浅谈聚类算法(K-means)
聚类算法(K-means)目的是将n个对象根据它们各自属性分成k个不同的簇,使得簇内各个对象的相似度尽可能高,而各簇之间的相似度尽量小。
而如何评测相似度呢,采用的准则函数是误差平方和(因此也叫K-均值算法):
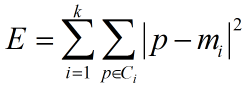 其中,E是数据集中所有对象的平方误差和,P是空间中的点,表示给定对象,mi为簇Ci的均值。其实E所代表的就是所有对象到其所在聚类中心的距离之和。对于不同的聚类,E的大小肯定是不一样的,因此,使E最小的聚类是误差平方和准则下的最优结果.
其中,E是数据集中所有对象的平方误差和,P是空间中的点,表示给定对象,mi为簇Ci的均值。其实E所代表的就是所有对象到其所在聚类中心的距离之和。对于不同的聚类,E的大小肯定是不一样的,因此,使E最小的聚类是误差平方和准则下的最优结果.
选取代表点用如下几个办法:
(1)凭经验。根据问题性质,用经验的方法确定类别个数,从数据中找出从直观上看来比较合适的代表点。
(2)将全部数据随机地分成k类,计算每类的中心,将这些点作为每类的代表点。
(3)“密度”选择法。这个方法思路还是比较巧妙。首先每个样本为球心,用某个正数a为半径画圈,被圈进来的样本数则成为球心样本点的“密度”。找出“密 度”最大的样本点作为第一类的代表点。然后开始选择第二类的代表点,这时不能直接选“密度”次大的代表点,因为次大的代表点很可能就在第一个代表点附近。 可以规定一个正数b,在第一个代表点范围b之外选择“密度”次大的代表点作为第二类的代表点,其余代表点按照这个原则依次进行。
(4)用K个样本作为代表点。
(5)采用用K-1聚类划分问题产生K聚类划分问题的代表点的方法。思路是先把所有数据看成一个聚类,其代表点为所有样本的均值,然后确定两聚类问题的代表点是一聚类问题划分的总均值和离它最远的代表点。余下的以此类推。
浅谈聚类算法(K-means)的更多相关文章
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 浅谈Manacher算法与扩展KMP之间的联系
首先,在谈到Manacher算法之前,我们先来看一个小问题:给定一个字符串S,求该字符串的最长回文子串的长度.对于该问题的求解.网上解法颇多.时间复杂度也不尽同样,这里列述几种常见的解法. 解法一 ...
随机推荐
- Java基础(下)(JVM、API)
Java基础(下) 第三部分:Java源程序的编辑 我们知道,计算机是不能直接理解源代码中的高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言编写的程序. 翻译 ...
- 浅谈HTML5中的浮动问题
浮动是我们在前端页面中经常会用到的一种布局方式.那什么是浮动呢? 首先我们先来看一下它的定义.浮动是指让元素脱离文档标准流(脱标),按照指定的方向去横向排列.浮动的取值有两个,分别是float:lef ...
- SEO-友情链接注意事项
为什么要专门给友链一个区域呢?由此就可以想象到友情链接对一个网站有多重要前期,网站没有权重的时候,跟别人换友链,人家基本是不会换的因为你网站没权重,加了友链他也获取不到权重,对网站没有多少好处一般我们 ...
- 关于xml中有特珠字符而导致XmlDocument无法Load的处理
这是个小事故导致的... 我们线上有个节目里名称里(`F`H9)MSTJXCX0B3J69,虽然我们看到是(`F`H9)MSTJXCX0B3J69,但百思不得其解,发现每次在XmlDocument.L ...
- 关于web测试收集
页面部分 页面清单是否完整(是否已经将所需要的页面全部都列出来了) 页面是否显示(在不同分辨率下页面是否存在,在不同浏览器版本中页面是是否显示) 页面在窗口中的显示是否正确.美观(在调整浏览器窗口大小 ...
- Spark结构式流编程指南
Spark结构式流编程指南 概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎.使用小量的静态数据模拟流处理.伴随流数据的到来,Spark ...
- jsp中九大内置对象
jsp实质是一个Servlet类,当jsp页面第一次被访问时,就会被服务器翻译成.java文件,紧接着就编译成.class文件. jsp<% %>和<%= %>脚本中可以直接使 ...
- 这是对position讲解最通俗易懂的版本了。
position 为了制作更多复杂的布局,我们需要讨论下 position 属性.它有一大堆的值,名字还都特抽象,别提有多难记了.让我们先一个个的过一遍,不过你最好还是把这页放到书签里. static ...
- Alamofire源码解读系列(九)之响应封装(Response)
本篇主要带来Alamofire中Response的解读 前言 在每篇文章的前言部分,我都会把我认为的本篇最重要的内容提前讲一下.我更想同大家分享这些顶级框架在设计和编码层次究竟有哪些过人的地方?当然, ...
- ios微信自动播放音乐
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8 ...