flume常见异常汇总以及解决方案
flume常见异常汇总以及解决方案
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
实际生产环境中,我用flume将kafka的数据定期的往hdfs集群中上传数据,也遇到过一系列的坑,我在这里做个记录,如果你也遇到同样的错误,可以参考一下我的解决方案。
1>.服务器在接收到响应之前断开连接。
报错信息如下:
Caused by: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
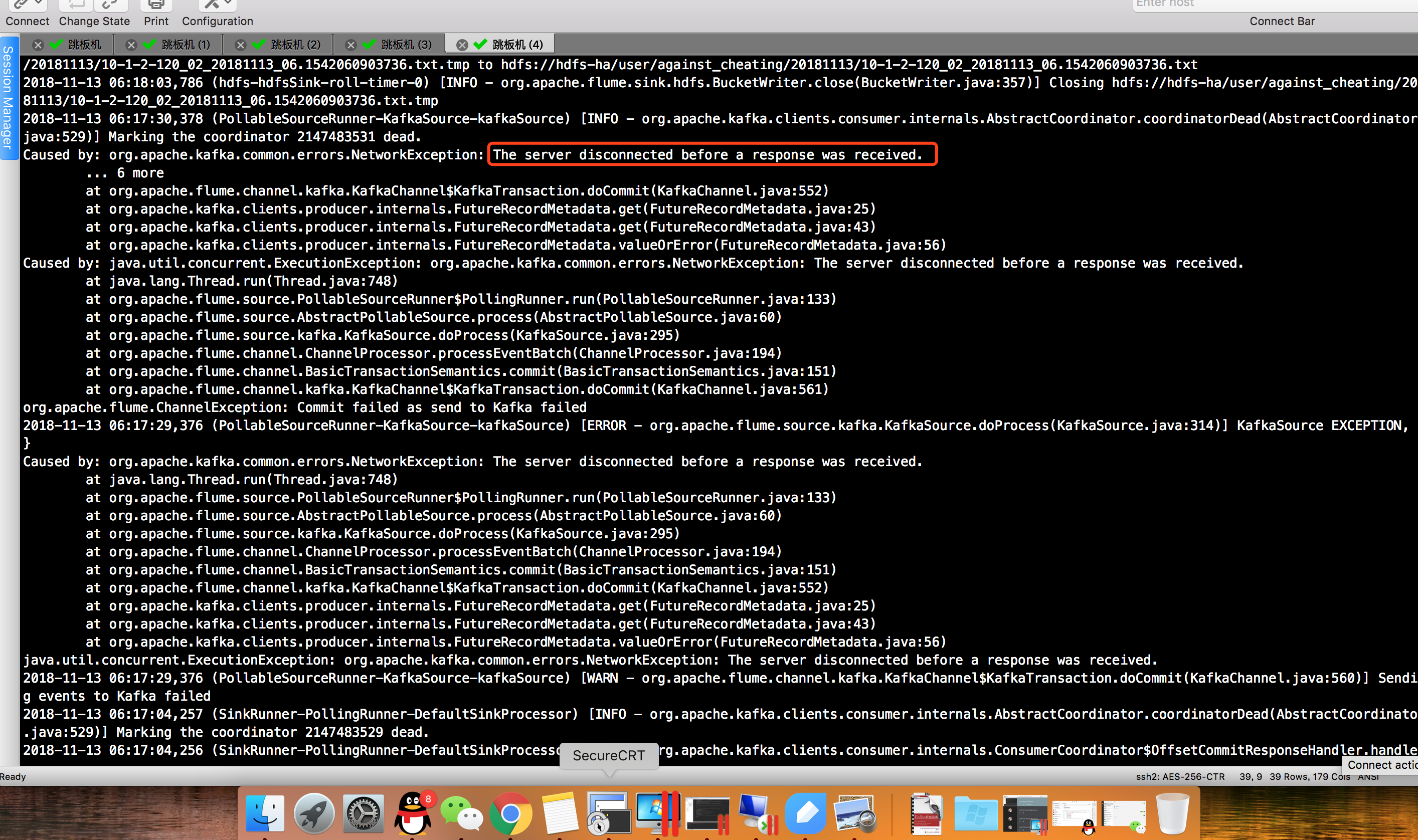
-- ::, (PollableSourceRunner-KafkaSource-kafkaSource) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:)] Marking the coordinator dead.
Caused by: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
... more
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:)
Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
at java.lang.Thread.run(Thread.java:)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
org.apache.flume.ChannelException: Commit failed as send to Kafka failed
-- ::, (PollableSourceRunner-KafkaSource-kafkaSource) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)] KafkaSource EXCEPTION, {}
Caused by: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
at java.lang.Thread.run(Thread.java:)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:)
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
-- ::, (PollableSourceRunner-KafkaSource-kafkaSource) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)] Sending events to Kafka failed
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:)] Marking the coordinator dead.
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:)] Offset commit for group flume-consumer-against_cheating_02 failed due to REQUEST_TIMED_OUT, will find new coordinator and retry
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:)] Marking the coordinator dead.
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:)] Offset commit for group flume-consumer-against_cheating_02 failed due to REQUEST_TIMED_OUT, will find new coordinator and retry
Offset commit for group flume-consumer-against_cheating_02 failed due to REQUEST_TIMED_OUT, will find new coordinator and retry
根据报错分析,是由于时间过长导致重新均衡的,参考:https://kafka.apache.org/090/documentation/#configuration,经查阅资料应该调大以下几个参数:
注意,这个*表示的是channels的名称,这些参数不仅仅是可以给kafka channel设置,还可以给kafka source配置哟! #配置控制服务器等待追随者确认以满足生产者用acks配置指定的确认要求的最大时间量。如果超时后所请求的确认数不满足,将返回一个错误。此超时在服务器端进行测量,不包括请求的网络延迟。
agent.channels.*.kafka.consumer.timeout.ms = #配置控制客户端等待请求响应的最大时间量。如果在超时之前没有接收到响应,则客户端将在必要时重新发送请求,或者如果重试用尽,则请求失败。
agent.channels.*.kafka.consumer.request.timeout.ms = #如果没有足够的数据立即满足fetch.min.bytes给出的要求,服务器在回答获取请求之前将阻塞的最大时间。
agent.channels.*.kafka.consumer.fetch.max.wait.ms= #在取消处理和恢复要提交的偏移数据之前,等待记录刷新和分区偏移数据提交到偏移存储的最大毫秒数。
agent.channels.*.kafka.consumer.offset.flush.interval.ms = #用于在使用kafka组管理设施时检测故障的超时时间。
agent.channels.*.kafka.consumer.session.timeout.ms = #使用kafka组管理设施时,消费者协调器心跳的预期时间。心跳用于确保消费者的会话保持活跃,并在新消费者加入或离开组时促进重新平衡。该值必须设置为低于session.timeout.ms,但通常应设置为不高于该值的1/。它可以调整得更低,以控制正常再平衡的预期时间。
agent.channels.*.kafka.consumer.heartbeat.interval.ms = #如果是true,消费者的偏移将在后台周期性地提交。如果auto.commit.enable=true,当consumer fetch了一些数据但还没有完全处理掉的时候,刚好到commit interval出发了提交offset操作,接着consumer crash掉了。这时已经fetch的数据还没有处理完成但已经被commit掉,因此没有机会再次被处理,数据丢失。
agent.channels.*.kafka.consumer.enable.auto.commit = false
2>.producer在向kafka broker写的时候,刚好发生选举,本来是向broker0上写的,选举之后broker1成为leader,所以无法写成功,就抛异常了。
报错信息如下:
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition. 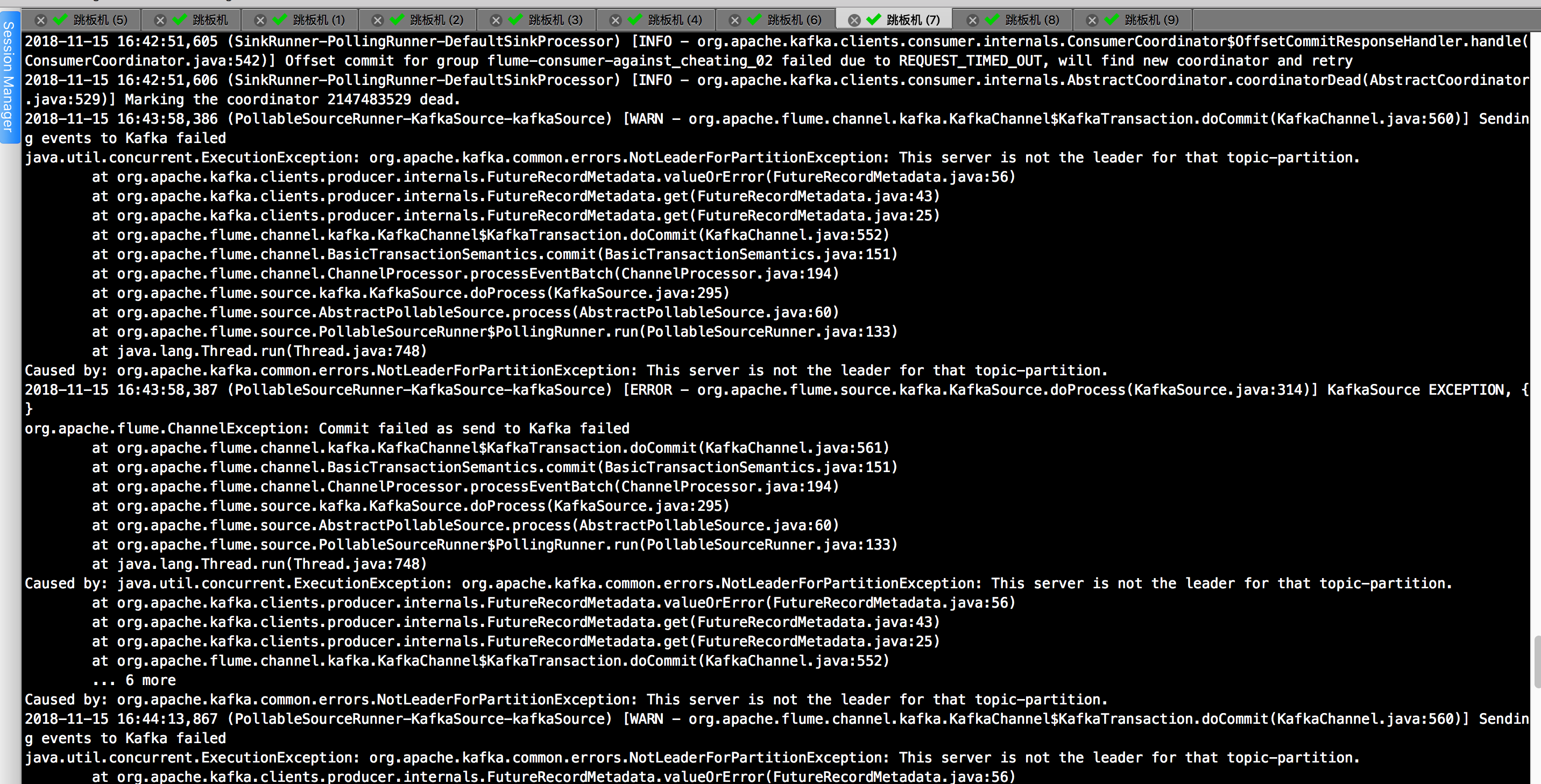
以上报错是我在重启kafka集群中发现的报错,百度了一下说是:producer在向kafka broker写的时候,刚好发生选举,本来是向broker0上写的,选举之后broker1成为leader,所以无法写成功,就抛异常了。
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:)] Creating hdfs://hdfs-ha/user/against_cheating/20181115/10-1-2-120_02_20181115_16.1542271273895.txt.tmp
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:)] Offset commit for group flume-consumer-against_cheating_02 failed due to REQUEST_TIMED_OUT, will find new coordinator and retry
-- ::, (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.kafka.clients.consumer.internals.AbstractCoordinator.coordinatorDead(AbstractCoordinator.java:)] Marking the coordinator dead.
-- ::, (PollableSourceRunner-KafkaSource-kafkaSource) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)] Sending events to Kafka failed
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
-- ::, (PollableSourceRunner-KafkaSource-kafkaSource) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)] KafkaSource EXCEPTION, {}
org.apache.flume.ChannelException: Commit failed as send to Kafka failed
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
... more
Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
-- ::, (PollableSourceRunner-KafkaSource-kafkaSource) [WARN - org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)] Sending events to Kafka failed
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
-- ::, (PollableSourceRunner-KafkaSource-kafkaSource) [ERROR - org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)] KafkaSource EXCEPTION, {}
org.apache.flume.ChannelException: Commit failed as send to Kafka failed
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
at org.apache.flume.channel.BasicTransactionSemantics.commit(BasicTransactionSemantics.java:)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:)
at java.lang.Thread.run(Thread.java:)
Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:)
at org.apache.flume.channel.kafka.KafkaChannel$KafkaTransaction.doCommit(KafkaChannel.java:)
... more
Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
-- ::, (hdfs-hdfsSink-roll-timer-) [INFO - org.apache.flume.sink.hdfs.BucketWriter.close(BucketWriter.java:)] Closing hdfs://hdfs-ha/user/against_cheating/20181115/10-1-2-120_02_20181115_16.1542271273895.txt.tmp
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
解决方案就是:
1>.先确认kafka集群是否在稳定运行,如果kafka集群异常的话,这个报错会一致不断的发出来;
2>.如果刚刚重启集群的话,暂时先不高管它,flume会自动去重试,但是你也别闲着,查看kafka监控界面,观察是否有异常的现象,如果时间超过了2分钟还没有恢复,那你就得考虑是否是你的kafka集群出现问题了。
3>.指定在 DataNode 内外传输数据使用的最大线程数偏小。
报错信息如下:
java.io.IOException: Bad connect ack with firstBadLink as 10.1.1.120:50010
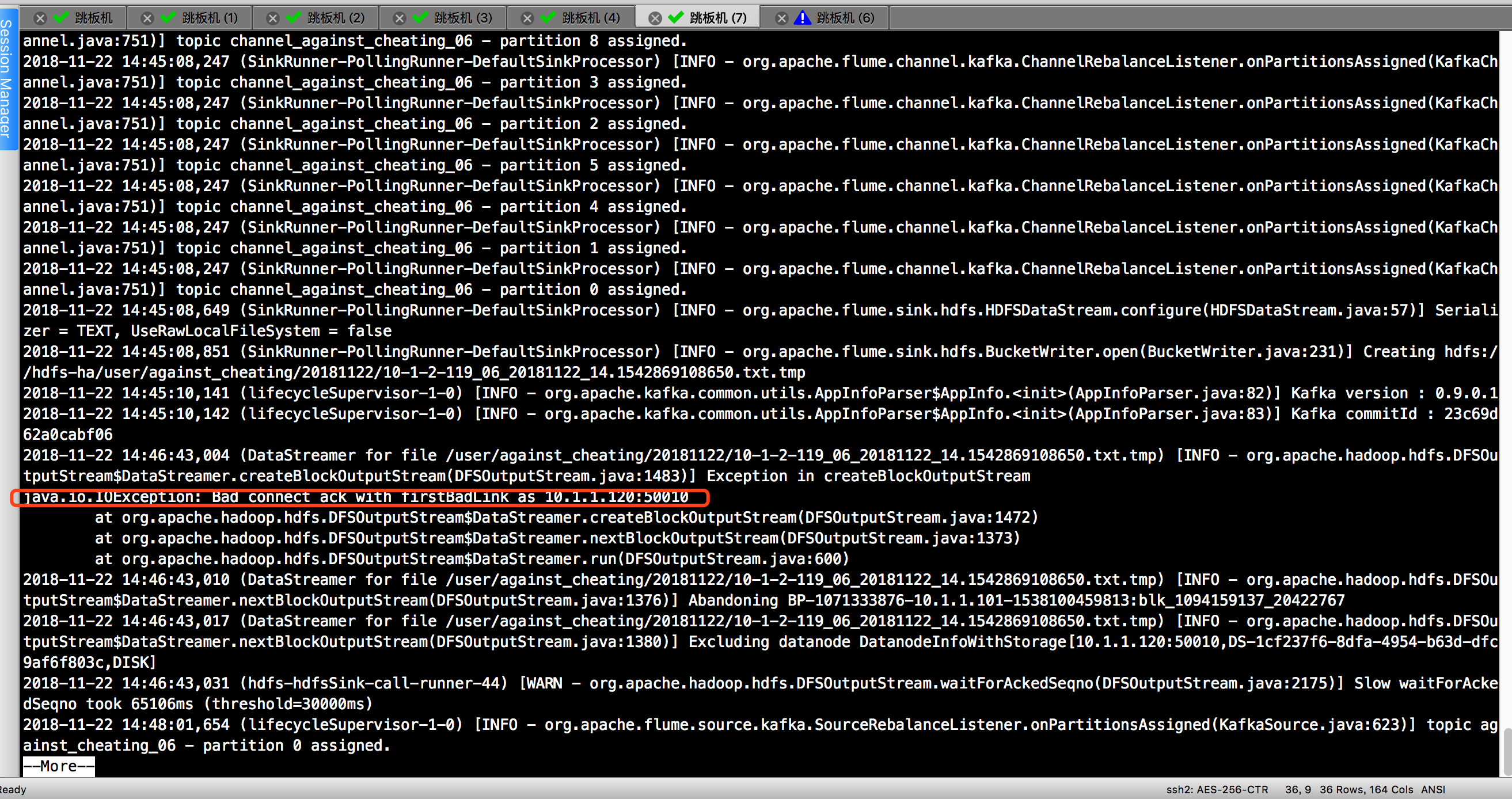
百度了一下原因:
Datanode往hdfs上写时,实际上是通过使用xcievers这个中间服务往linux上的文件系统上写文件的。其实这个xcievers就是一些负责在DataNode和本地磁盘上读,写文件的线程。DataNode上Block越多,这个线程的数量就应该越多。然后问题来了,这个线程数有个上线(默认是配置的4096)。所以,当Datenode上的Block数量过多时,就会有些Block文件找不到。线程来负责他的读和写工作了。所以就出现了上面的错误(写块失败)。
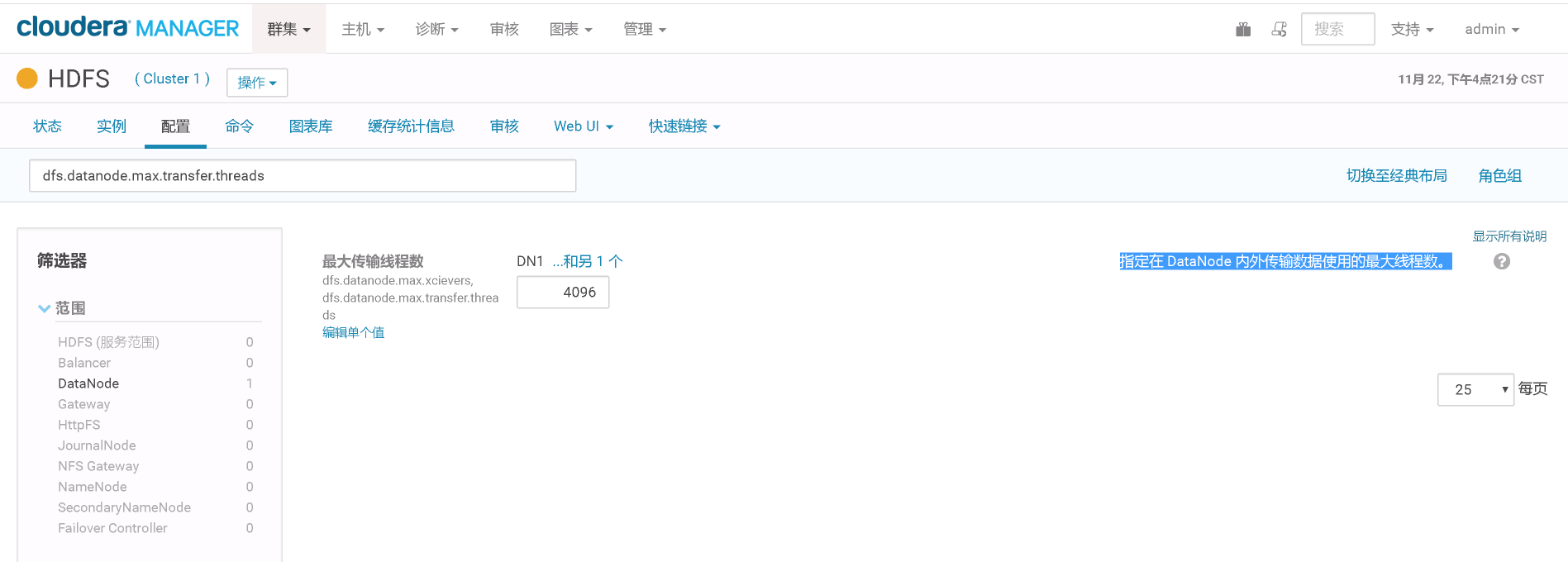
解决方案:
将DataNode 内外传输数据使用的最大线程数增大,比如:65535。

4>.java.io.EOFException: Premature EOF: no length prefix available
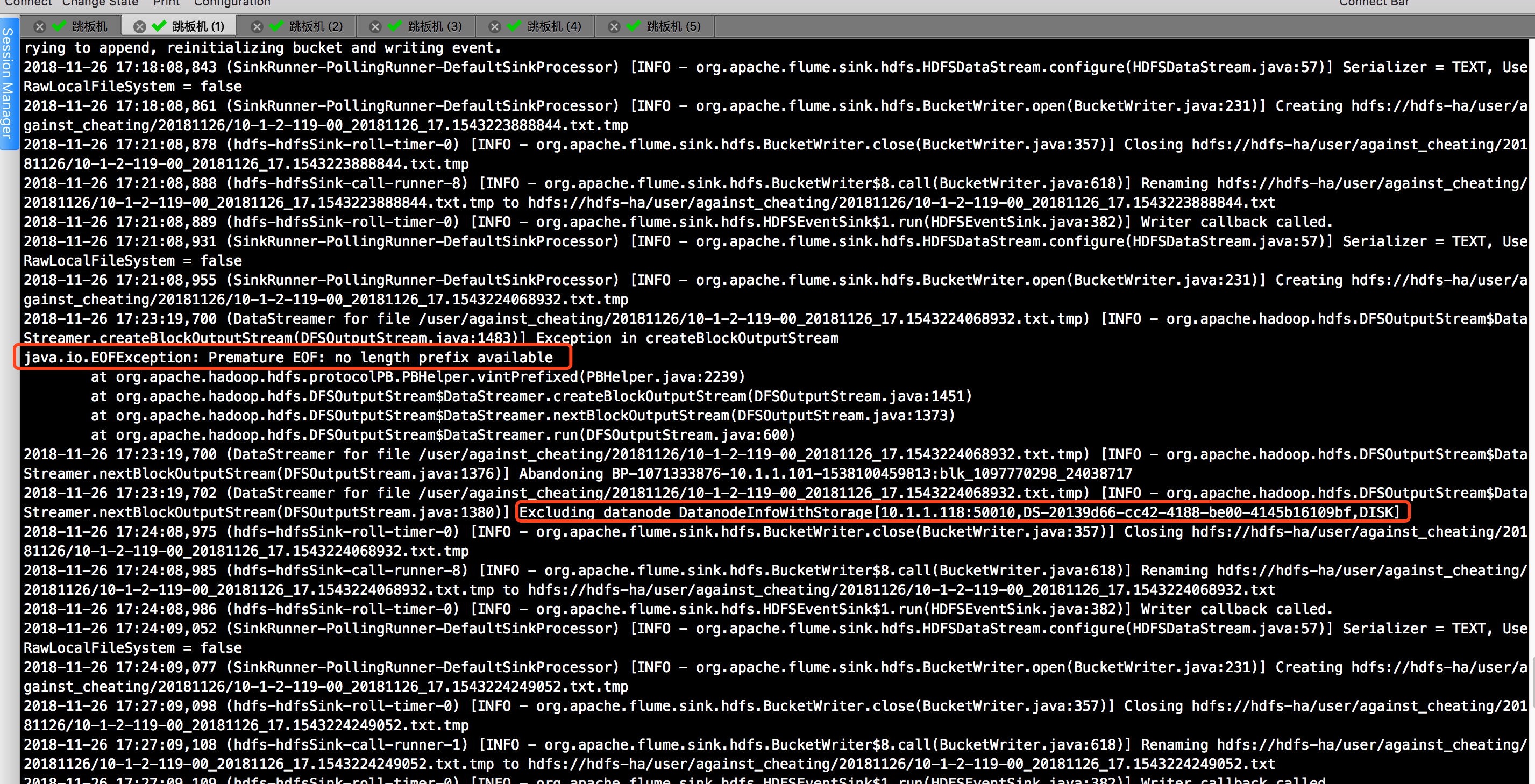
根据上图到提示,我们可以依稀看到DN节点,于是我们去CDH(如果你用到时HDP就去相应到平台即可)找相应到日志,发现的确有报错信息如下:
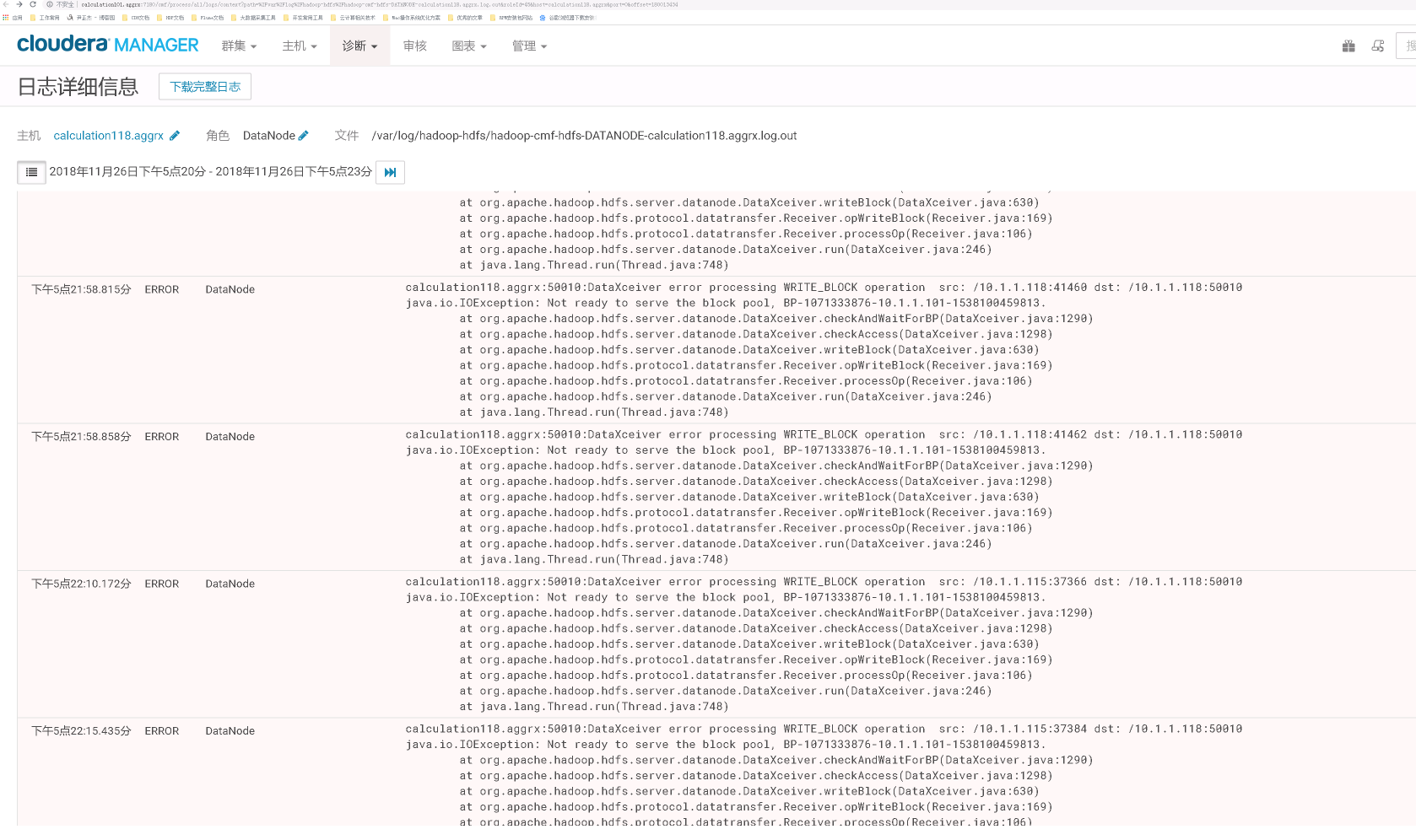
我遇到了上述的问题后我做了3给操作,最终问题得以解决:
第一步:调优hdfs集群,详细参数请参考我的笔记:https://www.cnblogs.com/yinzhengjie/p/10006880.html。
第二步:编辑了以下2个配置文件。
[root@calculation101 ~]# cat /etc/security/limits.d/-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz # for reasoning. * soft nproc
root soft nproc unlimited
[root@calculation101 ~]#
[root@calculation101 ~]# cat /etc/security/limits.d/20-nproc.conf
[root@calculation101 ~]# cat /etc/security/limits.conf | grep -v ^# | grep -v ^$
* soft nofile
* hard nofile
* soft nproc
* hard nproc unlimited
* soft memlock unlimited
* hard memlock unlimited
[root@calculation101 ~]#
[root@calculation101 ~]# cat /etc/security/limits.conf | grep -v ^# | grep -v ^$
第三步:重启操作系统,重启前确保所有的服务关闭,重启成功后,确保所有的hdfs集群启动成功,200G的数据只需要3分钟左右就跑完了,2天过去了,上述的报错依旧没有复现过,如果大家遇到跟我相同的问题,也可以试试我的这个方法。
5>.
flume常见异常汇总以及解决方案的更多相关文章
- struts2.1.8+hibernate2.5.6+spring3.0(ssh2三大框架)常见异常原因和解决方案
---------------------------------------------------------------------------------------------------- ...
- java中常见异常汇总(根据自己遇到的异常不定时更新)
1.java.lang.ArrayIndexOutOfBoundsException:N(数组索引越界异常.如果访问数组元素时指定的索引值小于0,或者大于等于数组的长度,编译程序不会出现任何错误,但运 ...
- Selenium常见异常分析及解决方案
pycharm中导入selenium报错 现象: pycharm中输入from selenium import webdriver, selenium标红 原因1: pycharm使用的虚拟环境中没有 ...
- kafka常见异常汇总
1>.java.lang.OutOfMemoryError:Map failed 发生上述问题,原因是发生OOM啦,会导致kafka进程直接崩溃掉!因此我们只能重新启动broker节点了,但 ...
- spark常见异常汇总
spark常见异常汇总 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 温馨提示: 如果开发运行spark出现问题啦,可能需要运维这边做一些调优,也可能是开发那边需要修改代码.到 ...
- IIS网站部署步骤以及常见异常解决方案
一. 简述 如果VS调试代码每次都使用浏览器打开,修改脚本和样式等还可以刷新页面显示最新修改,但是修改后台代码的话就需要停止调试再重新使用浏览器打开才能显示后台的最新修改,就比较麻烦.这里推荐附加到I ...
- salesforce 零基础学习(五十四)常见异常友好消息提示
异常或者error code汇总:https://developer.salesforce.com/docs/atlas.en-us.api.meta/api/sforce_api_calls_con ...
- 【转】Hibernate 常见异常
转载地址:http://smartan.iteye.com/blog/1542137 Hibernate 常见异常net.sf.hibernate.MappingException 当出 ...
- Spring10种常见异常解决方法
在程序员生涯当中,提到最多的应该就是SSH三大框架了.作为第一大框架的Spring框架,我们经常使用. 然而在使用过程中,遇到过很多的常见异常,我在这里总结一下,大家共勉. 一.找不到配置文件的异常 ...
随机推荐
- net core 2.0 + Autofac的坑
控制器不能从容器中解析出来; 只是控制器构造函数参数.这意味着控制器生命周期,属性注入和其他事情不由Autofac管理 - 它们由ASP.NET Core管理.可以通过指定AddControllers ...
- kubernetes Helm-chart web UI添加
charts web ui 添加chart仓库 helm repo add cherryleo https://fileserver-1253732882.cos.ap-chongqing.myqcl ...
- VM虚拟机截图方法介绍
可以先安装QQ之类的截图软件,但比较麻烦,而且截图之后还需要安装VMware Tools等工具才能拿到物理机上 先定向到物理机,快捷键为CTRL+ALT,之后在用qq截图快捷键ctrl+alt+a即可 ...
- I - Tunnel Warfare HDU - 1540 线段树最大连续区间
题意 :一段区间 操作1 切断点 操作2 恢复最近切断的一个点 操作3 单点查询该点所在最大连续区间 思路: 主要是push_up : 设区间x 为母区间 x<<1 ,x< ...
- spring05-Spring事务管理
事务的第一个方面是传播行为(propagation behavior).当事务方法被另一个事务方法调用时,必须指定事务应该如何传播.例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的 ...
- python中的replace()方法的使用
python中的replace()方法的使用 需求是这样的:需要将字符串的某些字符替换成其他字符 str.replace(old,new,max) 第一个参数是要进行更换的旧字符,第二个参数是新的子串 ...
- poi的cellstyle陷阱,样式覆盖
问题 cell.getCellStyle().setFont(font); 这句话本来只是想设置这一个单元格cell的字体样式,但是实际上却影响了很多个单元格的样式. 问题出在了,Excel模板中这些 ...
- 后台CRUD管理jqGrid 插件下载、使用、demo演示
jqGrid:demo?version=5.2.1download src: http://www.trirand.com/blog/ github:https://github.com/tonyto ...
- SCOI2016 Day1 简要题解
目录 「SCOI2016」背单词 题意 题解 代码 「SCOI2016」幸运数字 题意 题解 总结 代码 「SCOI2016」萌萌哒 题意 题解 总结 代码 「SCOI2016」背单词 题意 这出题人 ...
- SpringBoot 从application.yml中通过@Value读取不到属性值
package cn.exrick.xboot.mqtt; import org.eclipse.paho.client.mqttv3.*;import org.eclipse.paho.client ...