spark MLlib 概念 4: 协同过滤(CF)
1. 定义

2. 实现过程
协同过滤一般需要1)用户积极参与;2)用户表达他们的兴趣;3)能够找出相同兴趣用户的算法。
推荐系统典型的工作流程如下:
- 用户对一些物品评分来表达他们的兴趣或偏好;
- 系统根据评分找出“最相似”用户;
- 对于兴趣相似的用户组内部,如果一部分用户A对某物品X给了很高评分,而其他的用户Y还没有对X评分(还没参与,比如对于一部电影,可能还没看过),就把X推荐给用户Y。
Collaborative filtering algorithms often require (1) users’ active participation, (2) an easy way to represent users’ interests to the system, and (3) algorithms that are able to match people with similar interests.
Typically, the workflow of a collaborative filtering system is:
- A user expresses his or her preferences by rating items (e.g. books, movies or CDs) of the system. These ratings can be viewed as an approximate representation of the user's interest in the corresponding domain.
- The system matches this user’s ratings against other users’ and finds the people with most “similar” tastes.
- With similar users, the system recommends items that the similar users have rated highly but not yet being rated by this user (presumably the absence of rating is often considered as the unfamiliarity of an item)
A key problem of collaborative filtering is how to combine and weight the preferences of user neighbors. Sometimes, users can immediately rate the recommended items. As a result, the system gains an increasingly accurate representation of user preferences over time.
3. 公式
Memory-based[edit]
一般情况,有 基于邻近关系、基于用户、基于话题三种类型的推荐系统。例如,
基于用户u对话题i的评分,可以通过“相似用户”的评分,通过一个聚合函数(aggr)计算出来。
Typical examples of this mechanism are neighbourhood based CF and item-based/user-based top-N recommendations.[3] For example, in user based approaches, the value of ratings user 'u' gives to item 'i' is calculated as an aggregation of some similar users rating to the item:

其中,U代表与u最相似且已经对i话题评分的N个用户集合
where 'U' denotes the set of top 'N' users that are most similar to user 'u' who rated item 'i'.
常见的聚合函数(aggr)有:
Some examples of the aggregation function includes:
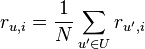 平均值
平均值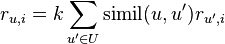 相似度加权平均值
相似度加权平均值 修正式相似度加权平均值
修正式相似度加权平均值
where k is a normalizing factor defined as 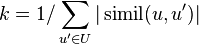 . and
. and 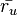 is the average rating of user u for all the items rated by that user.
is the average rating of user u for all the items rated by that user.
基于相似度的算法:
找出用户或话题相似度是它的重要部分。一般使用皮尔森相似度(平移无关特点)和余弦相似度算法。
The neighborhood-based algorithm calculates the similarity between two users or items, produces a prediction for the user taking the weighted average of all the ratings. Similarity computation between items or users is an important part of this approach. Multiple mechanisms such as Pearson correlation and vector cosinebased similarity are used for this.
The Pearson correlation similarity of two users x, y is defined as
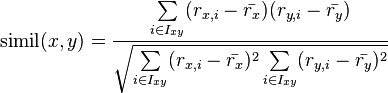
where Ixy is the set of items rated by both user x and user y.
The cosine-based approach defines the cosine-similarity between two users x and y as:[4]
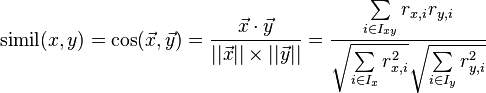
当找到最相似的N个用户后,使用knn算法将对应的度量属性聚合到被推荐的用户上。
The user based top-N recommendation algorithm identifies the k most similar users to an active user using similarity based vector model. After the k most similar users are found, their corresponding user-item matrices are aggregated to identify the set of items to be recommended. A popular method to find the similar users is the Locality-sensitive hashing, which implements the nearest neighbor mechanism in linear time.
优点:
- 结果很容易解析(这点对推荐系统很重要);
- 容易使用;
- 可以增量计算;
- 不需要关心话题的内容;
- 对协同评分的话题扩展性好?
The advantages with this approach include: the explainability of the results, which is an important aspect of recommendation systems; it is easy to create and use; new data can be added easily and incrementally; it need not consider the content of the items being recommended; and the mechanism scales well with co-rated items.
缺点:
- 依赖于人的评分;
- 稀疏数据性能差,而稀疏数据是很平常的
- 对大的数据集扩展性差
There are several disadvantages with this approach. First, it depends on human ratings. Second, its performance decreases when data gets sparse, which is frequent with web related items. This prevents the scalability of this approach and has problems with large datasets. Although it can efficiently handle new users because it relies on a data structure, adding new items becomes more complicated since that representation usually relies on a specific vector space. That would require to include the new item and re-insert all the elements in the structure.
Model-based[edit]
基于模型的CF。
Models are developed using data mining, machine learning algorithms to find patterns based on training data. These are used to make predictions for real data. There are many model-based CF algorithms. These include Bayesian networks, clustering models, latent semantic models such as singular value decomposition,probabilistic latent semantic analysis, Multiple Multiplicative Factor, Latent Dirichlet allocation and markov decision process based models.[5]
这种方法通过更整合的目的去揭露潜在的属性,且大部分通过某个分类或聚类技术实现,参数的数量可通过PCA来减少。
This approach has a more holistic goal to uncover latent factors that explain observed ratings.[6] Most of the models are based on creating a classification or clustering technique to identify the user based on the test set. The number of the parameters can be reduced based on types of principal component analysis.
优点:稀疏数据和大数据扩展性好
There are several advantages with this paradigm. It handles the sparsity better than memory based ones. This helps with scalability with large data sets. It improves the prediction performance. It gives an intuitive rationale for the recommendations.
缺点:需要对预测质量和扩展性之间做出评估。参数的减少可能导致一些有用信息丢失。
The disadvantages with this approach are in the expensive model building. One needs to have a tradeoff between prediction performance and scalability. One can lose useful information due to reduction models. A number of models have difficulty explaining the predictions.
spark MLlib 概念 4: 协同过滤(CF)的更多相关文章
- 【Machine Learning】Mahout基于协同过滤(CF)的用户推荐
一.Mahout推荐算法简介 Mahout算法框架自带的推荐器有下面这些: l GenericUserBasedRecommender:基于用户的推荐器,用户数量少时速度快: l GenericI ...
- Spark Mllib里的协调过滤的概念和实现步骤、LS、ALS的原理、ALS算法优化过程的推导、隐式反馈和ALS-WR算法
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 (广泛采用) 协调过滤的概念 在现今的推荐技术和算法中,最被大家广泛认可和 ...
- 协同过滤 CF & ALS 及在Spark上的实现
使用Spark进行ALS编程的例子可以看:http://www.cnblogs.com/charlesblc/p/6165201.html ALS:alternating least squares ...
- Spark机器学习(11):协同过滤算法
协同过滤(Collaborative Filtering,CF)算法是一种常用的推荐算法,它的思想就是找出相似的用户或产品,向用户推荐相似的物品,或者把物品推荐给相似的用户.怎样评价用户对商品的偏好? ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 推荐系统算法学习(一)——协同过滤(CF) MF FM FFM
https://blog.csdn.net/qq_23269761/article/details/81355383 1.协同过滤(CF)[基于内存的协同过滤] 优点:简单,可解释 缺点:在稀疏情况下 ...
- 协同过滤CF算法之入门
数据规整 首先将评分数据从 ratings.dat 中读出到一个 DataFrame 里: >>> import pandas as pd In [2]: import pandas ...
- spark MLlib 概念 6:ALS(Alternating Least Squares) or (ALS-WR)
Large-scale Parallel Collaborative Filtering for the Netflix Prize http://www.hpl.hp.com/personal/Ro ...
- 案例:Spark基于用户的协同过滤算法
https://mp.weixin.qq.com/s?__biz=MzA3MDY0NTMxOQ==&mid=2247484291&idx=1&sn=4599b4e31c2190 ...
随机推荐
- Python新式类与经典类(旧式类)的区别
看写poc的时候看到的,思考了半天,现在解决了 转载自http://blog.csdn.net/zimou5581/article/details/53053775 Python中类分两种:旧式类和新 ...
- CentOS查看Java进程并部署jar包
查看Java进程获取pid号:ps -ef|grep java|grep -v grep 部署Javajar包并指定输出日志文件(null不输出):nohup java -jar xx.jar > ...
- redis加入systemctl服务
来自:https://blog.csdn.net/weixin_41114593/article/details/82383716 第一步 安装redis去官网下载最新的redis版本 安装官网 ...
- oracle 12C的新特性-CDB和PDB
1.前言 CDB与PDB是Oracle 12C引入的新特性,在ORACLE 12C数据库引入的多租用户环境(Multitenant Environment)中,允许一个数据库容器(CDB)承载多个可插 ...
- QQ恶搞 - 让艾特你的人语无伦次
效果图: 实现过程: 代码: 将上面的代码复制添加到你的群名片后面即可. 原理解析: 这个代码是一个Unicode控制字符 - RLO,它可以控制在它后面的所有文本都已倒序的方式显示.在qq群艾特 ...
- 解决引导内核遇到undefined instruction的错误
其实在上一篇随笔之前,就是在启动linux 内核的时候,出了点问题 刚Starting kernel ...就出现了undefined instrction,这是什么问题呢? 在网上也搜了不少资料,有 ...
- centos6.8 上传文件到amazon s3
centos6.8 上传文件到amazon s3 0.参考 AWS CLI Cinnabd Reference Possible to sync a single file with aws s3 s ...
- xml配置文件命名空间学习
xmlns(XML Namespaces的缩写)是一个属性,是XML(标准通用标记语言的子集)命名空间.作用是赋予命名空间一个唯一的名称. 编写Spring或者Maven或者其他需要用到XML文档的程 ...
- maven项目编译报错:Type Dynamic Web Module 3.0 requires Java 1.6 or newer.
在maven的pom.xml文件中增加: <build> <plugins> <plugin> <groupId>org.a ...
- 细数meta标签的奥秘
因为看到了一个很不错的h5自适应网站,觉得很不错,于是好奇心作祟,让我翻开了它的源码一探究竟,最先研究的是它的meta标签,好了,废话不多说,以下是我总结的和比较实用的meta标签,如有错误,请多多指 ...