【Spark机器学习速成宝典】基础篇04数据类型(Python版)
目录
Vector
LabeledPoint
Matrix
使用C4.5算法生成决策树
使用CART算法生成决策树
预剪枝和后剪枝
应用:遇到连续与缺失值怎么办?
多变量决策树
Python代码(sklearn库)
|
Vector |
一个数学向量。MLlib 既支持稠密向量也支持稀疏向量,前者表示向量的每一位都存储下来,后者则只存储非零位以节约空间。后面会简单讨论不同种类的向量。向量可以通过mllib.linalg.Vectors 类创建出来
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') import numpy as np
import scipy.sparse as sps
from pyspark.mllib.linalg import Vectors # Use a NumPy array as a dense vector.使用NumPy数组作为稠密向量
dv1 = np.array([1.0, 0.0, 3.0])
# Use a Python list as a dense vector.使用Python list作为稠密向量
dv2 = [1.0, 0.0, 3.0]
# Create a SparseVector.创建一个稀疏向量<1.0 0.0 2.0 3.0>的两种方式
sv1 = Vectors.sparse(4, {0: 1.0, 2: 2.0})
sv2 = Vectors.sparse(4, [0, 2], [1.0, 2.0])
# Use a single-column SciPy csc_matrix as a sparse vector.使用单列的csc_matrix作为稀疏向量
sv2 = sps.csc_matrix((np.array([10.0, 30.0]), np.array([0, 2]), np.array([0, 2])), shape=(3, 1))
|
LabledPoint |
在诸如分类和回归这样的监督式学习(supervised learning)算法中,LabeledPoint 用来表示带标签的数据点。它包含一个特征向量与一个标签(由一个浮点数表示),位置在mllib.regression 包中。
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') from pyspark.mllib.linalg import SparseVector
from pyspark.mllib.regression import LabeledPoint # Create a labeled point with a positive label and a dense feature vector.使用稠密向量创建一个带有正标记LabeledPoint
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0]) # Create a labeled point with a negative label and a sparse feature vector.使用稀疏向量创建一个带有负标记LabeledPoint
neg = LabeledPoint(0.0, SparseVector(3, [0, 2], [1.0, 3.0]))
|
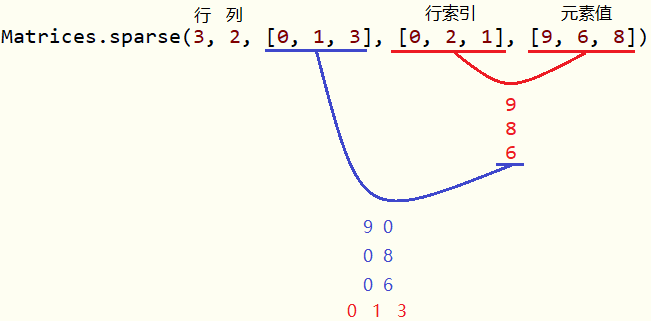
Matrix |
矩阵的基类是Matrix,我们提供了两种实现方法:稠密矩阵和稀疏矩阵。建议使用矩阵实现的工厂方法来创建矩阵。
# -*-coding=utf-8 -*-
from pyspark import SparkConf, SparkContext
sc = SparkContext('local') from pyspark.mllib.linalg import Matrix, Matrices # Create a dense matrix ((1.0, 2.0), (3.0, 4.0), (5.0, 6.0))
dm2 = Matrices.dense(3, 2, [1, 2, 3, 4, 5, 6]) # Create a sparse matrix ((9.0, 0.0), (0.0, 8.0), (0.0, 6.0))
sm = Matrices.sparse(3, 2, [0, 1, 3], [0, 2, 1], [9, 6, 8])
|
什么是决策树(Decision Tree)4 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)5 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)6 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)7 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
|
什么是决策树(Decision Tree)8 |
引例
现有训练集如下,请训练一个决策树模型,对未来的西瓜的优劣做预测。
【Spark机器学习速成宝典】基础篇04数据类型(Python版)的更多相关文章
- 【Spark机器学习速成宝典】基础篇01Windows下spark开发环境搭建+sbt+idea(Scala版)
注意: spark用2.1.1 scala用2.11.11 材料准备 spark安装包 JDK 8 IDEA开发工具 scala 2.11.8 (注:spark2.1.0环境于scala2.11环境开 ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 【Spark机器学习速成宝典】基础篇02RDD常见的操作(Python版)
目录 引例入门:textFile.collect.filter.first.persist.count 创建RDD的方式:parallelize.textFile 转化操作:map.filter.fl ...
- 【Spark机器学习速成宝典】基础篇03数据读取与保存(Python版)
目录 保存为文本文件:saveAsTextFile 保存为json:saveAsTextFile 保存为SequenceFile:saveAsSequenceFile 读取hive 保存为文本文件:s ...
- 【Spark机器学习速成宝典】模型篇08保序回归【Isotonic Regression】(Python版)
目录 保序回归原理 保序回归代码(Spark Python) 保序回归原理 待续... 返回目录 保序回归代码(Spark Python) 代码里数据:https://pan.baidu.com/s/ ...
- 【Spark机器学习速成宝典】模型篇07梯度提升树【Gradient-Boosted Trees】(Python版)
目录 梯度提升树原理 梯度提升树代码(Spark Python) 梯度提升树原理 待续... 返回目录 梯度提升树代码(Spark Python) 代码里数据:https://pan.baidu.co ...
- 【Spark机器学习速成宝典】模型篇06随机森林【Random Forests】(Python版)
目录 随机森林原理 随机森林代码(Spark Python) 随机森林原理 参考:http://www.cnblogs.com/itmorn/p/8269334.html 返回目录 随机森林代码(Sp ...
- 【Spark机器学习速成宝典】模型篇05决策树【Decision Tree】(Python版)
目录 决策树原理 决策树代码(Spark Python) 决策树原理 详见博文:http://www.cnblogs.com/itmorn/p/7918797.html 返回目录 决策树代码(Spar ...
- 【Spark机器学习速成宝典】模型篇03线性回归【LR】(Python版)
目录 线性回归原理 线性回归代码(Spark Python) 线性回归原理 详见博文:http://www.cnblogs.com/itmorn/p/7873083.html 返回目录 线性回归代码( ...
随机推荐
- yii自定义验证
自定义验证类 class BaseModel extends Model { public function rules() { return [ ['obj', ContentSecurityVal ...
- 04 Websocket和Websocketed
一.web socket事件和方法 有了HTTP协议为什么还需要Websocket这种协议呢?因为HTTP协议发起的通信只能通过客户端发起,然后服务端才可以将消息回应到客户端.因此HTTP协议做不到服 ...
- 【Java面试题】解释内存中的栈(stack)、堆(heap)和静态存储区的用法
Java面试题:解释内存中的栈(stack).堆(heap)和静态存储区的用法 堆区: 专门用来保存对象的实例(new 创建的对象和数组),实际上也只是保存对象实例的属性值,属性的类型和对象本身的类型 ...
- js 发送异步请求
js用XMLHttpRequest发送异步请求 发送GET请求 var xhr = new XMLHttpRequest(); xhr.open('GET',url);//url为请求地址 xhr.r ...
- centos7 部署haproxy
第一章 :haproxy介绍 1.1 简介 HAProxy 是一款提供高可用性.负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费.快速并且可靠的一种解决方案. ...
- ActiveMQ基础01——Linux下载安装ActiveMQ
1.下载 下载地址:http://activemq.apache.org/ 点击按钮 下载Linux下最新版安装包,点击即可下载 2.安装ActiveMQ 将之前下载的安装包上传到linux当中,一般 ...
- 002-loganalyzer装完报错no syslog records found
1.登录mysql查看库Syslog中的表SystemEvents;是否有返回数据 # select * from Syslog.SystemEvents; #又返回数据说明rsyslog配置正确, ...
- MSSQL数据库备份还原常用SQL语句及注意
.备份数据库 backup database db_name to disk='d:\db_name.bak' with format --通过使用with format可以做到覆盖任何现有的备份和创 ...
- ftp上传下载功能实现
该程序分为客户端和服务端,目前已经实现以下功能: 1. 多用户同时登陆 2. 用户登陆,加密认证 3. 上传/下载文件,保证文件一致性 4. 传输过程中现实进度条 5. 不同用户家目录不同,且只能访问 ...
- qa角色记一次测试过程回溯
一.测试过程简述 a项目依赖b项目新功能,ab项目一起提测 1.测试人员:两老一新 2.测试过程:第一轮,三人执行用例 第二轮,三人各自模块发散 第三轮,三人交叉测试 第四轮,两老投入b项目性能以及接 ...