PostgreSQL数据库表的内部结构
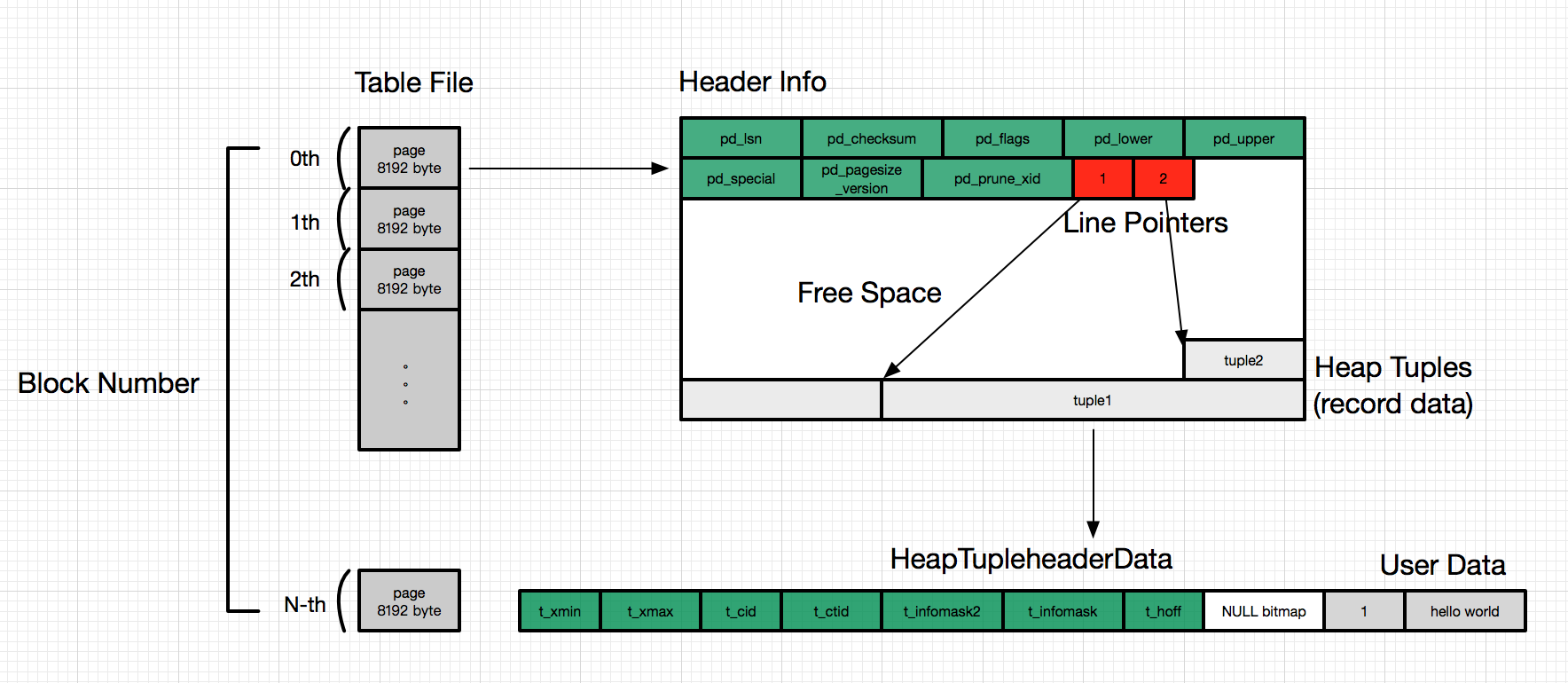
A page within a table contains three kinds of data described as follows:
- heap tuple(s) – A heap tuple is a record data itself. They are stacked in order from the bottom of the page. The internal structure of tuple is described in Section 5.2 and Chapter 9 as the knowledge of both Concurrency Control(CC) and WAL in PostgreSQL are required.
- line pointer(s) – A line pointer is 4 byte long and holds a pointer to each heap tuple. It is also called an item pointer.
- Line pointers form a simple array, which plays the role of index to the tuples. Each index is numbered sequentially from 1, and called offset number. When a new tuple is added to the page, a new line pointer is also pushed onto the array to point to the new one.
- header data – A header data defined by the structure PageHeaderData is allocated in the beginning of the page. It is 24 byte long and contains general information about the page. The major variables of the structure are described below.
- pd_lsn – This variable stores the LSN of XLOG record written by the last change of this page. It is an 8-byte unsigned integer, related to the WAL (Write-Ahead Logging) mechanism. The details are described in Chapter 9.
- pd_checksum – This variable stores the checksum value of this page. (Note that this variable is supported in version 9.3 or later; in earlier versions, this part had stored the timelineId of the page.)
- pd_lower, pd_upper – pd_lower points to the end of line pointers, and pd_upper to the beginning of the newest heap tuple.
- pd_special – This variable is for indexes. In the page within tables, it points to the end of the page. (In the page within indexes, it points to the beginning of special space which is the data area held only by indexes and contains the particular data according to the kind of index types such as B-tree, GiST, GiN, etc.)
An empty space between the end of line pointers and the beginning of the newest tuple is referred to as free space or hole.
To identify a tuple within the table, tuple identifier (TID) is internally used. A TID comprises a pair of values: the block number of the page that contains the tuple, and the offset number of the line pointer that points to the tuple. A typical example of its usage is index. See more detail in Section 1.4.2.
While the HeapTupleHeaderData structure contains seven fields, four fields are required in the subsequent sections.
- t_xmin holds the txid of the transaction that inserted this tuple.
- t_xmax holds the txid of the transaction that deleted or updated this tuple. If this tuple has not been deleted or updated, t_xmax is set to 0, which means INVALID.
- t_cid holds the command id (cid), which means how many SQL commands were executed before this command was executed within the current transaction beginning from 0. For example, assume that we execute three INSERT commands within a single transaction: 'BEGIN; INSERT; INSERT; INSERT; COMMIT;'. If the first command inserts this tuple, t_cid is set to 0. If the second command inserts this, t_cid is set to 1, and so on.
- t_ctid holds the tuple identifier (tid) that points to itself or a new tuple. tid, described in Section 1.3, is used to identify a tuple within a table. When this tuple is updated, the t_ctid of this tuple points to the new tuple; otherwise, the t_ctid points to itself.
引用:http://www.interdb.jp/pg/pgsql01.html
PostgreSQL数据库表的内部结构的更多相关文章
- mybatis使用注解往postgresql数据库表insert数据[主键自增]的写法
建表SQL: DROP TABLE IF EXISTS person; CREATE TABLE person( person_id serial PRIMARY KEY NOT NULL, pers ...
- Solr 4.4.0利用dataimporthandler导入postgresql数据库表
将数据库edbstore的edbtore schema下的customers表导入到solr 1. 首先查看customers表字段信息 edbstore=> \d customers Tabl ...
- PostgreSQL数据库表名的大小写实验
磨砺技术珠矶,践行数据之道,追求卓越价值回到上一级页面:PostgreSQL基础知识与基本操作索引页 回到顶级页面:PostgreSQL索引页[作者 高健@博客园 luckyjackgao@g ...
- PostgreSQL数据库中获取表主键名称
PostgreSQL数据库中获取表主键名称 一.如下表示,要获取teacher表的主键信息: select pg_constraint.conname as pk_name,pg_attribute. ...
- .netcore2.1 使用postgresql数据库,不能实现表的CRUD问题
PostgreSQL对表名.字段名都是区分大小写的.为了兼容其他的数据库程序代码的编写,推荐使用小写加_的方式,例如:swagger_info 我们使用.netcore连接postgresql数据库时 ...
- Java连接postgreSQL数据库,找不到表。
postgreSQL数据库遵守SQL标准,表名库名不区分大小写. 数据库中是存在 gongan_address_ALL的表的,但是执行下列代码就会出错. stmt = c.createStatemen ...
- 数据库并发事务控制四:postgresql数据库的锁机制二:表锁 <转>
在博文<数据库并发事务控制四:postgresql数据库的锁机制 > http://blog.csdn.net/beiigang/article/details/43302947 中后面提 ...
- PostgreSQL介绍以及如何开发框架中使用PostgreSQL数据库
最近准备下PostgreSQL数据库开发的相关知识,本文把总结的PPT内容通过博客记录分享,本随笔的主要内容是介绍PostgreSQL数据库的基础信息,以及如何在我们的开发框架中使用PostgreSQ ...
- 对于多个数据库表对应一个Model问题的思考
最近做项目遇到一个场景,就是客户要求为其下属的每一个分支机构建一个表存储相关数据,而这些表的结构都是一样的,只是分属于不同的机构.这个问题抽象一下就是多个数据库表对应一个Model(或者叫实体类).有 ...
随机推荐
- [Linux系统] (4)脚本编程
一.bash shell 可以理解为一种解释器和启动器,解释命令文本,并执行命令. 命令来源: 用户交互输入 文本文件输入 1.示例,写一个最简单的文本 vi test.txt 写入以下内容: ech ...
- python解析字体反爬
爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用python爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码.这种一般是网站设置了字体反爬 一.58同城 用谷歌浏览器打开 ...
- Python3学习笔记(十二):闭包
闭包定义: 在一个外函数中定义了一个内函数,内函数里引用了外函数的临时变量,并且外函数的返回值是内函数的引用.这样就构成了一个闭包. 我们先来看一个简单的函数: def outer(a): b = 1 ...
- springBoot 整合 mybatis 项目实战
二.springBoot 整合 mybatis 项目实战 前言 上一篇文章开始了我们的springboot序篇,我们配置了mysql数据库,但是我们sql语句直接写在controller中并且使用 ...
- [论文理解] Spatial Transformer Networks
Spatial Transformer Networks 简介 本文提出了能够学习feature仿射变换的一种结构,并且该结构不需要给其他额外的监督信息,网络自己就能学习到对预测结果有用的仿射变换.因 ...
- Linux高级调试与优化——用户态堆
内存问题是软件世界的住房问题 嵌入式Linux系统中,物理内存资源通常比较紧张,而不同的进程可能不停地分配和释放不同大小的内存,因此需要一套高效的内存管理机制. 内存管理可以分为三个层次,自底向上分别 ...
- Python2.x与Python3.x的主要区别(转)
python2.x和python3.x版本有很大的差异,除了依赖包的名称变化很大外,其主要差异总结如下: 1)print函数 Python3中,print函数的括号是必须的,Python2是可选的. ...
- layui数据加载中遮罩层的实现
1.load方法提供三种风格供选择. 方法一:loadIndex = layer.load(); //不传参,默认0 方法二:loadIndex = layer.load(1); // 1,另外一种风 ...
- 关于Layui的表格中分页处理
table.render({ elem: '#test' ,height:'full-125' ,url:'data.php' ,cellMinWidth: 80 //全局定义常规单元格的最小宽度,l ...
- leetcode 198. House Robber 、 213. House Robber II 、337. House Robber III 、256. Paint House(lintcode 515) 、265. Paint House II(lintcode 516) 、276. Paint Fence(lintcode 514)
House Robber:不能相邻,求能获得的最大值 House Robber II:不能相邻且第一个和最后一个不能同时取,求能获得的最大值 House Robber III:二叉树下的不能相邻,求能 ...