基于node.js制作爬虫教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友。
目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息。
思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地。
步骤一:安装node.js
下载并安装node,此步骤比较简单就不详细解释了,有问题的可以直接问一下度娘。
步骤二:建立工程
1)打开dos命令条,cd进入想要创建项目的路径(我将此项目直接放在了E盘,以下皆以此路径为例);
2)mkdir node (创建一个文件夹用来存放项目,我这里取名为node);
3)cd 进入名为node的文件夹,并执行npm init初始化工程(期间会让填写一些信息,我是直接回车的);
步骤三:创建爬取到的数据存放的文件夹
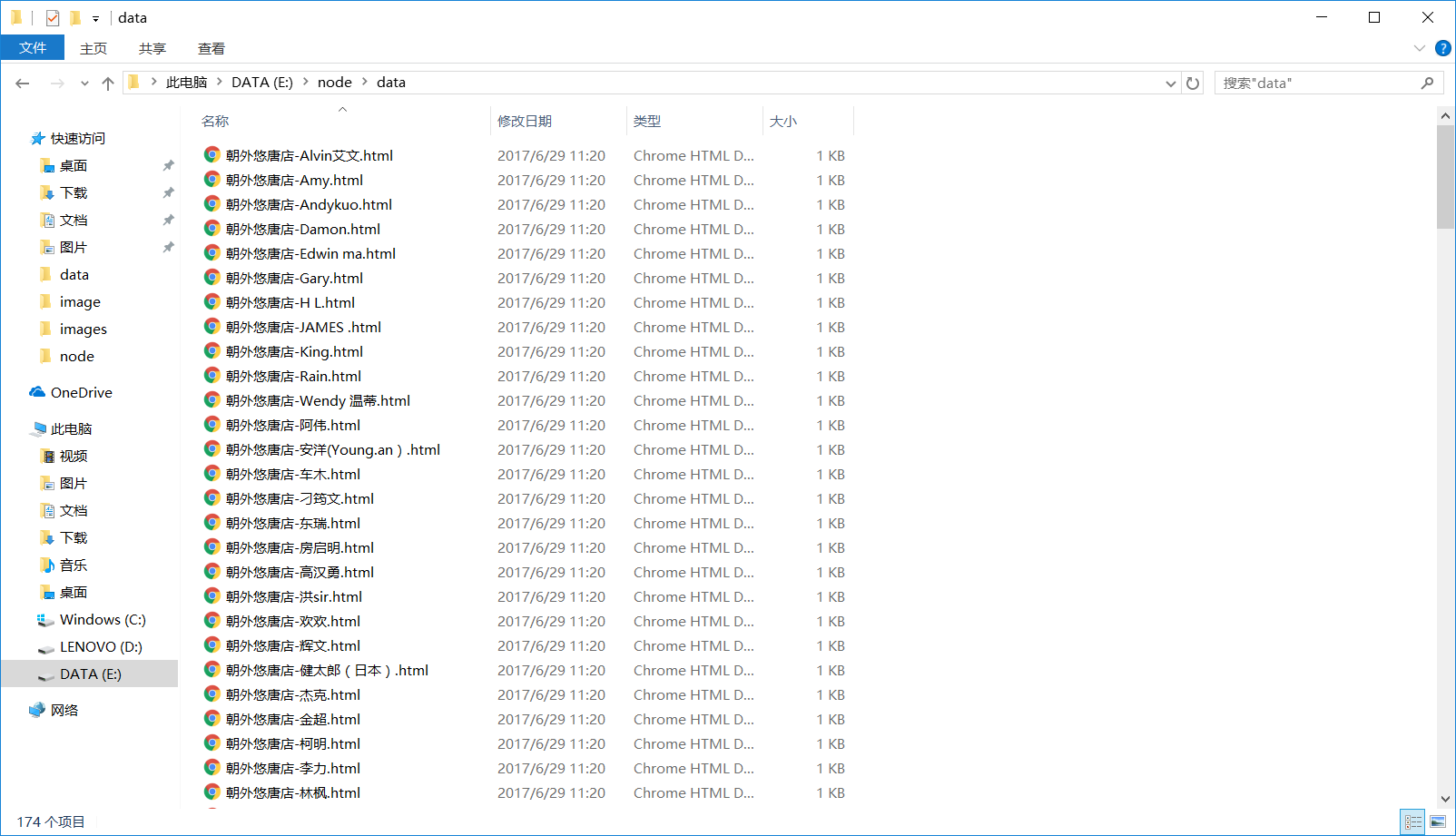
1)创建data文件夹用来存放发型师基本信息;
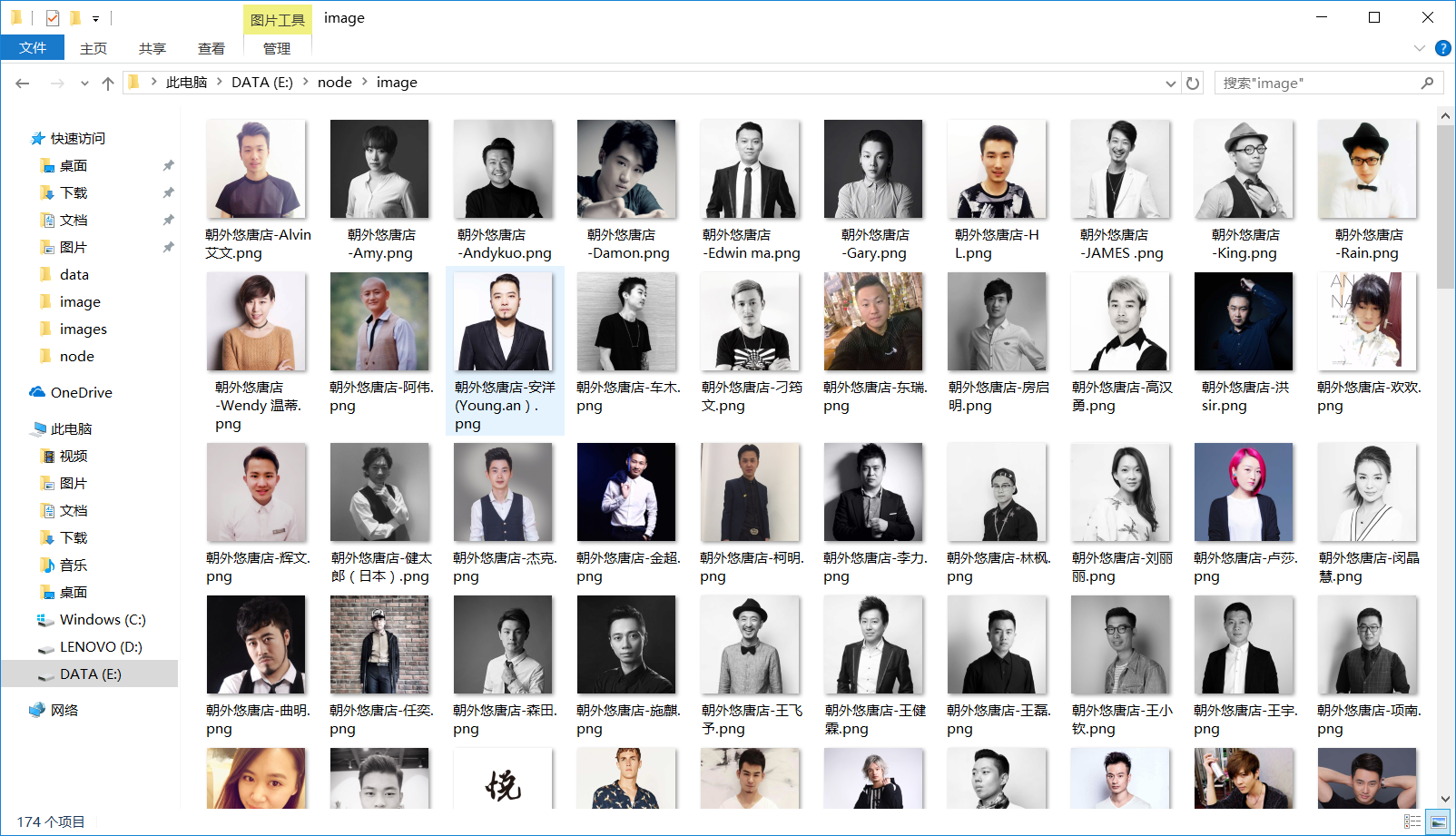
2)创建image文件夹用来存储发型师头像图片;
此时工程下文件如下:

步骤四:安装第三方依赖包(fs是内置模块,不需要单独安装)
1)npm install cheerio –save
2)npm install superagent –save
3)npm install async –save
4)npm install request –save
分别简单解释一下上面安装的依赖包:
cheerio:是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现,则能够对请求结果进行解析,解析方式和jQuery的解析方式几乎完全相同;
superagent:能够实现主动发起get/post/delete等请求;
async:async模块是为了解决嵌套金字塔,和异步流程控制而生,由于nodejs是异步编程模型,有一些在同步编程中很容易做到的事情,现在却变得很麻烦。Async的流程控制就是为了简化这些操作;
request:有了这个模块,http请求变的超简单,Request使用简单,同时支持https和重定向;
步骤五:编写爬虫程序代码
打开hz.js,编写代码:
var superagent = require('superagent');
var cheerio = require('cheerio');
var async = require('async');
var fs = require('fs');
var request = require('request');
var page=1; //获取发型师处有分页功能,所以用该变量控制分页
var num = 0;//爬取到的信息总条数
var storeid = 1;//门店ID
console.log('爬虫程序开始运行......');
function fetchPage(x) { //封装函数
startRequest(x);
}
function startRequest(x) {
superagent
.post('http://tweixin.yueyishujia.com/v2/store/designer.json')
.send({
// 请求的表单信息Form data
page : x,
storeid : storeid
})
// Http请求的Header信息
.set('Accept', 'application/json, text/javascript, */*; q=0.01')
.set('Content-Type','application/x-www-form-urlencoded; charset=UTF-8')
.end(function(err, res){
// 请求返回后的处理
// 将response中返回的结果转换成JSON对象
if(err){
console.log(err);
}else{
var designJson = JSON.parse(res.text);
var deslist = designJson.data.designerlist;
if(deslist.length > 0){
num += deslist.length;
// 并发遍历deslist对象
async.mapLimit(deslist, 5,
function (hair, callback) {
// 对每个对象的处理逻辑
console.log('...正在抓取数据ID:'+hair.id+'----发型师:'+hair.name);
saveImg(hair,callback);
},
function (err, result) {
console.log('...累计抓取的信息数→→' + num);
}
);
page++;
fetchPage(page);
}else{
if(page == 1){
console.log('...爬虫程序运行结束~~~~~~~');
console.log('...本次共爬取数据'+num+'条...');
return;
}
storeid += 1;
page = 1;
fetchPage(page);
}
}
});
}
fetchPage(page);
function saveImg(hair,callback){
// 存储图片
var img_filename = hair.store.name+'-'+hair.name + '.png';
var img_src = 'http://photo.yueyishujia.com:8112' + hair.avatar; //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}else{
request(img_src).pipe(fs.createWriteStream('./image/' + img_filename)); //通过流的方式,把图片写到本地/image目录下,并用发型师的姓名和所属门店作为图片的名称。
console.log('...存储id='+hair.id+'相关图片成功!');
}
});
// 存储照片相关信息
var html = '姓名:'+hair.name+'<br>职业:'+hair.jobtype+'<br>职业等级:'+hair.jobtitle+'<br>简介:'+hair.simpleinfo+'<br>个性签名:'+hair.info+'<br>剪发价格:'+hair.cutmoney+'元<br>店名:'+hair.store.name+'<br>地址:'+hair.store.location+'<br>联系方式:'+hair.telephone+'<br>头像:<img src='+img_src+' style="width:200px;height:200px;">';
fs.appendFile('./data/' +hair.store.name+'-'+ hair.name + '.html', html, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
callback(null, hair);
}
步骤六:运行爬虫程序
输入node hz.js命令运行爬虫程序,效果图如下:
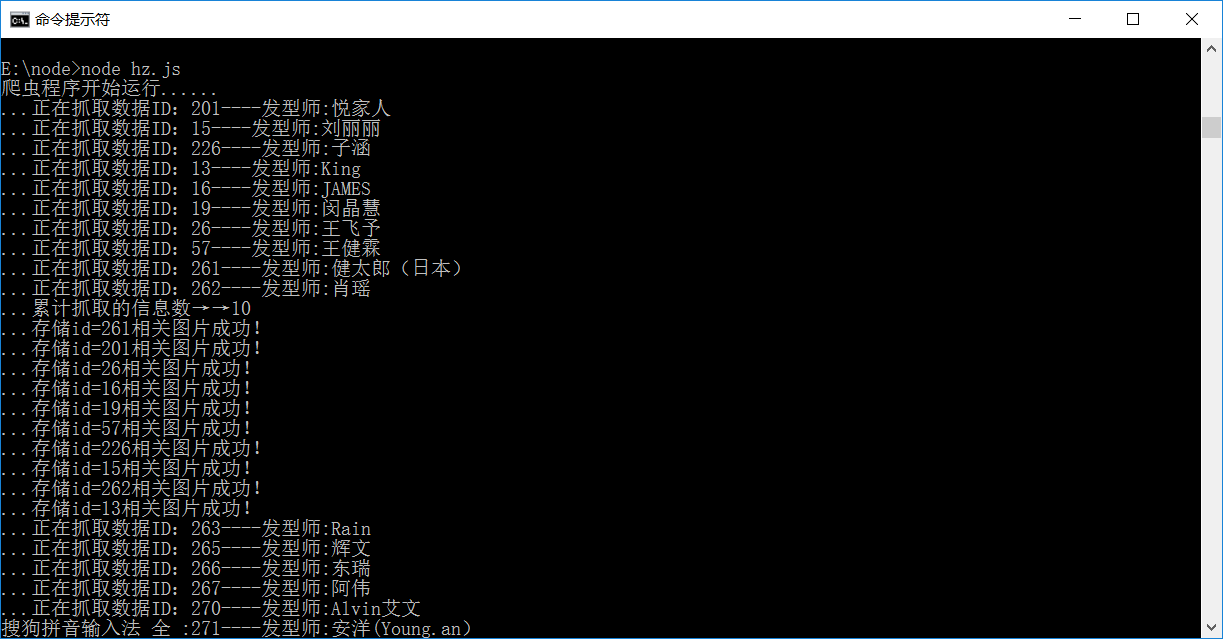
运行成功后,发型师基本信息以html文件的形式存储在data文件夹中,发型师头像图片存储在image文件夹下:
后记:到此一款基于node.js制作的简单爬虫就大功告成了,由于我也是初学者,好多地方也不是很理解,但好在是自己完成了,不足之处敬请谅解。
代码下载地址:https://github.com/yanglei0323/nodeCrawler
基于node.js制作爬虫教程的更多相关文章
- 基于Node.js的爬虫工具 – Node Crawler
Node Crawler的目标是成为最好的node.js爬虫工具,目前已经停止维护. 我们来抓取光合新知博客tech栏目中的文章信息.访问http://dev.guanghe.tv/category/ ...
- 基于node.js的爬虫框架 node-crawler简单尝试
百度爬虫这个词语,一般出现的都是python相关的资料. py也有很多爬虫框架,比如scrapy,Portia,Crawley等. 之前我个人更喜欢用C#做爬虫. 随着对nodejs的熟悉.发现做这种 ...
- 基于Node.js的强大爬虫 能直接发布抓取的文章哦
基于Node.js的强大爬虫 能直接发布抓取的文章哦 基于Node.js的强大爬虫能直接发布抓取的文章哦!本爬虫源码基于WTFPL协议,感兴趣的小伙伴们可以参考一下 一.环境配置 1)搞一台服务器,什 ...
- #1使用html+css+js制作网站教程 准备
#1使用html+css+js制作网站教程 准备 本系列链接 0 准备 0.1 IDE编辑软件 0.2 浏览器 0.3 基础概念 0.3.1 html 0.3.2 css 0.3.3 js 0.4 文 ...
- NodeBB – 基于 Node.js 的开源论坛系统
NodeBB 是一个更好的论坛平台,专门为现代网络打造.它是免费的,易于使用. NodeBB 论坛软件是基于 Node.js 开发,支持 Redis 或 MongoDB 的数据库.它利用 Web So ...
- 基于 Node.js 平台,快速、开放、极简的 web 开发框架。
资料地址:http://www.expressjs.com.cn/ Express 基于 Node.js 平台,快速.开放.极简的 web 开发框架. $ npm install express -- ...
- Pomelo:网易开源基于 Node.js 的游戏服务端框架
Pomelo:网易开源基于 Node.js 的游戏服务端框架 https://github.com/NetEase/pomelo/wiki/Home-in-Chinese
- Fenix – 基于 Node.js 的桌面静态 Web 服务器
Fenix 是一个提供给开发人员使用的简单的桌面静态 Web 服务器,基于 Node.js 开发.您可以同时在上面运行任意数量的项目,特别适合前端开发人员使用. 您可以通过免费的 Node.js 控制 ...
- 基于Node.js + jade + Mongoose 模仿gokk.tv
原文摘自我的前端博客,欢迎大家来访问 http://www.hacke2.cn 关于gokk 大学的娱乐活动基本就是在寝室看电影了→_→,一般都会选择去goxiazai.cc上看,里面的资源多,质量高 ...
随机推荐
- Cygwin Unable to get setup from *
Cygwin Unable to get setup from * 错误 解决方案 是因为用自定义镜像站点,比如 http://mirrors.xdlinux.info/cygwin/x86_64/ ...
- select多用户之间通信
查看记录:10/20 今天又重新看了一下程序,觉得ListenKeyboard这个函数写的很好.利用select监听键盘,成功的解决了 必须输入才会刷新消息的问题.这样等待15秒后也可刷新消息,效 ...
- Bitwise And Queries
Bitwise And Queries Time limit: 1500 msMemory limit: 128 MB You are given QQ queries of the form a\ ...
- 深度解析PHP数组函数array_merge
很久之前就用到过这个函数,只不不过是简单的用用而已并没有做太深入的研究 今天在翻阅别人博客时看到了对array_merge的一些使用心得,故此自己来进行一次总结. array_merge是将一个或者多 ...
- 1.Java第一课:初识java
今天也算是正式地开始学习Java了,一天学的不是太多,旨在入门了解Java.还好现在学的都是基础,也能赶得上进度,希望以后能一直保持这种精神状态坚持学下去.下面就简单来说说今天所学的内容吧. 1计算机 ...
- 在node.js中如何屏蔽掉favicon.ico的请求
今天准备用node做个api出来,还没入门,遇到一个小问题,特在此记录一下! 在做路由模块的时候,发现控制台每次都会多输出一条favicon.ico的请求,对于这种又占资源,看着又碍眼的玩意,强迫症完 ...
- 可视化之Berkeley Earth
去年冬天雾霾严重的那几天,写了两篇关于空气质量的文章,<可视化之PM2.5>和<谈谈我对雾霾的认识>.坦白说,环境问题是一个无法逃避又无能为力的话题.最近因为工作中有一些数据可 ...
- DRBD+Heartbeat+Mysql高可用读写分离架构
声明:本案例仅为评估测试版本 注意:所有服务器之间必须做好时间同步 架构拓扑 IP信息: Heartbeat安装部署 1.安装heartbeat(主备节点同时安装) [root@master1 ~]# ...
- Mysql数据库二进制安装
MySQL数据库有四种安装方法: 源码包编译安装 RPM包安装 二进制文件安装 官方yum源安装 这里我们主要介绍二进制包的安装方法 在MySQL官网下载二进制包并且上传到服务器上 解压二进制包 [r ...
- [HDU1002] A + B Problem II
Problem Description I have a very simple problem for you. Given two integers A and B, your job is to ...