logstash日志采集工具的安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上
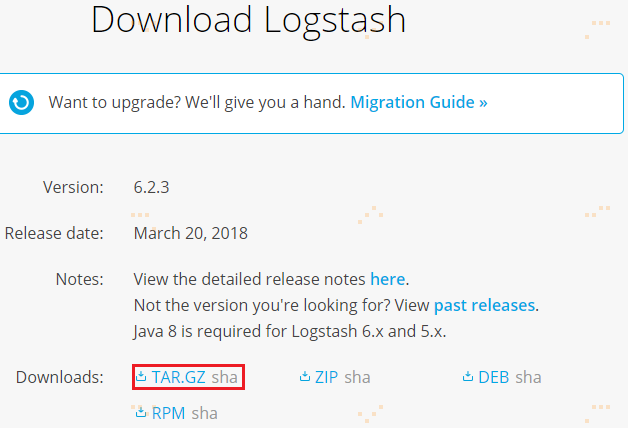
下载logstash-6.2.3.tar.gz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads/目录:

2、解压logstash-6.2.3.tar.gz,并把解压的安装包移动到/opt/app/目录上
tar zxvf logstash-6.2.3.tar.gz

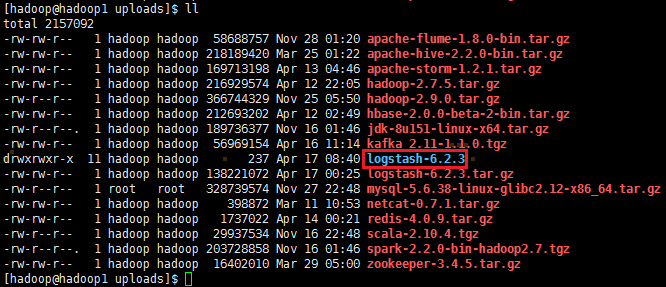
mv logstash-6.2.3 /opt/app/ && cd /opt/app/
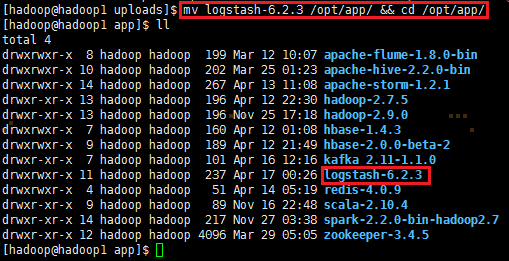
3、修改环境变量,编辑/etc/profile,并生效环境变量,输入如下命令:
sudo vi /etc/profile
添加如下内容:
export LOGSTASH_HOME=/opt/app/logstash-6.2.3
export PATH=:$PATH:$LOGSTASH_HOME/bin
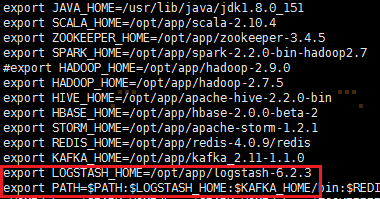
使环境变量生效:source /etc/profile
4、配置文件类型
4.1 log-kafka配置文件
输入源为nginx的日志文件,输出源为kafka
input {
file {
path => "/var/logs/nginx/*.log"
discover_interval => 5
start_position => "beginning"
}
}
output {
kafka {
topic_id => "accesslog"
codec => plain {
format => "%{message}"
charset => "UTF-8"
}
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
}
4.2 file-kafka配置文件
输入源为txt文件,输出源为kafka
input {
file {
codec => plain {
charset => "GB2312"
}
path => "D:/GameLog/BaseDir/*/*.txt"
discover_interval => 30
start_position => "beginning"
}
}
output {
kafka {
topic_id => "gamelog"
codec => plain {
format => "%{message}"
charset => "GB2312"
}
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
}
4.3 log-elasticsearch配置文件
输入源为nginx的日志文件,输出源为elasticsearch
input {
file {
type => "flow"
path => "var/logs/nginx/*.log"
discover_interval => 5
start_position => "beginning"
}
}
output {
if [type] == "flow" {
elasticsearch {
index => "flow-%{+YYYY.MM.dd}"
hosts => ["hadoop1:9200", "hadoop2:9200", "hadoop3:9200"]
}
}
}
4.4 kafka-elasticsearch配置文件
输入源为kafka的accesslog和gamelog主题,并在中间分别针对accesslog和gamelog进行过滤,输出源为elasticsearch。当input里面有多个kafka输入源时,client_id => "es*"必须添加且需要不同,否则会报错javax.management.InstanceAlreadyExistsException: kafka.consumer:type=app-info,id=logstash-0。
input {
kafka {
type => "accesslog"
codec => "plain"
auto_offset_reset => "earliest"
client_id => "es1"
group_id => "es1"
topics => ["accesslog"]
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
kafka {
type => "gamelog"
codec => "plain"
auto_offset_reset => "earliest"
client_id => "es2"
group_id => "es2"
topics => ["gamelog"]
bootstrap_servers => "hadoop1:9092,hadoop2:9092,hadoop3:9092"
}
}
filter {
if [type] == "accesslog" {
json {
source => "message"
remove_field => ["message"]
target => "access"
}
}
if [type] == "gamelog" {
mutate {
split => { "message" => " " }
add_field => {
"event_type" => "%{message[3]}"
"current_map" => "%{message[4]}"
"current_x" => "%{message[5]}"
"current_y" => "%{message[6]}"
"user" => "%{message[7]}"
"item" => "%{message[8]}"
"item_id" => "%{message[9]}"
"current_time" => "%{message[12]}"
}
remove_field => ["message"]
}
}
}
output {
if [type] == "accesslog" {
elasticsearch {
index => "accesslog"
codec => "json"
hosts => ["hadoop1:9200","hadoop2:9200","hadoop3:9200"]
}
}
if [type] == "gamelog" {
elasticsearch {
index => "gamelog"
codec => plain {
charset => "UTF-16BE"
}
hosts => ["hadoop1:9200","hadoop2:9200","hadoop3:9200"]
}
}
}
注:UTF-16BE为解决中文乱码,而不是UTF-8
5、logstash启动
logstash -f /opt/app/logstash-6.2.3/conf/flow-kafka.conf

6、logstash遇到的问题
1) 在使用logstash采集日志时,如果我们采用file为input类型,采用不能反复对一份文件进行测试!第一次会成功,之后就会失败!
参考资料:
https://blog.csdn.net/lvyuan1234/article/details/78653324
logstash日志采集工具的安装部署的更多相关文章
- 日志采集客户端 filebeat 安装部署
linux----------------1. 下载wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.5.1- ...
- filebeat + logstash 日志采集链路配置
1. 概述 一个完整的采集链路的流程如下: 所以要进行采集链路的部署需要以下几个步聚: nginx的配置 filebeat部署 logstash部署 kafka部署 kudu部署 下面将详细说明各个部 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- docker可视化集中管理工具shipyard安装部署
docker可视化集中管理工具shipyard安装部署 Shipyard是在Docker Swarm实现对容器.镜像.docker集群.仓库.节点进行管理的web系统. 1.Shipyard功能 Sh ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- flume 日志采集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- 运维工具Ansible安装部署
http://blog.51cto.com/liqingbiao/1875921 centos7安装部署ansible https://www.cnblogs.com/bky185392793/p/7 ...
- 日志采集工具Flume的安装与使用方法
安装Flume,参考厦门大学林子雨教程:http://dblab.xmu.edu.cn/blog/1102/ 并完成案例1 1.案例1:Avro source Avro可以发送一个给定的文件给Flum ...
- Filebeat轻量级日志采集工具
Beats 平台集合了多种单一用途数据采集器.这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据. 一.架构图 此次试验基于前几 ...
随机推荐
- Netty如何实现Reactor模式
在前面的文章中(Reactor模型详解),我们讲解了Reactor模式的各种演变形式,本文主要讲解的则是Netty是如何实现Reactor模式的.这里关于Netty实现的Reactor模式,需要说明的 ...
- Hdoj 2501.Tiling_easy version 题解
Problem Description 有一个大小是 2 x n 的网格,现在需要用2种规格的骨牌铺满,骨牌规格分别是 2 x 1 和 2 x 2,请计算一共有多少种铺设的方法. Input 输入的第 ...
- 自学Python4.8-生成器(方式二:生成器表达式)
自学Python之路-Python基础+模块+面向对象自学Python之路-Python网络编程自学Python之路-Python并发编程+数据库+前端自学Python之路-django 自学Pyth ...
- Centos 7下下载和安装docker
sudo yum install -y device-mapper sudo modprobe dm_mod ls -l /sys/class/misc/device-mapper sudo rpm ...
- Cannot set property 'innerHTML' of null
异常处理汇总-前端系列 http://www.cnblogs.com/dunitian/p/4523015.html 看如下错误代码: 知道是加载的问题就好解决了
- 使用 Spring Cloud Stream 构建消息驱动微服务
相关源码: spring cloud demo 微服务的目的: 松耦合 事件驱动的优势:高度解耦 Spring Cloud Stream 的几个概念 Spring Cloud Stream is a ...
- 第二十九节,目标检测算法之R-CNN算法详解
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmenta ...
- free(): invalid next size (fast): 0x000000xxx
记录一次错误,一开始看到这个错误,第一反应是不是释放了两次,后来检测绝对没有,然后又检查了下是不是new/malloc和delete/free没配对, 发现也不是,最后是发现new[x]中x是0的缘故 ...
- session/cookie/token
1.cookie是把登录信息存放在客户端 2.session是把登录信息存放在服务器 3.token是在登录的时候服务器提供一个令牌标识,可以存放在local storage,请求资源时带上token ...
- Gym 101911F “Tickets”
传送门 题意: 给你一个由六位数字组成的门票编码x,并定义F(x) = | 前三位加和 - 后三位加和|: 求出给定的门票编码 x 之前并且 F(i) < F(x) 的 i 的总个数. 题解: ...