K相邻算法
刚开始学习机器学习,先跟这《机器学习实战》学一些基本的算法
----------------------------------分割线--------------------------------------------
该算法是用来判定一个点的分类,首先先找到离该点最近的k个点,然后找出这k个点的哪种分类出现次数最多,就把该点设为那个分类
距离公式选用欧式距离公式:
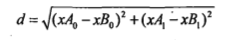
下面给出例子(来自《机器学习实战》)
1.约会对象喜欢程度的判定:
现需要一个约会对象喜欢程度的分类器
给定数据集,属性包含
每年获得的飞行常客里程数,玩视频游戏所耗时间百分比,每周消费的冰淇淋公升数,是否喜欢且喜欢程度(不喜欢,一般喜欢,特别喜欢),四个属性
分类器代码:
先获取整个数据集的约会对象个数t,然后把我们要分类的矩阵复制t次
然后减去原数据集,得到xA0-xB0和xA1-xB1,然后对矩阵每个元素平方,行内求和,开根号,得到所有点的距离
统计前k个数据类别出现次数,返回次数最多的类别
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
先从文件中分别读前三个属性和喜欢程度到矩阵
然后进行归一化,最后分类得到结果统计一下就好了
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio = 0.50 #hold out 10%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
2.数字识别
给定训练集包含32*32的01字符串,然后判定测试集的数字
对于把32*32每个数字都看作一个属性,然后直接算距离分类...
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('digits/trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr)
testFileList = listdir('digits/testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
K相邻算法的更多相关文章
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- 分类算法----k近邻算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- 用Python从零开始实现K近邻算法
KNN算法的定义: KNN通过测量不同样本的特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别.K通 ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
随机推荐
- Netty自娱自乐之协议栈设计
---恢复内容开始--- 俺工作已经一年又6个月了,想想过的真快,每天写业务,写业务,写业务.......然后就是祈祷着,这次上线不要出现线上bug.继续这每天无聊的增删改查,学习学习一下自己感兴趣的 ...
- Java基础学习 —— io
/** 解决数据与数据之间的传输问题. 字节流: 输入字节流: -------| InputStream 所有输入字节流的基类.抽象类. -----------| FileInputStream 读取 ...
- Java中死锁的简单例子及其避免
死锁:当一个线程永远地持有一个锁,并且其他线程都尝试获得这个锁时,那么它们将永远被阻塞.比如,线程1已经持有了A锁并想要获得B锁的同时,线程2持有B锁并尝试获取A锁,那么这两个线程将永远地等待下去. ...
- NHibernate教程(21)——二级缓存(下)
本节内容 引入 使用NHibernate二级缓存 启用缓存查询 管理NHibernate二级缓存 结语 引入 这篇我还继续上一篇的话题聊聊NHibernate二级缓存剩下的内容,比如你修改.删除数据时 ...
- JOptionPane弹框常用实例
最近在做swing程序中遇到使用消息提示框的,JOptionPane类其中封装了很多的方法. 很方便的,于是就简单的整理了一下. 1.1 showMessageDialog 显示一个带有OK 按钮的模 ...
- MPLS LDP随堂笔记1
LDP 的使用原因(对于不同协议来说) LDP的四大功能 发现邻居 hello 5s 15s 224.0.0.2 发现邻居关系 R1 UDP 646端口 R2 UDP 646端口 此时形成邻居 建立邻 ...
- 201521123084 《Java程序设计》第2周学习总结
第2周作业-Java基本语法与类库 1. 本周学习总结 1.学会使用码云管理代码: 2.学会使用Eclipse关联jdk源代码,并查看对象的源代码: 3.学会String类和StringBuilder ...
- 201521123009 《Java程序设计》第8周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 2. 书面作业 本次作业题集集合 Q1:List中指定元素的删除(题目4-1) 1.1 实验总结 Scanne ...
- 201521123080《Java程序设计》第6周学习总结
1. 本周学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 注1:关键词与内容不求多,但概念之间的联系要清晰,内容覆盖 ...
- 201521123104 《Java程序设计》第5周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关多态与接口的知识点 1.2 可选:使用常规方法总结其他上课内容. 1.接口不是类,不能使用new进行实例化; 2.接口可以扩展; 3.接口中可以包含 ...