【Spark机器学习速成宝典】基础篇04数据类型(Python版)
目录
Vector
LabeledPoint
Matrix
使用C4.5算法生成决策树
使用CART算法生成决策树
预剪枝和后剪枝
应用:遇到连续与缺失值怎么办?
多变量决策树
Python代码(sklearn库)
|
Vector |
一个数学向量。MLlib 既支持稠密向量也支持稀疏向量,前者表示向量的每一位都存储下来,后者则只存储非零位以节约空间。后面会简单讨论不同种类的向量。向量可以通过mllib.linalg.Vectors 类创建出来
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') import numpy as np
import scipy.sparse as sps
from pyspark.mllib.linalg import Vectors # Use a NumPy array as a dense vector.使用NumPy数组作为稠密向量
dv1 = np.array([1.0, 0.0, 3.0])
# Use a Python list as a dense vector.使用Python list作为稠密向量
dv2 = [1.0, 0.0, 3.0]
# Create a SparseVector.创建一个稀疏向量<1.0 0.0 2.0 3.0>的两种方式
sv1 = Vectors.sparse(4, {0: 1.0, 2: 2.0})
sv2 = Vectors.sparse(4, [0, 2], [1.0, 2.0])
# Use a single-column SciPy csc_matrix as a sparse vector.使用单列的csc_matrix作为稀疏向量
sv2 = sps.csc_matrix((np.array([10.0, 30.0]), np.array([0, 2]), np.array([0, 2])), shape=(3, 1))
|
LabledPoint |
在诸如分类和回归这样的监督式学习(supervised learning)算法中,LabeledPoint 用来表示带标签的数据点。它包含一个特征向量与一个标签(由一个浮点数表示),位置在mllib.regression 包中。
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') from pyspark.mllib.linalg import SparseVector
from pyspark.mllib.regression import LabeledPoint # Create a labeled point with a positive label and a dense feature vector.使用稠密向量创建一个带有正标记LabeledPoint
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0]) # Create a labeled point with a negative label and a sparse feature vector.使用稀疏向量创建一个带有负标记LabeledPoint
neg = LabeledPoint(0.0, SparseVector(3, [0, 2], [1.0, 3.0]))
|
Matrix |
矩阵的基类是Matrix,我们提供了两种实现方法:稠密矩阵和稀疏矩阵。建议使用矩阵实现的工厂方法来创建矩阵。
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') from pyspark.mllib.linalg import Matrix, Matrices # Create a dense matrix ((1.0, 2.0), (3.0, 4.0), (5.0, 6.0))
dm2 = Matrices.dense(3, 2, [1, 2, 3, 4, 5, 6]) # Create a sparse matrix ((9.0, 0.0), (0.0, 8.0), (0.0, 6.0))
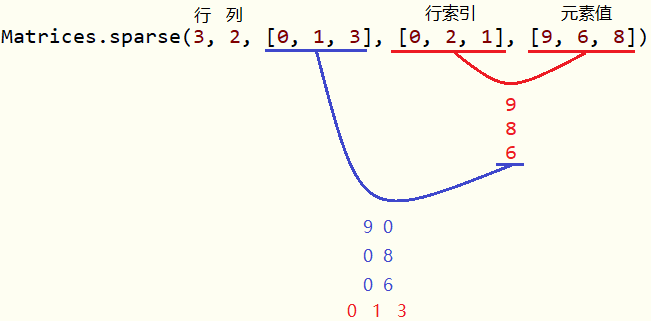
sm = Matrices.sparse(3, 2, [0, 1, 3], [0, 2, 1], [9, 6, 8])
|
什么是决策树(Decision Tree)4 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)5 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)6 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)7 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)8 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
【Spark机器学习速成宝典】基础篇04数据类型(Python版)的更多相关文章
- 【Spark机器学习速成宝典】基础篇01Windows下spark开发环境搭建+sbt+idea(Scala版)
注意: spark用2.1.1 scala用2.11.11 材料准备 spark安装包 JDK 8 IDEA开发工具 scala 2.11.8 (注:spark2.1.0环境于scala2.11环境开 ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 【Spark机器学习速成宝典】基础篇02RDD常见的操作(Python版)
目录 引例入门:textFile.collect.filter.first.persist.count 创建RDD的方式:parallelize.textFile 转化操作:map.filter.fl ...
- 【Spark机器学习速成宝典】基础篇03数据读取与保存(Python版)
目录 保存为文本文件:saveAsTextFile 保存为json:saveAsTextFile 保存为SequenceFile:saveAsSequenceFile 读取hive 保存为文本文件:s ...
- 【Spark机器学习速成宝典】模型篇08保序回归【Isotonic Regression】(Python版)
目录 保序回归原理 保序回归代码(Spark Python) 保序回归原理 待续... 返回目录 保序回归代码(Spark Python) 代码里数据:https://pan.baidu.com/s/ ...
- 【Spark机器学习速成宝典】模型篇07梯度提升树【Gradient-Boosted Trees】(Python版)
目录 梯度提升树原理 梯度提升树代码(Spark Python) 梯度提升树原理 待续... 返回目录 梯度提升树代码(Spark Python) 代码里数据:https://pan.baidu.co ...
- 【Spark机器学习速成宝典】模型篇06随机森林【Random Forests】(Python版)
目录 随机森林原理 随机森林代码(Spark Python) 随机森林原理 参考:http://www.cnblogs.com/itmorn/p/8269334.html 返回目录 随机森林代码(Sp ...
- 【Spark机器学习速成宝典】模型篇05决策树【Decision Tree】(Python版)
目录 决策树原理 决策树代码(Spark Python) 决策树原理 详见博文:http://www.cnblogs.com/itmorn/p/7918797.html 返回目录 决策树代码(Spar ...
- 【Spark机器学习速成宝典】模型篇03线性回归【LR】(Python版)
目录 线性回归原理 线性回归代码(Spark Python) 线性回归原理 详见博文:http://www.cnblogs.com/itmorn/p/7873083.html 返回目录 线性回归代码( ...
随机推荐
- MySQL安装过程中遇到的错误代码为1045的解决方法
mysql的安装包,及其图形化破解软件:https://pan.baidu.com/s/1PIzaEGpC9QEPUwZ8OowhCw 二级压缩包下边的 视图化管理软件:Navicat.exe 发 ...
- 多列表zip合并的csv持久化储存
有时xpath爬取数据之后会返回多个列表,这些列表的长度一样,这时候可以用zip()合并,然后返回一个zip对象,直接传入储存函数,进行持久化储存 例如: name=['张三','李四','王五'] ...
- 微信小程序wx.showActionSheet调用客服信息功能
微信小程序wx.showActionSheet调用客服消息功能 官方文档的代码: wx.showActionSheet({ itemList: ['A', 'B', 'C'], success (re ...
- 目标 - 在虚拟机CentOS7中无图形界面安装Oracle11G R2版本
参考: https://www.cnblogs.com/yejingcn/p/10278473.html centos7启动oracle su - oracle //切换到自己的oracle账户 ls ...
- Python之路:进程、线程
目录 一.进程与线程区别 1.1 什么是线程 1.2 什么是进程 1.3 进程与线程的区别 二.Python GIL全局解释器锁 三.线程 3.1 threading模块 3.2 Join & ...
- Tableau 分群
对数据的特征进行分析,分群. 数据选用的是Iris data 下载地址:http://archive.ics.uci.edu/ml/machine-learning-databases/iris/ 1 ...
- https://github.com/zabbix/zabbix-docker 安装
docker-compose -f ./docker-compose_v3_centos_mysql_latest.yaml up -d 解压文件,运行即可
- Linux下Discuz!7.2 LAMP环境搭建
linux下Discuz LAMP环境搭建 1.需要的源代码 httpd-2.2.15.tar.gz mysql-5.1.44.tar.gz php-5.3.2.tar.gz ...
- 对Spring Boot 及Mybatis简单应用
因为没有系统的学习过SpringBoot,在对照一个别人的SpringBoot项目,进行简单的搭建及使用. 1.首先创建SpringBoot项目之后,这里会有默认的启动类,基本不需要配置,在类的上边有 ...
- iOS设置UITableViewCell的选中时的颜色
1.系统默认的颜色设置 //无色 cell.selectionStyle = UITableViewCellSelectionStyleNone; //蓝色 cell.selectio ...