浅谈聚类算法(K-means)
聚类算法(K-means)目的是将n个对象根据它们各自属性分成k个不同的簇,使得簇内各个对象的相似度尽可能高,而各簇之间的相似度尽量小。
而如何评测相似度呢,采用的准则函数是误差平方和(因此也叫K-均值算法):
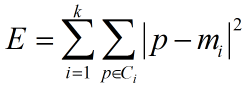 其中,E是数据集中所有对象的平方误差和,P是空间中的点,表示给定对象,mi为簇Ci的均值。其实E所代表的就是所有对象到其所在聚类中心的距离之和。对于不同的聚类,E的大小肯定是不一样的,因此,使E最小的聚类是误差平方和准则下的最优结果.
其中,E是数据集中所有对象的平方误差和,P是空间中的点,表示给定对象,mi为簇Ci的均值。其实E所代表的就是所有对象到其所在聚类中心的距离之和。对于不同的聚类,E的大小肯定是不一样的,因此,使E最小的聚类是误差平方和准则下的最优结果.
选取代表点用如下几个办法:
(1)凭经验。根据问题性质,用经验的方法确定类别个数,从数据中找出从直观上看来比较合适的代表点。
(2)将全部数据随机地分成k类,计算每类的中心,将这些点作为每类的代表点。
(3)“密度”选择法。这个方法思路还是比较巧妙。首先每个样本为球心,用某个正数a为半径画圈,被圈进来的样本数则成为球心样本点的“密度”。找出“密 度”最大的样本点作为第一类的代表点。然后开始选择第二类的代表点,这时不能直接选“密度”次大的代表点,因为次大的代表点很可能就在第一个代表点附近。 可以规定一个正数b,在第一个代表点范围b之外选择“密度”次大的代表点作为第二类的代表点,其余代表点按照这个原则依次进行。
(4)用K个样本作为代表点。
(5)采用用K-1聚类划分问题产生K聚类划分问题的代表点的方法。思路是先把所有数据看成一个聚类,其代表点为所有样本的均值,然后确定两聚类问题的代表点是一聚类问题划分的总均值和离它最远的代表点。余下的以此类推。
浅谈聚类算法(K-means)的更多相关文章
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 浅谈Manacher算法与扩展KMP之间的联系
首先,在谈到Manacher算法之前,我们先来看一个小问题:给定一个字符串S,求该字符串的最长回文子串的长度.对于该问题的求解.网上解法颇多.时间复杂度也不尽同样,这里列述几种常见的解法. 解法一 ...
随机推荐
- vSphere在RedHat6.0上搭建Oracle 11g R2 RAC环境
一.前期准备工作 1.1 为方便操作,装完系统后我们先安装Vmware Tools: 1.1.1.安装工具 在VMware的菜单栏上选择"虚拟机/安装虚拟机工具(VM/Install VMw ...
- oracle xe 数据库用户操作
在system账号登录获得system权限,然后对用户进行操作 --创建表空间create tablespace tablespace_name datafile 'D:\tablespace_nam ...
- C++ 容器对象vector和list 的使用
在<<c++ primer>>第四版Exercise Section 9.3.4 的Exercise 9.20 是这样的一道题目:编写程序判断一个vector<int&g ...
- Webstorm编译TypeScript报错
Accessors are only available when targeting ECMAscript 5 and higher. 解决办法: File Watchers 在tsc.cmd命令上 ...
- TensorFlow安装-ubuntu
windows下某些tensorflow例子跑不成功,比如https://www.tensorflow.org/tutorials/wide 中的例子报下面的错误:' 'NoneType' objec ...
- Angular2开发拙见——组件规划篇
本文集中讲讲笔者目前使用ng2来开发项目时对其组件的使用的个人的一些拙劣的经验. 先简单讲讲从ng1到ng2框架下组件的职责与地位: ng1中的一大特色--指令,分为属性型.标签型.css类型和注释型 ...
- 更全面的聊聊PRINCE2是什么
1 什么是PRINCE2®? PRINCE2是一个非专有方法,已在全世界超过150个国家广泛使用,采用它的组织正在与日俱增. 它被广泛认为是项目管理的领先方法,超过2万个组织已经从其开创性的可信方法中 ...
- 核心模块Path
核心模块Path 作用:用于帮助程序员来操作硬盘上的路径. 核心模块注意点:当引用核心模块的时候直接require('模块名'),不需要加任何路径或者后缀. Path中的常用API: dirname( ...
- So Easy-Ntp嵌入式软件移植
一.导语和准备工作 Ntp是一种对时的软件,对客户端来说我们只要输入ntpdate IP,如ntpdate 192.168.1.254(192.168.1.254是ntp服务器,window电脑激活自 ...
- 老李分享:持续集成学好jenkins之Git和Maven配置 1
老李分享:持续集成学好jenkins之Git和Maven配置 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣 ...