在于其提纲挈领的特性,非常适合工程管理,适合大规模定制,以至CRISP-DM如今已经成为事实上的行业标准,“调查显示,50%以上的数据挖掘工具采用的都是CRISP-DM的数据挖掘流程"。
2、实现流程
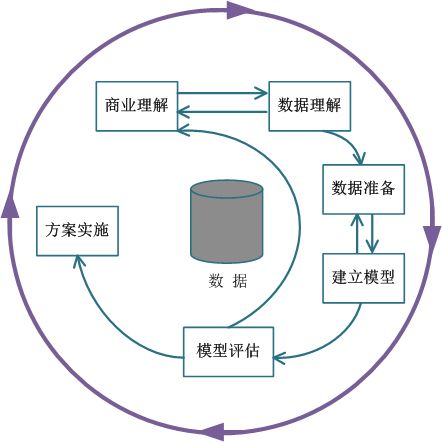
CRISP-DM模型为一个KDD工程提供了一个完整的过程描述。该模型将一个KDD工程分为6个不同的,但顺序并非完全不变的阶段。上图中箭头指出了最重要的和依赖度高的阶段关系。上图的外圈象征数据挖掘自身的循环本质――在一个解决方案发布之后一个数据挖掘的过程才可以继续。在这个过程中得到的知识可以触发新的,经常是更聚焦的商业问题。后续的过程可以从前一个过程得到益处。
最外面这一圈表示数据挖掘自身的循环本质,每一个解决方案部署之后代表另一个数据挖掘的过程也已经开始了,需要在运行过程中不断迭代、更新模型。
集中在理解项目目标和从业务的角度理解需求,定义数据挖掘问题和完成目标的初步计划;
2.1业务理解 (Business Understanding)
最初的阶段集中在理解项目目标和从业务的角度理解需求,同时将这个知识转化为数据挖掘问题的定义和完成目标的初步计划。
从商业的角度上面了解项目的要求和最终目的是什么.并将这些目的与数据挖掘的定义以及结果结合起来。
在这第一个阶段我们必须从商业的角度了解项目的要求和最终目的是什么,并将这些目的与数据挖掘的定义以及结果结合起来。
主要工作包括:确定商业目标,发现影响结果的重要因素,从商业角度描绘客户的首要目标,评估形势,查找所有的资源、局限、设想以及在确定数据分析目标和项目方案时考虑到的各种其他的因素,包括风险和意外、相关术语、成本和收益等等,接下来确定数据挖掘的目标,制定项目计划。
商业理解阶段商业理解是明确要达到的业务目标,并将其转化为数据挖掘主题。要从商业角度对业务部门的需求进行理解,并把业务需求的理解转化为数据挖掘的定义,拟定达成业务目标的初步方案。具体包括商业背景分析、商业成功标准的确定、形势评估、获得企业资源清单、获得企业的要求和设想、评估成本和收益、评估风险和意外、初步理解行业术语,并确定数据挖掘的目标和制定数据挖掘计划。
2.2数据理解 (Data Understanding)
数据理解阶段从初始的数据收集开始,通过一些活动的处理,目的是熟悉数据,识别数据的质量问题,首次发现数据的内部属性,或是探测引起兴趣的子集去形成隐含信息的假设。
从初始的数据收集开始,通过一些活动的处理,目的是熟悉数据,发现数据的内部属性,或是探测引起兴趣的子集去形成隐含信息的假设;
数据的理解以及收集,对可用的数据进行评估。
数据理解阶段开始于数据的收集工作。接下来就是熟悉数据的工作,具体如:检测数据的量,对数据有初步的理解,探测数据中比较有趣的数据子集,进而形成对潜在信息的假设。收集原始数据,对数据进行装载,描绘数据,并且探索数据特征,进行简单的特征统计,检验数据的质量,包括数据的完整性和正确性,缺失值的填补等。
数据理解阶段数据理解是找出可能的影响主题的因素,确定这些影响因素的数据载体、数据体现形式和数据存储位置。数据理解从数据收集开始,然后熟悉数据,具体包括以下工作内容:检测数据质量,对数据进行初步理解,简单描述数据,探测数据意义,并对数据中潜藏的信息和知识提出拟用数据加以验证的假设。
2.3数据准备 (Data Preparation)
数据准备阶段包括从未处理数据中构造最终数据集的所有活动。这些数据将是模型工具的输入值。这个阶段的任务有个能执行多次,没有任何规定的顺序。任务包括表、记录和属性的选择,以及为模型工具转换和清洗数据。
数据准备阶段包括从未处理的数据中构造最终数据集的所有活动。这些数据将是建模阶段的输入值,任务包括属性的选择、数据表、记录的抽取,以及将数据转换为模型工具所需的格式和清洗数据;
数据的准备,对可用的原始数据进行一系列的组织以及清洗,使之达到建模需求。
2.4建模(Modeling)
在这个阶段,可以选择和应用不同的模型技术,模型参数被调整到最佳的数值。一般,有些技术可以解决一类相同的数据挖掘问题。有些技术在数据形成上有特殊要求,因此需要经常跳回到数据准备阶段。
经过建模阶段后,已建立了一个高质量的决策模型,但在开始最后部署模型之前,重要的事情是彻底地评估模型,检查构造模型的步骤,确保模型可以完成业务目标。这个阶段的关键目的是确定是否有重要业务问题没有被充分的考虑,评估模型是否有达到最初设定的目标;
可以选择和应用不同的模型技术,模型参数被调整到最佳的数值。有些技术在数据格式上有特殊要求,因此需要经常跳回到数据准备阶段;
应用数据挖掘工具建立模型。
在这一阶段,各种各样的建模方法将被加以选择和使用,通过建造,评估模型将其参数将被校准为最为理想的值。比较典型的是,对于同一个数据挖掘的问题类型,可以有多种方法选择使用。如果有多重技术要使用,那么在这一任务中,对于每一个要使用的技术要分别对待。一些建模方法对数据的形式有具体的要求,因此,在这一阶段,重新回到数据准备阶段执行某些任务有时是非常必要的。
建立模型阶段建立模型是应用软件工具,选择合适的建模方法,处理准备好的数据宽表,找出数据中隐藏的规律。在建立模型阶段,将选择和使用各种建模方法,并将模型参数进行优化。对同样的业务问题和数据准备,可能有多种数据挖掘技术方法可供选用,此时可优选提升度高、置信度高、简单而易于总结业务政策和建议的数据挖掘技术方法。在建模过程中,还可能会发现一些潜在的数据问题,要求回到数据准备阶段。建立模型阶段的具体工作包括:选择合适的建模技术、进行检验设计、建造模型。
2.5 评估(Evaluation)
到项目的这个阶段,你已经从数据分析的角度建立了一个高质量显示的模型。在开始最后部署模型之前,重要的事情是彻底地评估模型,检查构造模型的步骤,确保模型可以完成业务目标。这个阶段的关键目的是确定是否有重要业务问题没有被充分的考虑。在这个阶段结束后,一个数据挖掘结果使用的决定必须达成。
对建立的模型进行评估,重点具体考虑得出的结果是否符合第一步的商业目的。
从数据分析的角度考虑,在这一阶段中,已经建立了一个或多个高质量的模型。但在进行最终的模型部署之前,更加彻底的评估模型,回顾在构建模型过程中所执行的每一个步骤,是非常重要的,这样可以确保这些模型是否达到了企业的目标。一个关键的评价指标就是看,是否仍然有一些重要的企业问题还没有被充分地加以注意和考虑。在这一阶段结束之时,有关数据挖掘结果的使用应达成一致的决定。
模型评估阶段模型评估是要从业务角度和统计角度进行模型结论的评估。要求检查建模的整个过程,以确保模型没有重大错误,并检查是否遗漏重要的业务问题。当模型评估阶段结束时,应对数据挖掘结果的发布计划达成一致。
2.6 部署 (Deployment)
通常,模型的创建不是项目的结束。模型的作用是从数据中找到知识,获得的知识需要便于用户使用的方式重新组织和展现。根据需求,这个阶段可以产生简单的报告,或是实现一个比较复杂的、可重复的数据挖掘过程。在很多案例中,这个阶段是由客户而不是数据分析人员承担部署的工作。
根据用户需求,实现一个重复的、复杂的数据挖掘过程。
部署,即将其发现的结果以及过程组织成为可读文本形式.(数据挖掘报告)
或者是上线到实际运行的系统中。
根据需求的不同,部署阶段可以是仅仅像写一份报告那样简单,也可以像在企业中进行可重复的数据挖掘程序那样复杂。在许多案例中,往往是客户而不是数据分析师来执行部署阶段。然而,尽管数据分析师不需要处理部署阶段的工作,对于客户而言,预先了解需要执行的活动从而正确的使用已构建的模型是非常重要的。
模型发布阶段模型发布又称为模型部署,建立模型本身并不是数据挖掘的目标,虽然模型使数据背后隐藏的信息和知识显现出来,但数据挖掘的根本目标是将信息和知识以某种方式组织和呈现出来,并用来改善运营和提高效率。当然,在实际的数据挖掘工作中,根据不同的企业业务需求,模型发布的具体工作可能简单到提交数据挖掘报告,也可能复杂到将模型集成到企业的核心运营系统中去。
3、使用不当的坑
CRISP-DM是一个伟大的框架,它可以让项目组聚焦于挖掘真正的商业价值上。CRISP-DM路程已经存在有很长时间了,许多使用CRISP-DM流程的项目常常会走捷径,这些捷径中的有一些是有意义的,但捷径往往会导致项目使用不完整的流程,如下图所示:
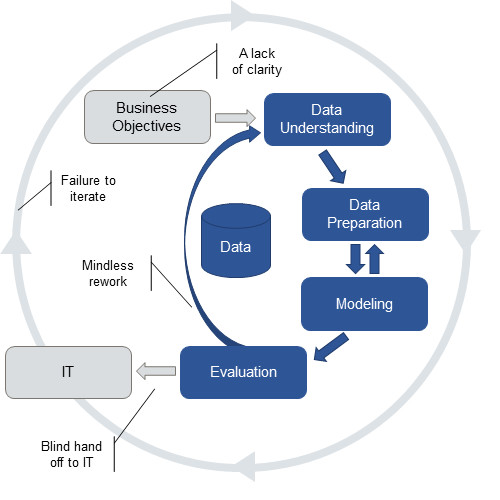
这种不完整的CRISP-DM流程存在四个问题,具体包括:
1. 业务目标不清晰:
不能一开始就陷入细节,应该真正去了解业务问题以及明确一个模型可以发挥什么作用,确定项目团队的业务目标和提出衡量项目成功的指标。“理解”了业务目标,团队想把工作负担最小化,就跳入项目的最有趣的部分--分析数据,但这样做只产出有趣的模型,而不能满足真正的商业需要。
2. 盲目地返工:
一些分析团队只用分析术语来评估他们的模型,认为如果模型只要做到可预测,那么它就是一个好的模型。大多数人通常可以意识到模型是有问题的,就会尝试检查他们的模型是否符合业务目标。但如果缺乏对商业问题的充分认识,这样的检查往往是非常困难的。如果他们开发的模型不符合业务需求,此时团队几乎没得选择,此时大多数人是在尝试找到新数据或新的建模技术,而不是与他们的业务合作伙伴一起重新评估业务问题。
3. 盲目地部署:
一些分析团队根本不考虑他们模型的部署和操作的易用性。做得好些的团队可以认识到他们构建的模型必将处理实时数据,数据通常存储在数据库中,或嵌在式操作系统中。即使是这样的团队通常也没有参与到部署工作中,不清楚模型是如何部署的,并不把部署当做分析工作的一部分,结果就是模型直接丢给IT团队去部署,模型是否容易部署、以及在生产环境是否可用都是别人的问题。这增加了模型部署的时间和成本,并产生了大量从未对业务产生影响模型。
4. 无法形成迭代:
分析专家了解模型的生命周期,为了保证模型的可用性,需要对模型保持更新。他们知道随着商业环境变化,模型的价值会改变,驱动模型的数据模式可能会改变。但他们认为这是另一个时间点的问题。由于他们缺少对业务问题的足够认识,往往难以确定如何评估模型的表现,相比模型建立阶段,他们在模型迭代、修改上的投入更少。毕竟解决另一个新问题更有趣。这使得老的模型不受监控和保护,从而破坏了模型的长期价值。
以上任一问题都可能使构建出来的模型毫无商业价值,真正需要利用分析的组织,特别是数据挖掘、预测和机器学习等更高级的分析,必须避免这些问题。
解决这些问题需要明确、清晰地关注决策,围绕着决策展开,包括需要改善的决策方法,改善意味着什么,做能实际改善决策的分析模型,设计可以辅助决策的系统,还需要明确在怎样的外部环境下需要重新评估模型。
参考文章:
5、CRISP-DM1.0循序渐进数据挖掘指南.pdf或者链接
数据挖掘的标准流程-CRISP-DM的更多相关文章
- 利用DM工具Weka进行数据挖掘(分类)的完整过程
利用DM工具Weka进行数据挖掘(分类)的完整过程:
- 【原创】数据挖掘案例——ReliefF和K-means算法的医学应用
数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的.事先未知 ...
- AI,DM,ML,PR的区别与联系
数据挖掘和机器学习的区别和联系,周志华有一篇很好的论述<机器学习与数据挖掘>可以帮助大家理解.数据挖掘受到很多学科领域的影响,其中数据库.机器学习.统计学无疑影响最大.简言之,对数据挖掘而 ...
- DB、ETL、DW、OLAP、DM、BI关系结构图
DB.ETL.DW.OLAP.DM.BI关系结构图 在此大概用口水话简单叙述一下他们几个概念: (1)DB/Database/数据库——这里一般指的就是OLTP数据库,在线事物数据库,用来支持生产的, ...
- 財哥面京东dm的经历【帮財哥发的】
关于面京东,感触仅仅有一个,虐的快吐血了.首先说京东分四个板块,有京东商城.京东金融.京东刚收购的拍拍和海外事业部.我这个职位主要是在金融部数据组做数据挖掘和机器学习,还有推荐系统.面试是在周 ...
- SPSS Modeler数据挖掘项目实战(数据挖掘、建模技术)
SPSS Modeler是业界极为著名的数据挖掘软件,其前身为SPSS Clementine.SPSS Modeler内置丰富的数据挖掘模型,以其强大的挖掘功能和友好的操作习惯,深受用户的喜爱和好评, ...
- 初试weka数据挖掘
初试weka数据挖掘 Posted on 2013-09-07 13:26 DM张朋飞 阅读(321) 评论(7) 编辑 收藏 偶然间在网上看到了一篇关于weka好的博文,就记录了下来…… weka下 ...
- 数据仓库分层ODS DW DM 主题 标签
数据仓库知识之ODS/DW/DM - xingchaojun的专栏 - CSDN博客 数据仓库为什么要分层 - 晨柳溪 - 博客园 数据仓库的架构与设计 - Trigl的博客 - CSDN博客 数据仓 ...
- DB、ETL、DW、OLAP、DM、BI关系 ZT
在此大概用口水话简单叙述一下他们几个概念: (1)DB/Database/数据库——这里一般指的就是OLTP数据库,在线事物数据库,用来支持生产的,比如超市的买卖系统.DB保留的是数据信息的最新状态, ...
随机推荐
- Qt5 入门
main()函数中第一句是创建一个QApplication类的实例. 对于 Qt 程序来说,main()函数一般以创建 application 对象(GUI 程序是QApplication,非 GUI ...
- python 文件下载
为了演示urllib3的使用,我们这里将会从一个网站下载两个文件.首先,需要导入urllib3库: import urllib3 这两个文件的源url为: url1 = 'http://earthqu ...
- Codeforces1023F Mobile Phone Network 【并查集】【最小生成树】
题目大意: 给一些没安排权值的边和安排了权值的边,没被安排的边全要被选入最小生成树,问你最大能把它们的权值和安排成多少.题目分析:假设建好了树,那么树边与剩下的每一条边都能构成一个环,并且非树边的权值 ...
- SpringMVC 集成Log4j
项目地址:https://github.com/xiaoqiu-duan/DataProject.git 1.添加jar <dependency> <groupId>org.s ...
- bzoj 3626 : [LNOI2014]LCA (树链剖分+线段树)
Description 给出一个n个节点的有根树(编号为0到n-1,根节点为0).一个点的深度定义为这个节点到根的距离+1.设dep[i]表示点i的深度,LCA(i,j)表示i与j的最近公共祖先.有q ...
- requirements文件
将一个环境中安装的所有的包在另一个环境中安装 1.生成文件列表 pip freeze > requirements.txt 2.将该文件放入到新环境中,安装 pip install -r req ...
- 2018蓝桥杯 省赛D题(测试次数)
x星球的居民脾气不太好,但好在他们生气的时候唯一的异常举动是:摔手机.各大厂商也就纷纷推出各种耐摔型手机.x星球的质监局规定了手机必须经过耐摔测试,并且评定出一个耐摔指数来,之后才允许上市流通.x星球 ...
- Android 架构 -- Room
gradle依赖: // add for room implementation "android.arch.persistence.room:runtime:1.1.1" // ...
- 这些保护Spring Boot 应用的方法,你都用了吗?
这些保护Spring Boot 应用的方法,你都用了吗? 生如夏花 SpringForAll社区 今天 Spring Boot大大简化了Spring应用程序的开发.它的自动配置和启动依赖大大减少了开始 ...
- [bzoj3524][Couriers]
题目链接 思路 观察这个\((r - l + 1)/2\),很容易证明,如果一个数出现次数大于\((r - l + 1) / 2\),那么这个区间内第\((r - l + 1) / 2 + 1\)大一 ...