FME中通过HTMLExtractor向HTML要数据
如何不断扩充数据中心的数据规模,提升数据挖掘的价值,这是我们思考的问题,数据一方面来自于内部生产,一部分数据可以来自于互联网,互联网上的数据体量庞大,形态多样,之前blog里很多FMEer已经提出了方案,比如json,xml,正则表达式等等,但对于比较松散的HTML如何进行数据解析提取呢?我问了一下度娘,貌似没有FME下的文章,恰逢今天有时间,就写一点关于HTML提取的东东,算是自己做的笔记吧!
这次我要提取的范例数据来自国土资源局土地招拍挂系统,我要提取上面的交易结果以及地块信息,样式如下图:

图1:交易结果列表

图2:地块信息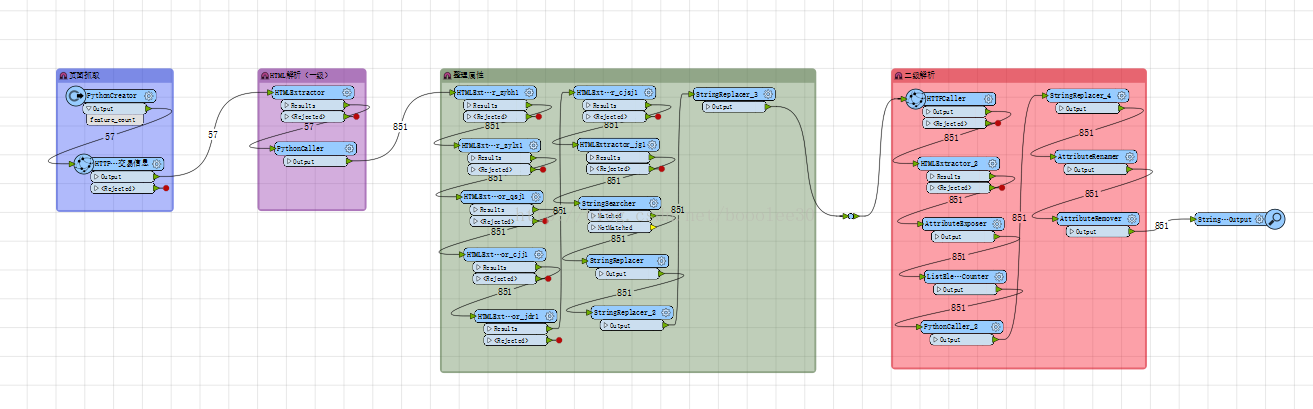
图3:转换工程
图4:提取后的数据
在这个转换工程里,用到了几个转换器,它们是:pythonCreator,HTTPCaller,HTMLExtractor、PythonCaller、StringSearcher、StringReplacer、AttributeExposer、AttributeRenamer、AttributeRemover
本文重点介绍一下HTMLExtractor,转换器的参数如下图:
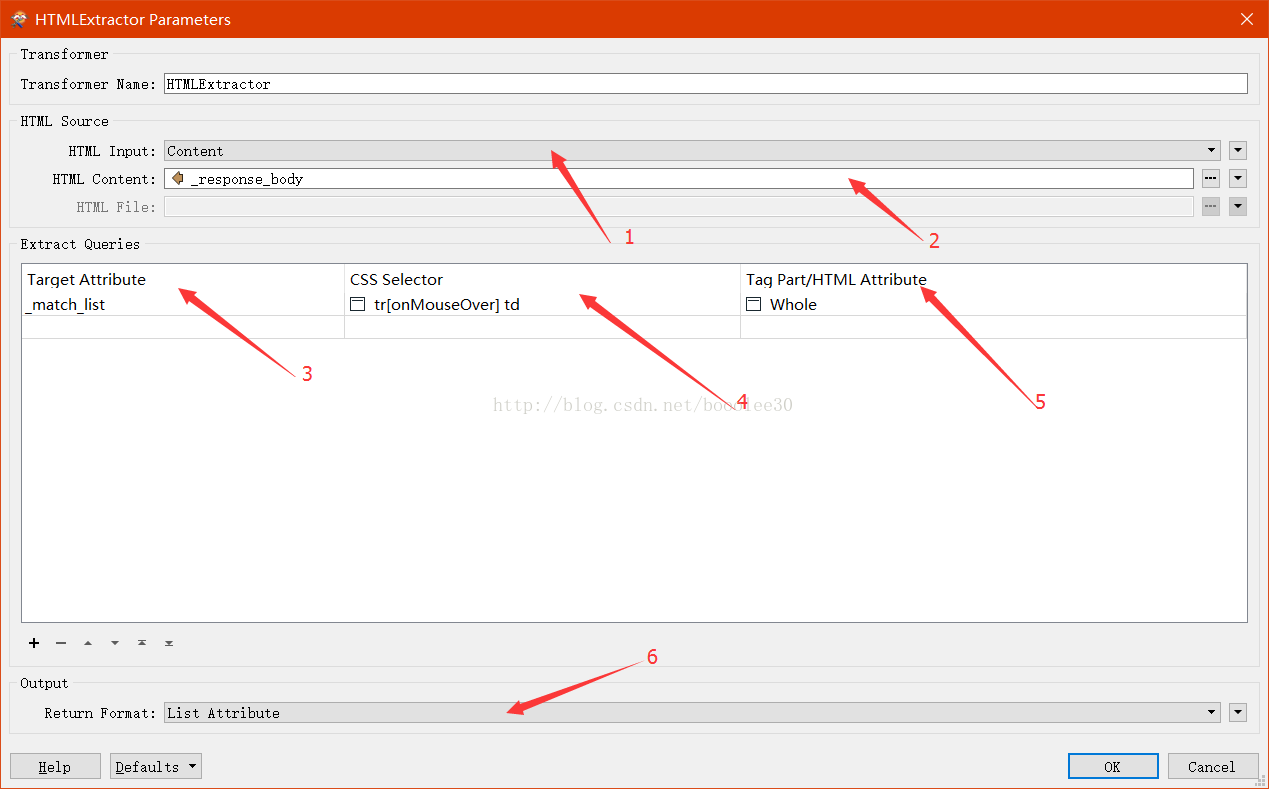
图5:HTMLExtractor参数
图上标注的参数依次是:
1、 HTML Input:HTML的内容来源,可以是content,表示来源于传入的属性、参数等,也可以是File,表示来源于一个已存在的HTML文件。
2、 HTML Content:本案例用的是content作为源,与HttpCaller连用,HTML存放于_response_body属性中。如果是File作为源,则需要设置HTML File为文件路径。
3、 Target Attribute:设置一个属性(列表)名称,这个属性名称将包含HTML解析的结果。
4、 CSS Selector:设置CSS选择器,类似正则表达式,但用起来更简单,特别适合解析HTML。
5、 Tag Part/HTML Attribute:可以设置为Value(匹配标签里的值)、Whole(匹配的标签和值)、或者输入匹配标签拥有的一个属性名称,比如<a>标记的href属性。
6、 Return Format:可以设置为List Attribute,则将所有匹配的内容作为一个list返回,如果为First Match,则仅返回第一个匹配的内容。
举个栗子,下面是我要匹配的交易结果HTML源文件:
<tr class="TR2" onMouseOver="this.className='TR3';" onMouseOut="this.className='TR2';">
<td height="31" align="left" class="TD1"><img src="data:images/arrow_yellow.gif">2</td>
<td class="TD1" align="left">BQ2-19-87</td>
<td class="TD1" align="left">国有建设用地使用权</td>
<td class="TD1" align="left">15851.0万元</td>
<td class="TD1" align="left">15851.0万元</td>
<td class="TD1" align="left">西安奥达房地产开发有限责任公司</td>
<td class="TD1" align="left">2017-04-27 16:00</td>
<td class="TD1" align="center" style="color:#FF0000;cursor:pointer;" onClick="window.open('publics/ResourceFrame.jsp?id=933&lx=L','','left=10,top=10,width=890,height=650,scrollbars=yes,resizable=yes,status=yes')">已成交</td>
</tr>
我要把红色的内容提取出来,我只需要简单的写一句CSS选择器进行匹配即可,但在写之前一般是要先整理分析一下HTML源文件,找出可以用于匹配的特征,提高匹配的准确度,减少其他杂质数据被提取出来。
因为HTML源文件中有大量的<td>,所以直接匹配td是不行的,经过分析我找到了特征,CSS选择器为:tr[onMouseOver] td。意思是拥有onMouseOver属性的tr标记下的td标记。
就这么简单,获取的数据还有少量杂质,再用其他的转换器清洗一下即可。
另外,最近正则表达式呼声很高,必须承认,正则表达式非常强大,但有些工作还是有更简单的办法,杀鸡焉用牛刀,对于HTML,通过编写CSS选择器应用HTMLExtractor转换器来解析数据,更加敏捷高效!
FME中通过HTMLExtractor向HTML要数据的更多相关文章
- WebGIS中基于控制点库进行SHP数据坐标转换的一种查询优化策略
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.前言 目前项目中基于控制点库进行SHP数据的坐标转换,流程大致为:遍 ...
- OpenCV中IplImage图像格式与BYTE图像数据的转换
最近在将Karlsruhe Institute of Technology的Andreas Geiger发表在ACCV2010上的Efficent Large-Scale Stereo Matchin ...
- Linq中使用反射实现--LINQ通用数据表绑定DataGrid控件的方法(原创)
项目需求,因为项目中存在很多表,这些表的内容需要呈现给客户浏览.转载请注明出处 相信很多写过程序的设计者很容易的用以下方式实现 在SqlConnect ,DataSet 的方式,我们很轻松的可以通过S ...
- PHP 使用 mcrypt 扩展中的 mcrypt_encrypt() 和 mcrypt_decrypt() 对数据进行加密和解密
<?php /* 使用 mcrypt 扩展中的 mcrypt_encrypt() 和 mcrypt_decrypt() 对数据进行加密和解密 */ // 加密 $algorithm = MCRY ...
- AngularJS中使用service,并同步数据
service是单例对象,在应用中不同代码块之间共享数据. 对一些公用的方法封装到service中,然后通过依赖注入在Controller中调用,示例代码: 1.创建一个模块: var module ...
- Nodejs中cluster模块的多进程共享数据问题
Nodejs中cluster模块的多进程共享数据问题 前述 nodejs在v0.6.x之后增加了一个模块cluster用于实现多进程,利用child_process模块来创建和管理进程,增加程序在多核 ...
- winform中dataGridView高度自适应填充完数据的高度
// winform中dataGridView高度自适应填充完数据的高度,就是dataGridView自身不产生滚动条,自己的高度是根据数据的多少而变动. 在load的时候,数据绑定后,加上如下代码: ...
- unserialize函数中的参数是否是污染数据
1.原理 在程序编写的时候,往往需要序列化一些运行时数据,所谓序列化就是按照一定的格式将运行时数据写入本地文件.这样做可以对数据进行本地保存,用的时候直接读文件就可以把运行时产生的数据读出.php中就 ...
- c#中DropDownList控件绑定枚举数据
c# asp.net 中DropDownList控件绑定枚举数据 1.枚举(enum)代码: private enum heros { 德玛 = , 皇子 = , 大头 = , 剑圣 = , } 如果 ...
随机推荐
- 第一章Python起步
1.1搭建编程环境 编程环境的正确搭建很重要,一定要参考先搭配好环境变量,不然用着会很麻烦,在这里推荐使用工具pycharm,亿图图示画流程图,一定要正确安装,搭配好环境变量,后面要添加很多模块,前期 ...
- 2017-3-25 css样式表(一)
样式表: 一.样式表的概念:CSS(Cascading Style Sheets)层叠式样式表,作用是美化HTML网页. 二.样式表的分类:样式表分内联式样式表.内嵌式样式表和外部样式表三种. 1.内 ...
- MySql Table错误:is marked as crashed and last (automatic?) 和 Error: Table "mysql"."innodb_table_stats" not found
一.mysql 执行select 的时候报Table错误:is marked as crashed and last (automatic?) 解决方法如下: 找到mysql的安装目录的bin/myi ...
- JvisualVM、JMC监控远程服务器
修改服务器上jmxremote.access与jmxremote.password,输入命令: find -name jmxremote.access进入该jmxremote.access文件所在目录 ...
- linux ssh -l 命令运用
ssh是远程登录命令,-l选项是最常用的选项,下面是我的一些总结 远程登录:ssh -l userName ip # 远程登录到 10.175.23.9 ssh -l root2 10.175. ...
- PAT乙级练习1001
1001. 害死人不偿命的(3n+1)猜想 (15) 卡拉兹(Callatz)猜想: 对任何一个自然数n,如果它是偶数,那么把它砍掉一半:如果它是奇数,那么把(3n+1)砍掉一半.这样一直反复砍下去, ...
- 老李分享: Oracle Performance Tuning Overview 翻译下
1.2性能调优特性和工具 Effective data collection and analysis isessential for identifying and correcting perfo ...
- AVL树的旋转操作详解
[0]README 0.0) 本文部分idea 转自:http://blog.csdn.net/collonn/article/details/20128205 0.1) 本文仅针对性地分析AVL树的 ...
- MySQL学习笔记(一)—数据库基础
一.数据库概述 1.数据库的组织结构 (1)数据库就是用来存放信息的仓库. (2)数据库里的数据集合都存放在数据表(table)里. (3)数据表由数据行(row)和数据 ...
- WPF集合控件实现分隔符(ItemsControl Splitter)
在WPF的集合控件中常常需要在每一个集合项之间插入一个分隔符样式,但是WPF的ItemsControl没有相关功能的直接实现,所以只能考虑曲线救国,经过研究,大概想到了以下两种实现方式. 先写出Ite ...