SQL Server 中统计信息直方图中对于没有覆盖到谓词预估以及预估策略的变化(SQL2012-->SQL2014-->SQL2016)
本文出处:http://www.cnblogs.com/wy123/p/6770258.html
统计信息写过几篇了相关的文章了,感觉还是不过瘾,关于统计信息的问题,最近又踩坑了,该问题虽然不算很常见,但也比较有意思。
相对SQL Server 2012,发现在新的SQL Server版本(2014,2016)中都有一些明显的变化,下文将对此进行粗浅的分析。
SQL Server 2012中(包括之前的版本),因表中数据变化,但统计信息尚未更新的情况下,对于直方图中没有覆盖到的谓词过滤时,sqlserver总是预估为1行
SQL Server 2014和 Server 2016中这种估算方式都有所变化,从表现看,对于对于没有覆盖到的谓词过滤的预估,每个版本都是不同的。
本文简单测试一下此种情况在SQL Server 2012,SQL Server 2014,SQL Server 2016的不同表现,以及该问题可能造成的潜在影响。
下面涉及到的测试环境的数据库版本如下


测试环境准备
首先利用如下脚本,建一张测试表,写入测试数据,下面会解释测试数据的分布
create table A
(
IdentifierId int identity(1,1),
Id1 int,
Id2 int,
OtherCol CHAR(500)
)
GO begin tran
declare @i int = 1
while @i<=1000000
begin
insert into A values ((@i/50000)+1,@i,NEWID())
set @i = @i+1
if (@i%500000)=0
begin
if @@TRANCOUNT>0
begin
commit
begin tran
end
end
end
if @@TRANCOUNT>0
begin
commit
end
GO
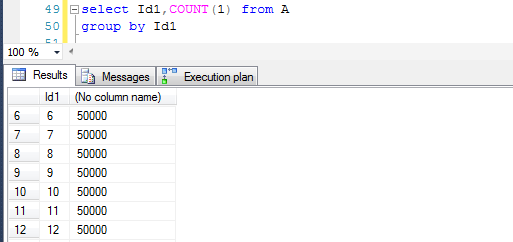
插入的测试数据的分布如下,Id1是从1~20,每一个Id1对应50000个不同的Id2
统计信息直方图中覆盖到的谓词的预估
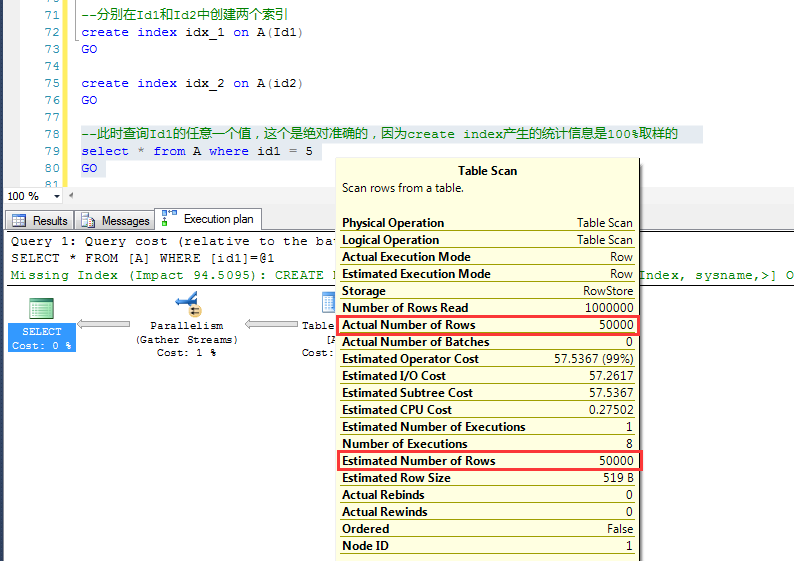
测试:根据直方图中的任何一个Id来做查询,查询之前先创建相关列上的统计信息,发现预估行数是绝对准确的。
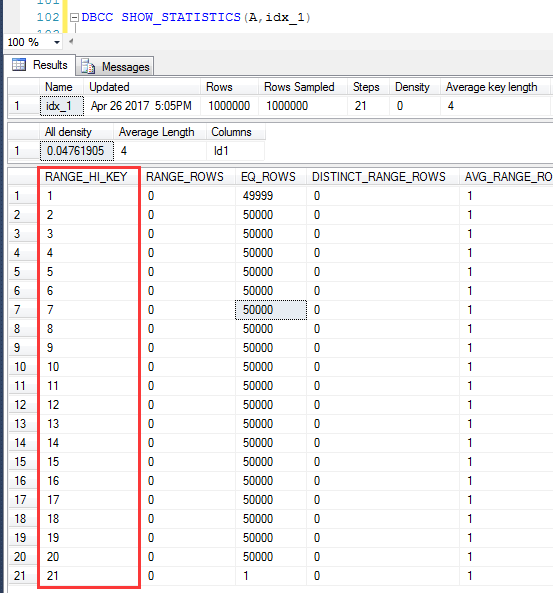
查看idx_1上的统计信息,上面预估的绝对准确就归结于统计信息100%的取样统计以及Rang_Hi_key的EQ_Rows,直方图中的Id1的分布是1~21
统计信息直方图中未覆盖到的谓词的预估
继续插入一个与上面Id2都不一样的数据,这里为50,因为此时插入的是50000行数据,同时又不足以触发统计信息更新,因此发生如下写入数据之后,统计信息并不会更新。
因此这个插入完成之后,统计信息并没有更新。
因为统计信息没有更新,在idx_1的直方图中,是没有Id1=50的信息的,也就说Id1=50不存在于统计信息的直方图中,
在SQL Server 2012中预估的结果:预估为1行,实际为50000行

重复以上测试代码,分别在SQL Server 2014和SQL Server 2016中测试,不重复截图了
SQL Server 2014中测试如下:行预估为1024.7,实际为50000,
这个值是通过什么方式计算出来的?暂时还没查到资料。
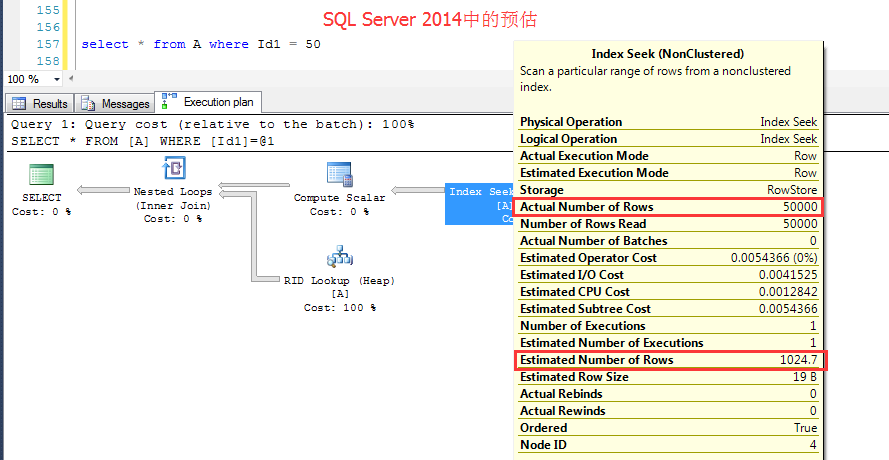
可以确定的是,对于类似情况的预估算法,也就是谓词没有包含在统计信息直方图中的情况下(one specifies a value which is out of range of the current statistics)
在sqlserver 2014中,经测试,不同情况下预估是不一样的,不是固定的预估为1行,也不是固定预估为的0.1%,也不是简单的Rows Sampled*All density
SQL Server 2016中测试如下: 预估为49880.8,实际为50000,基本上接近于真实值。
相对于SQL Server 2012和2014的预估结果,这个预估的准确性看起来还是比较吊的。
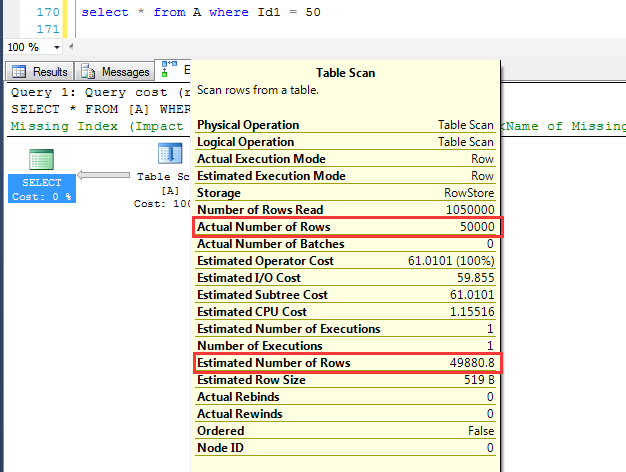
为什么SQL Server 2016中预估的如此准确?
因为在SQL Server 2016中,对于直方图中不存在的过滤谓词,在用这个谓词进行查询的时候,会自动更新相关的统计信息,然后再执行查询,
这个特性,相对于SQL Server 2012和2014来说,是全新的,也是非常实用的。
SQL Server 2014这个预估策略虽然在2012的基础上做出了一些改进,但是还是没有解决本质问题,以至于人仍旧要人为地干预统计信息的更新。
在SQL Server 2016中,即便是当前表中改变的数据行还没有达到触统计信息更新阈值的条件(传统上所谓的阈值,500+rowcount*20%),
统计信息依然会在查询的驱动下更新,通过索引上的统计信息可以看到,参考下图,直方图中生成了一个50的统计。

下面就是所谓触发统计信息更新阈值的条件(严格说是该规则仅对SQL Server 2016之前的版本有效,不适应于SQL Server 2016)
1,表格从没有数据变成有大于等于1条数据。
2,对于数据量小于500行的表格,当统计信息的第一个字段数据累计变化量大于500以后。
3,对于数据量大于500行的表格,当统计信息的第一个字段数据累计变化量大于500 + (20%×表格数据总量)以后。
这个说法,对于SQL Server 2016之前的版本是有效的,对于SQL Server 2016之后的版本是不成立的,我想这个还是值得注意的。
SQL Server 2016中统计信息更新策略相当于之前版本中开启了TraceFlag 2371,参考http://www.cnblogs.com/wy123/p/5748933.html
也即决定统计信息的变化值为动态的,不再拘泥于“数据累计变化量大于500 + (20%×表格数据总量)”这一限制。
除此之外,应该还要其他机制,比如这里的查询所触发的。
造成的问题
为什么微软会在SQL Server 2016中将统计信息的更新策略做出如此的改变,以及为什么笔者会来探究这个问题?
当然在实际业务中被这个问题坑的蛋疼。
问题很明显,类似于测试的场景,在SQL Server 2012(包括之前的版本),这种预估策略存在的严重的缺陷。
比如示例中:
因为没有当前过滤谓词的统计信息(或者说没有收集到当前谓词的统计信息),实际为5000行的情况下,预估为1行。
这种预估策略非常离谱,某种情况下会造成严重的性能问题,估计也很容易猜到,只是遇到的比较少罢了.
下面就简单具体说明,会造成什么问题,以及原因。
上述问题在什么情况下会造成性能问题,以及影响又多严重,这里仅简单举例说明。下面这个测试是在SQL Server 2012下进行的。
为演示这个问题,先来做另外一张测试表B,并写入测试数据。
create table B
(
IdentifierId int identity(1,1),
Id2 int,
OtherCol char(500)
)
GO begin tran
declare @i int = 1
while @i<=1000000
begin
insert into B values (@i,NEWID())
set @i = @i+1
if (@i%100000)=0
begin
if @@TRANCOUNT>0
begin
commit
begin tran
end
end
end
if @@TRANCOUNT>0
begin
commit
end
GO create index idx_2 on B(Id2)
GO
借助第二张表做一个测试,从而把错误预估行数造成的缺陷给放大,
执行下面两个SQL,分别查询A.Id1 = 5和A.Id1 = 50的信息,
由数据分布可知,查询总的结果总数会完全一样(截图受影响行数),
虽然A.Id1 = 5和A.Id1 = 50的数据量和分布也完全一样,但是后者的逻辑IO远远超出前者。
就是因为直方图中没有A.Id1 = 50的统计信息,A.Id1 = 50被错误地预估为1行造成的。

具体原因就很明了的,了解执行计划的同学应该很清楚。
因为错误地预估了当前谓词过滤的行数,在A表上,采用索引查找的方式来查询数据,
事实证明,当前情况下,这是比全表扫描更加低效的一种方式(看逻辑IO),这是其一。
另外A表查询之后驱动B表的过程中,因为预估为一行,采用了Nested Loop的方式来驱动B表做连接,
事实上当前情况下Nested Loop并非最好的,可以说是很不好的。
这里也可以归结为统计信息的直方图中没有过滤谓词上的统计信息,在第一个阶段的预估中错误地估算为1行造成的。
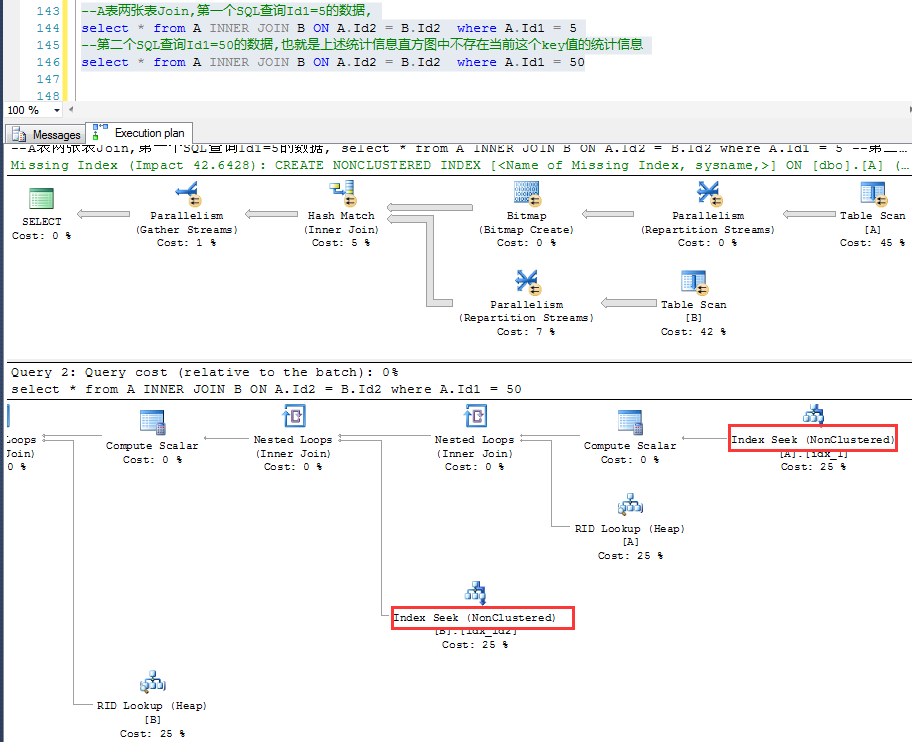
这种问题更蛋疼的地方在于,检查Session或者缓存的执行计划的时候,会发现,表面上看,执行计划挺好的啊,都用到索引了。
比如第二个SQL的执行计划,看起来似乎没问题,也容易直接忽略这个造成的问题,
从而把重点转向其他地方,使得问题变得更加难以甄别。其实问题正是出在错误地使用了索引,不该使用索引的地方使用了索引。
这就是执行计划第一步选择错误,造成后面每一步都错误的情况(一步错,步步错),实际情况中,SQL更加复杂,数据量也更大,造成的影响也更大。
如果上述示例中在再多几张表join,会出现清一色的Nested Loop方式来驱动表连接,这样的话,SQL执行时间和逻辑IO是非常高的。
附上一个在SQL Server 2016下的测试截图,可见在默认情况下,执行计划做出了正确的选择。


最后:
1,本文不是说索引的,关于索引的就不多说。
2,本文也的场景虽然不是太常见,稍显特殊,但也是实际遇到的,另外可以看出,微软也在从这个方面逐步改进SQL Server优化器更新统计信息的策略。
3,关于此场景下的预估,在不同版本下,还有不少有意思问题没有抛出来,有机会再说。
4,类似问题只有在数据量相对较大的情况下才能发生,如果是十万以下或者几十万的数据量,对数据库来说算是微小型数据量,类似问题对性能的影响完全体现不出来。
5,如果有人根据本文的测试验证的话,请注意一个细节:对于过滤谓词的预估,分如下两种情况,这两种情况在2012和2014(2016)中预估的方式也是不同的
1,表中确实没有这个谓词的数据,并且统计信息没有更新,比如Id1 = 50的数据为0行的情况下的预估
2,表中有这个谓词的数据,同样是统计信息没有更新,比如Id1 = 50的数据为50000行的情况下的预估
总结:
SQL Server 的预估对执行计划的生成有着至关重要的影响,而预估又依赖于统计信息,因此统计信息的更新以及准确性就显得尤为重要。鉴于此,SQL Server在每个版本中,对于统计信息的生成以及更新策略都有着比较大的变化,本文仅仅从一个较小的点出发,来验证SQL Server各个版本中统计信息预估以及更新的一些特点,从中发现类似问题可能产生的潜在的影响,以及SQL Server 2016中的一些改进。
SQL Server 中统计信息直方图中对于没有覆盖到谓词预估以及预估策略的变化(SQL2012-->SQL2014-->SQL2016)的更多相关文章
- MySQL 8.0 中统计信息直方图的尝试
直方图是表上某个字段在按照一定百分比和规律采样后的数据分布的一种描述,最重要的作用之一就是根据查询条件,预估符合条件的数据量,为sql执行计划的生成提供重要的依据在MySQL 8.0之前的版本中,My ...
- SQL SERVER的统计信息
1 什么是统计信息 统计信息 描述了 表格或者索引视图中的某些列的值 的分布情况,属于数据库对象.根据统计信息,查询优化器就能评估查询过程中需要读取的行数及结果集情况,同时也能创建高质量的查询 ...
- Sql Server优化---统计信息维护策略
本位出处:http://www.cnblogs.com/wy123/p/5748933.html 首先解释一个概念,统计信息是什么: 简单说就是对某些字段数据分布的一种描述,让SQL Server大概 ...
- SQL Server 查找统计信息的采样时间与采样比例
有时候我们会遇到,由于统计信息不准确导致优化器生成了一个错误的执行计划(或者这样表达:一个较差的执行计划),从而引起了系统性能问题.那么如果我们怀疑这个错误的执行计划是由于统计信息不准确引起的.那么我 ...
- SQL Server 等待统计信息基线收集
背景 我们随时监控每个服务器不同时间段的wait statistics ,可以根据监控信息大概判断什么时候开始出现异常,相当于一个wait statistics基线收集,还可以具体分析占比高的等待类型 ...
- SQL Server 更新统计信息出现严重错误,应放弃任何可能产生的结果
一台SQL Server 2008 R2版本(具体版本如下所示)的数据库,最近几天更新统计信息的作业出错,错误如下所示: Microsoft SQL Server 2008 R2 (SP2) - ...
- 解决 U2000 R017 安装报错: 检查SQL server数据库环境变量信息 ( 异常 ) [ 详细信息 ] PATH环境变量中缺少数据库路径的信息
U2000 R017 安装报错: 检查SQL server数据库环境变量信息 ( 异常 ) [ 详细信息 ] PATH环境变量中缺少数据库路径的信息 管理员模式打开注册表位置: HKEY_LOCAL_ ...
- 10-SQLServer中统计信息的使用
一.总结 1.网址https://docs.microsoft.com/en-us/sql/relational-databases/system-catalog-views/sys-stats-tr ...
- ArcSDE for SQL Server安装及在ArcMap中创建ArcSDE连接
原文:ArcSDE for SQL Server安装及在ArcMap中创建ArcSDE连接 安装ArcSDE for SQL Server,最后一步成功后的界面如下: 在ArcMap中创建ArcSDE ...
随机推荐
- 3390: [Usaco2004 Dec]Bad Cowtractors牛的报复
3390: [Usaco2004 Dec]Bad Cowtractors牛的报复 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 69 Solved: ...
- 不懂这些分布式架构、分布式系统的数据一致性解决方案,你如何能找到高新互联网工作呢?强势解析eBay BASE模式、去哪儿及蘑菇街分布式架构
互联网行业是大势所趋,从招聘工资水平即可看出,那么如何提升自我技能,满足互联网行业技能要求?需要以目标为导向,进行技能提升,本文主要针对招聘中高频提及的分布式系统设计.架构(数据一致性)做了分析,祝各 ...
- 详解< meta http-equiv = "X-UA-Compatible" content = "IE=edge,chrome=1" />
< meta http-equiv = "X-UA-Compatible" content = "IE=edge,chrome=1" /> 这是个是 ...
- 10分钟精通SharePoint - SharePoint发展历程
SharePoint 2001: SharePoint Team Service(STS) SharePoint Portal Server(SPS) SharePoint 2003: Windows ...
- 标准之路网站上一篇文章《十天学会web标准(div+css)》的营养精华
以下精华出自如下链接,“http://www.aa25.cn/special/10day/index.shtml”,<十天学会web标准(DIV+CSS)>. 这个内容不要删掉:“< ...
- spring-AOP-ProxyFactoryBean代理的实例
1.一个代理模式的实例 通过 Proxy类进行代理 wait.java //定义一个接口 public interface wait { void say(); } //目标对象实现接口并重写方法 p ...
- iOS开发之计算文字尺寸
/** * 计算文字尺寸 * * @param text 需要计算尺寸的文字 * @param font 文字的字体 * @param maxSize 文字的最大尺寸 */ - ( ...
- [微信小程序]初试——成绩分析小程序问题总结
文件类型说明 第一次打开微信小程序的开发者工具,就是下面这个样子. 好多已经存在的默认文件 .js .json .wxml .wxss 首先当然要搞懂这些文件都是干什么的 app.js是小程序的脚本代 ...
- java里的日期时间
为了更好理解java的日期时间类,在这里我们先介绍一下关于历法.标准时间的一些概念. 历法有很多种,我们大中华上下五千年,自然也有自己的历法,生活中我们通常把自己传统的历法叫做农历,也有人叫它阴历或夏 ...
- 浩哥解析MyBatis源码(四)——DataSource数据源模块
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6634880.html 1.回顾 上一文中解读了MyBatis中的事务模块,其实事务操作无非 ...