用BERT做语义相似度匹配任务:计算相似度的方式
1. 自然地使用[CLS]
BERT可以很好的解决sentence-level的建模问题,它包含叫做Next Sentence Prediction的预训练任务,即成对句子的sentence-level问题。BERT也给出了此类问题的Fine-tuning方案:
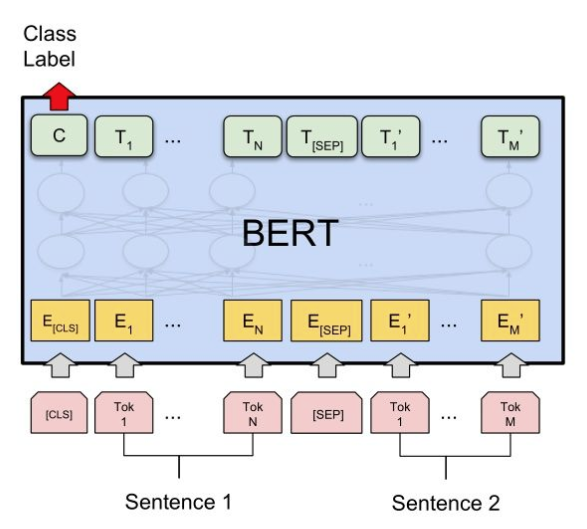
这一类问题属于Sentence Pair Classification Task.
计算相似度:
上图中,我们将输入送入BERT前,在首部加入[CLS],在两个句子之间加入[SEP]作为分隔。
然后,取到BERT的输出(句子对的embedding),取[CLS]即可完成多分类任务/相似度计算任务。
对应的:
假设我们取到的[CLS]对应的embedding为c,
多分类任务,需进行:P = softmax(cW')
相似度计算,需进行:P = sigmoid(cW')
然后,就可以去计算各自所需的loss了。
2. cosine similairity
单纯的做相似度匹配,这种方式需要优化。
在不finetune的情况下,cosine similairty绝对值没有实际意义。
bert pretrain计算的cosine similairty都是很大的,如果直接以cosine similariy>0.5之类的阈值来判断相似不相似那肯定效果很差。如果用做排序,也就是cosine(a,b)>cosine(a,c)->b相较于c和a更相似,是可以用的。
模型评价的标准应该使用auc,而不是accuracy。
3. 长短文本的区别
短文本(新闻标题)语义相似度任务用先进的word embedding(英文fasttext/glove,中文tencent embedding)mean pooling后的效果就已经不错;
而对于长文本(文章)用simhash这种纯词频统计的完全没语言模型的简单方法也可以。
4. sentence/word embedding
bert pretrain模型直接拿来用作 sentence embedding效果甚至不如word embedding,cls的emebdding效果最差(也就是pooled output)。把所有普通token embedding做pooling勉强能用(这个也是开源项目bert-as-service的默认做法),但也不会比word embedding更好。
5. siamese network 方式
除了直接使用bert的句对匹配之外,还可以只用bert来对每个句子求embedding,再通过向Siamese Network这样的经典模式去求相似度。
用siamese的方式训练bert,上层通过cosine做判别,能够让bert学习到一种适用于cosine作为最终相似度判别的sentence embedding,效果优于word embedding,但因为缺少sentence pair之间的特征交互,比原始bert sentence pair fine tune还是要差些。
参考Siamese bert:
用BERT做语义相似度匹配任务:计算相似度的方式的更多相关文章
- 转-------CNN图像相似度匹配 2-channel network
基于2-channel network的图片相似度判别 原文地址:http://blog.csdn.net/hjimce/article/details/50098483 作者:hjimce 一.相 ...
- Levenshtein计算相似度距离
使用Levenshtein计算相似度距离,装下模块,调用下函数就好. 拿idf还得自己去算权重,而且不一定准确度高,一般做idf还得做词性归一化,把动词形容词什么全部转成名词,很麻烦. Levensh ...
- 迷时师度,悟了自度(时间的边际效应),附VC参考书
12年前看过这篇文章,今天又看到了,还是有些感慨的.上课的时间虽然已经永远远去,用整块的时间去学习已经不可能,但道理还是要记着的,没准依然有用,自勉.------------------------- ...
- OSPF的特征、术语、包类型、邻居关系的建立、RID的选择、DR和BDR的选举、度量值的计算、默认路由、验证
链路状态路由协议OSPF的特征.术语.包类型.邻居关系的建立.RID的选择.DR和BDR的选举.度量值的计算.默认路由.验证等. 文章目录 [*1*].链路状态路由协议概述 工作过程 优缺点 [*2* ...
- 文本去重之MinHash算法——就是多个hash函数对items计算特征值,然后取最小的计算相似度
来源:http://my.oschina.net/pathenon/blog/65210 1.概述 跟SimHash一样,MinHash也是LSH的一种,可以用来快速估算两个集合的相似度.Mi ...
- C# Net 比较2个字符串的相似度(使用余弦相似度)
C# Net 比较2个字符串的相似度(使用余弦相似度) 复制代码使用: /// <summary> /// 比较2个字符串的相似度(使用余弦相似度) /// </summary> ...
- 双目立体匹配经典算法之Semi-Global Matching(SGM)概述:匹配代价计算之互信息(Mutual Information,MI)
半全局立体匹配算法Semi-Global Matching,SGM由学者Hirschmüller在2005年所提出1,提出的背景是一方面高效率的局部算法由于所基于的局部窗口视差相同的假设在很多情况 ...
- 基于MATLAB实现的云模型计算隶属度
”云”或者’云滴‘是云模型的基本单元,所谓云是指在其论域上的一个分布,可以用联合概率的形式(x, u)来表示 云模型用三个数据来表示其特征 期望:云滴在论域空间分布的期望,一般用符号Εx表示. 熵:不 ...
- Python 计算相似度
#计算相似度 #欧式距离 # npvec1, npvec2 = np.array(det_a), np.array(det_b) # similirity=math.sqrt(((npvec1 - n ...
随机推荐
- 078_使用 egrep 过滤 MAC 地址
#!/bin/bash#MAC 地址由 16 进制组成,如 AA:BB:CC:DD:EE:FF#[0-9a-fA-F]{2}表示一段十六进制数值,{5}表示连续出现 5 组前置:的十六进制egrep ...
- /dev/null和/dev/zero的作用
经常会看到dd命令用到/dev/zero文件,这里总结一下/dev/null和/dev/zero的作用和使用实例. 在类Unix系统(包括Linux)中,/dev/null 它是空设备,也称为位桶(b ...
- OpenFOAM中的基本变量快速认知【转载】
转载自:http://blog.sina.com.cn/s/blog_a0b4201d0102vsf9.html label 实际上就是整型数据的变体,int,OF对它进行了包装,以适应32或64位系 ...
- ICEM-轴(周期复制网格)
原视频下载地址:https://yunpan.cn/cqMnfpqQQdZZI 访问密码 802b
- Centos7 开启swap分区
阿里云购买的机器,默认不会开启swap分区,如有需要,需自行开启. 阿里当前的做法是: 1.不创建swap分区,由镜像决定 2.将vm.swappiness设定为0,即永不使用swap分区 开启swa ...
- 2018-2019-2 20165114《网络对抗技术》 Exp 8 Web基础
Exp 8 Web基础 目录 一.实验内容 二.基础问题回答 (1)什么是表单 (2)浏览器可以解析运行什么语言. (3)WebServer支持哪些动态语言 三.实践过程记录 3.1Web前端HTML ...
- PHP try catch 如何使用
<?php try { if (file_exists('test_try_catch.php')) { require ('test_try_catch.php'); } else { ...
- mysql的配置文件解释
1 在执行mysqld命令时,下列配置会生效,即mysql服务启动时生效 [mysqld] character_set_server=utf8collation-server=utf8_general ...
- Nginx可以说是标配组件,但是主要场景还是负载均衡、反向代理、代理缓存、限流等场景;而把Nginx作为一个Web容器使用的还不是那么广泛。
Nginx可以说是标配组件,但是主要场景还是负载均衡.反向代理.代理缓存.限流等场景:而把Nginx作为一个Web容器使用的还不是那么广泛. 用Nginx+Lua(OpenResty)开发高性能Web ...
- Redis操作类型