python:网络爬虫的学习笔记
如果要爬取的内容嵌在网页源代码中的话,直接下载网页源代码再利用正则表达式来寻找就ok了。下面是个简单的例子:
import urllib.request
html = urllib.request.urlopen('http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93536')
html = html.read().decode('utf-8')
注意,decode方法有时候可能会报错,例如
html = urllib.request.urlopen('http://china.nba.com/')
html = html.read().decode('utf-8')
Traceback (most recent call last):
File "<ipython-input-6-fc582e316612>", line 1, in <module>
html = html.read().decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 85: invalid continuation byte
具体原因不知道,可以用decode的一个参数,如下
html = html.read().decode('utf-8','replace')
html = urllib.request.urlopen('http://china.nba.com/')
html = html.read().decode('utf-8','replace')
html
Out[9]: '<!DOCTYPE html>\r\n<html>\r\n<head lang="en">\r\n <meta charset="UTF-8">\r\n <title>NBA�й��ٷ���վ</title>\r\n <meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1">\r\n <meta name="description" content="NBA�й��ٷ���վ">\r\n <meta name="keywords"
replace表示遇到不能转码的字符就将其替换成问号还是什么的。。。这也算是一个折中的方法吧。我们继续回到正题。假如说我们想爬取上面提到的网页的课程名称
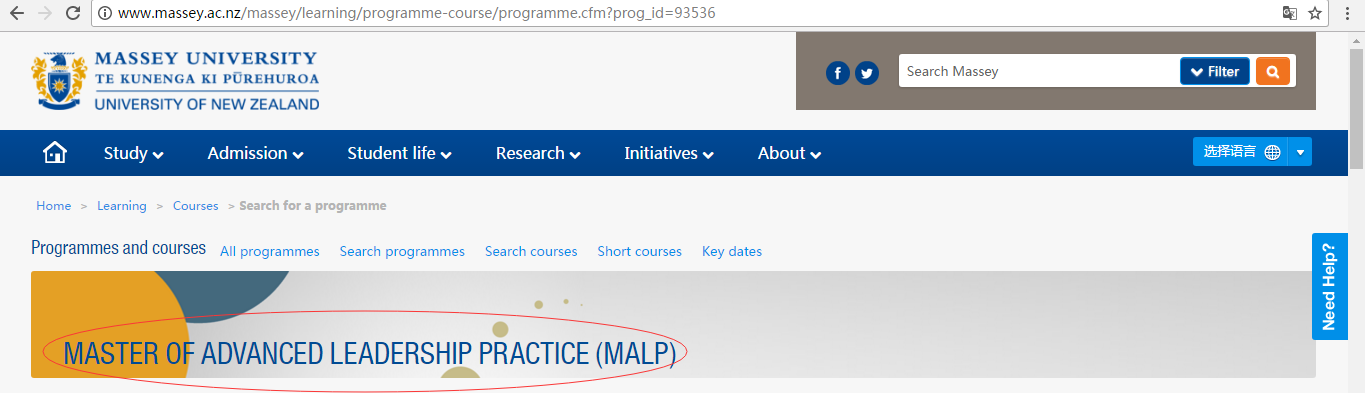
查看网页源代码。我用的谷歌浏览器,右键单击页面,再选择‘查看网页源代码’

再在这个页面上ctrl+F,查找你要爬取的字符:
这个就刚才截图所对应的代码(想看懂源代码还得学习一下html语言啊 http://www.w3school.com.cn/html/index.asp 这个网址挺不错的)
接下来就是用正则表达式把这个字符串扣下来了:
re.findall('<h1>.*?</h1>',html)
Out[35]: ['<h1>Master of Advanced Leadership Practice (<span>MALP</span>)</h1>']
剩下的就是对字符串的切割了:
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
course = course.replace('(<span>MALP</span>)</h1>','')
结果:
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
course = course.replace(' (<span>MALP</span>)</h1>','')
course
Out[40]: 'Master of Advanced Leadership Practice'
把它写成一个函数:
def get_course(url):
html = urllib.request.urlopen(url)
html = html.read().decode('utf-8')
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
course = course.replace(' (<span>MALP</span>)</h1>','')
return course
这样输入该学校的其他课程的网址,同样也能把那个课程的名称扣下来(语文不好,请见谅)
get_course('http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93059')
Out[48]: 'Master of Counselling Studies (<span>MCounsStuds</span>)</h1>'
这就很尴尬了,原因是第二个replace函数,pattern是错误的,看来还得用正则改一下
def get_course(url):
html = urllib.request.urlopen(url)
html = html.read().decode('utf-8')
course = re.findall('<h1>.*?</h1>',html)
course = str(course[0])
course = course.replace('<h1>','')
repl = str(re.findall(' \(<span>.*?</span>\)</h1>',course)[0])
course = course.replace(repl,'')
return course
再试试
get_course('http://www.massey.ac.nz/massey/learning/programme-course/programme.cfm?prog_id=93059')
Out[69]: 'Master of Counselling Studies'
搞定!
其实可以用BeautifulSoup直接解析源代码,使得查找定位更快。下一篇在说吧
这其实是我在广州第一份工作要干的活,核对网址是否存在,是否还是原来的课程。那个主管要人工核对。。。1000多个网址,他说他就是自己人工核对的,哈哈,我可不愿意干这活。当时也尝试用R语言去爬取课程名,试了很久。。。比较麻烦吧,后来学了python。现在要核对的话估计十分钟就能搞定1000多个网址了吧。就想装个b,大家可以无视
python:网络爬虫的学习笔记的更多相关文章
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 《用Python写爬虫》学习笔记(一)
注:纯文本内容,代码独立另写,属于本人学习总结,无任何商业用途,在此分享,如有错误,还望指教. 1.为什么需要爬虫? 答:目前网络API未完全放开,所以需要网络爬虫知识. 2.爬虫的合法性? 答:爬虫 ...
- 《Python网络编程》学习笔记--使用谷歌地理编码API获取一个JSON文档
Foundations of Python Network Programing,Third Edition <python网络编程>,本书中的代码可在Github上搜索fopnp下载 本 ...
- 《用Python写爬虫》学习笔记(二)编写第一个网络爬虫
1.首先,下载网页使用Python的urllib2模块,或者Python HTTP模块request来实现 urllib2会出现问题,解决方法1.重试下载(设置下载次数) 2.设置用户代理 2.其次, ...
- 《Python网络编程》学习笔记--从例子中收获的计算机网络相关知识
从之前笔记的四个程序中(http://www.cnblogs.com/take-fetter/p/8278864.html),我们可以看出分别使用了谷歌地理编码API(对URL表示地理信息查询和如何获 ...
- 《Python网络编程》学习笔记--UDP协议
第二章中主要介绍了UDP协议 UDP协议的定义(转自百度百科) UDP是OSI参考模型中一种无连接的传输层协议,它主要用于不要求分组顺序到达的传输中,分组传输顺序的检查与排序由应用层完成,提供面向事务 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
- 【python网络爬虫】之requests相关模块
python网络爬虫的学习第一步 [python网络爬虫]之0 爬虫与反扒 [python网络爬虫]之一 简单介绍 [python网络爬虫]之二 python uillib库 [python网络爬虫] ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
随机推荐
- JQ报错:Uncaught SyntaxError: Illegal continue statement: no surrounding iteration statement报错
今天在写轮播图中,在停止定时器之后想要重新开启定时器,但是不知道为什么脑子抽了竟然想通过continue跳出定时器的本次运行继续下一次运行(当然是不可取的,但是还是试了试2333),然后就报错了.Un ...
- winfrom---Window 消息大全
最近正在捣腾winfrom,遇到了关于window消息这一块的东西,正好在网上看到“微wx笑”的总结. 原文地址:http://blog.csdn.net/testcs_dn/article/deta ...
- 自定义springboot-starter
参考: https://juejin.im/entry/5b447cbbe51d45199566f752 https://www.baeldung.com/spring-boot-custom-sta ...
- python视频学习笔记6(名片管理系统开发)
cards_main.py主函数 cards_tools.py -------------------------------------------------------------------- ...
- OGG学习笔记02
实验环境:源端:192.168.1.30,Oracle 10.2.0.5 单实例目标端:192.168.1.31,Oracle 10.2.0.5 单实例 1.模拟源数据库业务持续运行 2.配置OGG前 ...
- web项目部署在centos 7验证码显示不出来解决方案
今天把项目部署在centos7上,发现验证码显示不出来,看了一下tomcat日志 Exception in thread "http-nio-8080-exec-3" java.l ...
- 入坑django2
数据模型 关于时间的字段设置 add_date = models.DateTimeField('保存日期',default = timezone.now) mod_date = models.Date ...
- mybatis-04【小结】
mybatis-04[小结] 1.Mybatis 中 # 和 $ 的区别?#相当于对数据 加上 双引号,$相当于直接显示数据1)#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号. 如:o ...
- deep_learning_Function_tf.equal(tf.argmax(y, 1),tf.argmax(y_, 1))用法
[Tensorflow] tf.equal(tf.argmax(y, 1),tf.argmax(y_, 1))用法 作用:输出正确的预测结果利用tf.argmax()按行求出真实值y_.预测值y最大值 ...
- 【PKUSC2018】星际穿越
被 scb 神仙教育来扫荡北大营题目 Orz Description https://loj.ac/problem/6435 Solution 首先有个很显然的性质,就是对于一组询问 \(l,r,x\ ...