python3-disc和set
dict
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
举个例子,假设要根据同学的名字查找对应的成绩,如果用list实现,需要两个list:
names = ['Michael', 'Bob', 'Tracy']
scores = [95, 75, 85]
给定一个名字,要查找对应的成绩,就先要在names中找到对应的位置,再从scores取出对应的成绩,list越长,耗时越长。
如果用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。用Python写一个dict如下:
>>> d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
>>> d['Michael']
95
为什么dict查找速度这么快?因为dict的实现原理和查字典是一样的。假设字典包含了1万个汉字,我们要查某一个字,一个办法是把字典从第一页往后翻,直到找到我们想要的字为止,这种方法就是在list中查找元素的方法,list越大,查找越慢。
第二种方法是先在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢。
dict就是第二种实现方式,给定一个名字,比如'Michael',dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快。
你可以猜到,这种key-value存储方式,在放进去的时候,必须根据key算出value的存放位置,这样,取的时候才能根据key直接拿到value。
把数据放入dict的方法,除了初始化时指定外,还可以通过key放入:
>>> d['Adam'] = 67
>>> d['Adam']
67
由于一个key只能对应一个value,所以,多次对一个key放入value,后面的值会把前面的值冲掉:
>>> d['Jack'] = 90
>>> d['Jack']
90
>>> d['Jack'] = 88
>>> d['Jack']
88
如果key不存在,dict就会报错:
>>> d['Thomas']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Thomas'
要避免key不存在的错误,有两种办法,一是通过in判断key是否存在:
>>> 'Thomas' in d
False
二是通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1
注意:返回None的时候Python的交互环境不显示结果。
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key:
>>> key = [1, 2, 3]
>>> d[key] = 'a list'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3}
注意,传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。。
重复元素在set中自动被过滤:
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
通过remove(key)方法可以删除元素:
>>> s.remove(4)
>>> s
{1, 2, 3}
set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
{2, 3}
>>> s1 | s2
{1, 2, 3, 4}
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
注:
set=([1,2,3]), 其中([ ])只是set的表现形式,并不是把list放入set中。
若是写成 set=([ [1,2],[3,4],[5,6] ]),才算是把list放入set中。
再议不可变对象
上面我们讲了,str是不变对象,而list是可变对象。
对于可变对象,比如list,对list进行操作,list内部的内容是会变化的,比如:
>>> a = ['c', 'b', 'a']
>>> a.sort()
>>> a
['a', 'b', 'c']
而对于不可变对象,比如str,对str进行操作呢:
>>> a = 'abc'
>>> a.replace('a', 'A')
'Abc'
>>> a
'abc'
虽然字符串有个replace()方法,也确实变出了'Abc',但变量a最后仍是'abc',应该怎么理解呢?
我们先把代码改成下面这样:
>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc'
要始终牢记的是,a是变量,而'abc'才是字符串对象!有些时候,我们经常说,对象a的内容是'abc',但其实是指,a本身是一个变量,它指向的对象的内容才是'abc':

当我们调用a.replace('a', 'A')时,实际上调用方法replace是作用在字符串对象'abc'上的,而这个方法虽然名字叫replace,但却没有改变字符串'abc'的内容。相反,replace方法创建了一个新字符串'Abc'并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串'abc',但变量b却指向新字符串'Abc'了:
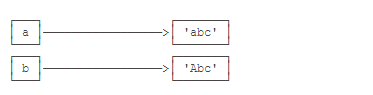
所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
小结
使用key-value存储结构的dict在Python中非常有用,选择不可变对象作为key很重要,最常用的key是字符串。
tuple虽然是不变对象,但试试把(1, 2, 3)和(1, [2, 3])放入dict或set中,并解释结果。
python3-disc和set的更多相关文章
- Python3 栈的实现
这篇博客主要记录我在学习python算法时实现栈的过程,这里栈的实现只是最简单的实现,其中也包括符号匹配,前缀.中缀以及后缀表达式的实例.参考书目为: problem-solving-with-alg ...
- Python3玩转儿 机器学习(4)
jupyternotebook 的使用方法¶ 最基本的使用¶ In [1]: 1+2 Out[1]: 3 菜单树¶ File¶ |------> New Notebook --- ...
- python3 threading初体验
python3中thread模块已被废弃,不能在使用thread模块,为了兼容性,python3将thread命名为_thread.python3中我们可以使用threading进行代替. threa ...
- Python3中的字符串函数学习总结
这篇文章主要介绍了Python3中的字符串函数学习总结,本文讲解了格式化类方法.查找 & 替换类方法.拆分 & 组合类方法等内容,需要的朋友可以参考下. Sequence Types ...
- Mac-OSX的Python3.5虚拟环境下安装Opencv
Mac-OSX的Python3.5虚拟环境下安装Opencv 1 关键词 关键词:Mac,OSX,Python3.5,Virtualenv,Opencv 2 概述 本文是一篇 环境搭建 的基础 ...
- Ubuntu部署python3.5的开发和运行环境
Ubuntu部署python3.5的开发和运行环境 1 概述 由于最近项目全部由python2.x转向 python3.x(使用目前最新的 python3.5.1) ,之前的云主机的的默认python ...
- Python3 登陆网页并保持cookie
网页登陆 网页登陆的原理都是,保持一个sessionid在cookie然后,根据sessionid在服务端找到cookie进行用户识别 python实现 由于python的简单以及丰富的类库是开发网络 ...
- 阿里云 SDK python3支持
最近的一个项目需要操作阿里云的RDS,项目使用python3,让人惊讶的是官方的SDK竟然只支持python2 在阿里云现有SDK上改了改,文件的修改只涉及aliyun/api/base.py,详见h ...
- python3爬取1024图片
这两年python特别火,火到博客园现在也是隔三差五的出现一些python的文章.各种开源软件.各种爬虫算法纷纷开路,作为互联网行业的IT狗自然看的我也是心痒痒,于是趁着这个雾霾横行的周末瞅了两眼,作 ...
- CentOS7中安装Python3.5
1.下载 https://www.python.org/ftp/python/3.5.2/Python-3.5.2.tgz 2.上传到服务器 3. 安装相关依赖 yum install gcc ope ...
随机推荐
- MySQL高可用架构之MySQL5.7组复制MGR
MySQL高可用架构之MySQL5.7组复制MGR########################################################################### ...
- 【C++进阶:STL常见性质2】
一般STL函数接收迭代器参数的规则为:[it1, it2) 左闭右开区间: vector<int> scores; scores.erase(scores.begin(),scores.e ...
- Delphi XE2 之 FireMonkey 入门(1)
Delphi XE2 的 FireMonkey 是跨平台的, 暂时只准备看看它在 Windows 下(我是 32 位 Win7)的应用情况. 很新的东西, 相信有了它, 以后的界面将会更灵活.漂亮, ...
- 阶段1 语言基础+高级_1-3-Java语言高级_06-File类与IO流_05 IO字符流_6_字符输出流写数据的其他方法
从1开始写写三个字符 最后多了个bcd 写入字符串 字符串的一部分
- 16/7/7_PHP-方法重载
PHP中的重载指的是动态的创建属性与方法,是通过魔术方法来实现的.属性的重载通过__set,__get,__isset,__unset来分别实现对不存在属性的赋值.读取.判断属性是否设置.销毁属性. ...
- 16/7/7_PHP-面向对象关键词
转载地址: http://blog.sina.com.cn/s/blog_5182b171010092fb.html PHP5 是一具备了大部分面向对象语言的特性的语言,比PHP4 有了很多的面向对象 ...
- C#7.0新特性和语法糖详解
转自IT之家网--DotNet码农:https://www.ithome.com/html/win10/305148.htm 伴随Visual Studio 2017的发布,C#7.0开始正式走上工作 ...
- 神器 工具 推荐 SRDebugger
unity asset store 关联下载 ,添加这个书签 javascript:var url = window.location.href;var id = url.substr(url.la ...
- 应用安全 - 代码审计 -Java
Java %c0%ae 安全模式绕过漏洞 原理 在Java端"%c0%ae"解析为"\uC0AE",最后转义为ASCCII低字符-".".通 ...
- 将字符串转换成C#认可的对象(有键值对的对象)
var resobj = Newtonsoft.Json.JsonConvert.DeserializeObject<Newtonsoft.Json.Linq.JArray>(result ...