用BERT做语义相似度匹配任务:计算相似度的方式
1. 自然地使用[CLS]
BERT可以很好的解决sentence-level的建模问题,它包含叫做Next Sentence Prediction的预训练任务,即成对句子的sentence-level问题。BERT也给出了此类问题的Fine-tuning方案:
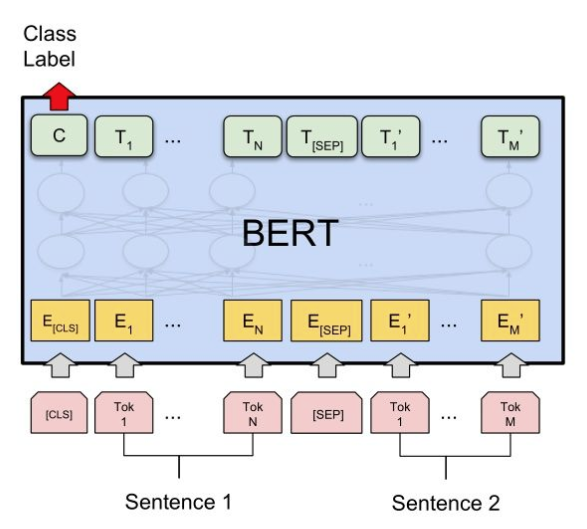
这一类问题属于Sentence Pair Classification Task.
计算相似度:
上图中,我们将输入送入BERT前,在首部加入[CLS],在两个句子之间加入[SEP]作为分隔。
然后,取到BERT的输出(句子对的embedding),取[CLS]即可完成多分类任务/相似度计算任务。
对应的:
假设我们取到的[CLS]对应的embedding为c,
多分类任务,需进行:P = softmax(cW')
相似度计算,需进行:P = sigmoid(cW')
然后,就可以去计算各自所需的loss了。
2. cosine similairity
单纯的做相似度匹配,这种方式需要优化。
在不finetune的情况下,cosine similairty绝对值没有实际意义。
bert pretrain计算的cosine similairty都是很大的,如果直接以cosine similariy>0.5之类的阈值来判断相似不相似那肯定效果很差。如果用做排序,也就是cosine(a,b)>cosine(a,c)->b相较于c和a更相似,是可以用的。
模型评价的标准应该使用auc,而不是accuracy。
3. 长短文本的区别
短文本(新闻标题)语义相似度任务用先进的word embedding(英文fasttext/glove,中文tencent embedding)mean pooling后的效果就已经不错;
而对于长文本(文章)用simhash这种纯词频统计的完全没语言模型的简单方法也可以。
4. sentence/word embedding
bert pretrain模型直接拿来用作 sentence embedding效果甚至不如word embedding,cls的emebdding效果最差(也就是pooled output)。把所有普通token embedding做pooling勉强能用(这个也是开源项目bert-as-service的默认做法),但也不会比word embedding更好。
5. siamese network 方式
除了直接使用bert的句对匹配之外,还可以只用bert来对每个句子求embedding,再通过向Siamese Network这样的经典模式去求相似度。
用siamese的方式训练bert,上层通过cosine做判别,能够让bert学习到一种适用于cosine作为最终相似度判别的sentence embedding,效果优于word embedding,但因为缺少sentence pair之间的特征交互,比原始bert sentence pair fine tune还是要差些。
参考Siamese bert:
用BERT做语义相似度匹配任务:计算相似度的方式的更多相关文章
- 转-------CNN图像相似度匹配 2-channel network
基于2-channel network的图片相似度判别 原文地址:http://blog.csdn.net/hjimce/article/details/50098483 作者:hjimce 一.相 ...
- Levenshtein计算相似度距离
使用Levenshtein计算相似度距离,装下模块,调用下函数就好. 拿idf还得自己去算权重,而且不一定准确度高,一般做idf还得做词性归一化,把动词形容词什么全部转成名词,很麻烦. Levensh ...
- 迷时师度,悟了自度(时间的边际效应),附VC参考书
12年前看过这篇文章,今天又看到了,还是有些感慨的.上课的时间虽然已经永远远去,用整块的时间去学习已经不可能,但道理还是要记着的,没准依然有用,自勉.------------------------- ...
- OSPF的特征、术语、包类型、邻居关系的建立、RID的选择、DR和BDR的选举、度量值的计算、默认路由、验证
链路状态路由协议OSPF的特征.术语.包类型.邻居关系的建立.RID的选择.DR和BDR的选举.度量值的计算.默认路由.验证等. 文章目录 [*1*].链路状态路由协议概述 工作过程 优缺点 [*2* ...
- 文本去重之MinHash算法——就是多个hash函数对items计算特征值,然后取最小的计算相似度
来源:http://my.oschina.net/pathenon/blog/65210 1.概述 跟SimHash一样,MinHash也是LSH的一种,可以用来快速估算两个集合的相似度.Mi ...
- C# Net 比较2个字符串的相似度(使用余弦相似度)
C# Net 比较2个字符串的相似度(使用余弦相似度) 复制代码使用: /// <summary> /// 比较2个字符串的相似度(使用余弦相似度) /// </summary> ...
- 双目立体匹配经典算法之Semi-Global Matching(SGM)概述:匹配代价计算之互信息(Mutual Information,MI)
半全局立体匹配算法Semi-Global Matching,SGM由学者Hirschmüller在2005年所提出1,提出的背景是一方面高效率的局部算法由于所基于的局部窗口视差相同的假设在很多情况 ...
- 基于MATLAB实现的云模型计算隶属度
”云”或者’云滴‘是云模型的基本单元,所谓云是指在其论域上的一个分布,可以用联合概率的形式(x, u)来表示 云模型用三个数据来表示其特征 期望:云滴在论域空间分布的期望,一般用符号Εx表示. 熵:不 ...
- Python 计算相似度
#计算相似度 #欧式距离 # npvec1, npvec2 = np.array(det_a), np.array(det_b) # similirity=math.sqrt(((npvec1 - n ...
随机推荐
- PostgreSQL 多版本的实现与Innodb和oracle的差别
PostgreSQL与oracle或InnoDB的多版本实现最大的区别在于最新版本和历史版本是否分离存储,PostgreSQL不分,而oracle和InnoDB分,而innodb也只是分离了数据,索引 ...
- 采用非常规方法(非gprecoverseg) 恢复greenplum数据库
greenplum数据库中mirror的作用就是作为primary的备份存在.那么恢复down掉的mirror或primary时,是否可以直接复制文件从primary或mirror到对应的mirror ...
- [NOI2010]超级钢琴 倍增
[NOI2010]超级钢琴 倍增 题面 暴力:枚举区间丢入堆\(O(n^2logn)\) 正解:考虑每次枚举和弦起点\(s\),那么以\(s\)为起点的和弦为\(sum[t]-sum[s](s+L-1 ...
- NodeJS后台
NodeJS后台 后台: 1.PHP 2.Java 3.Python 优势 1.性能 2.跟前台JS配合方便 3.NodeJS便于前端学习 https://nodejs.org/en/ 1.切换盘符 ...
- onPageScroll的使用
1. 2.
- 简单动态字符串-redis设计与实现
简单动态字符串 Sds (Simple Dynamic String,简单动态字符串)是 Redis 底层所使用的字符串表示, 几乎所有的 Redis 模块中都用了 sds. 本章将对 sds 的实现 ...
- Mininet系列实验(二):Mininet可视化应用
1 实验目的 该实验通过Mininet学习miniedit可视化操作,可直接在界面上编辑任意想要的拓扑,生成python自定义拓扑脚本,简单方便.在实验过程中,可以了解以下方面的知识: Miniedi ...
- php7的扩展库安装方法
转:https://www.cnblogs.com/to-be-rich/p/8001175.html 今天的知识点:1.php的再次编译不会对现有的php业务有影响,只有正式kill -USR2 p ...
- 技术干货丨如何在VIPKID中构建MQ服务
小结: 1. https://mp.weixin.qq.com/s/FQ-DKvQZSP061kqG_qeRjA 文 |李伟 VIPKID数据中间件架构师 交流微信 | datapipeline201 ...
- golang 循环创建闭包 问题排查
][]string{ { { "邀请码是什么", "我没有邀请码", "这个邀请码我可以随便填吗", "邀请码可以填他的手机号吗& ...