Spark-Core RDD概述
一、什么是RDD
1、RDD(Resilient Distributed DataSet)弹性分布式数据集
2、是Spark中最基本的数据抽象
3、在代码中是一个抽象类,它代表一个弹性的、不可变的、可分区,里面的元素可并行计算的集合
二、RDD的5个主要属性(property)
1、A list of partitions
(1)多个分区,分区可以看成是数据集的基本组成单位
(2)对于RDD来说,每个分区都会被一个计算任务处理,并决定了并行计算的粒度
(3)用户可以在创建 RDD 时指定 RDD 的分区数, 如果没有指定, 那么就会采用默认值. 默认值就是程序所分配到的 CPU Coure 的数目.
(4)每个分配的存储是由BlockManager实现的。每个分区都会被逻辑映射成BlockManager的一个Block,而这个Block会被一个Task负责计算
2、A function for computing each split
(1)计算每个切片(分区)的函数
(2)Spark 中 RDD 的计算是以分片为单位的, 每个 RDD 都会实现 compute 函数以达到这个目的.
3、A list of dependencies on other RDDs
(1)与其他 RDD 之间的依赖关系
(2)RDD 的每次转换都会生成一个新的 RDD, 所以 RDD 之间会形成类似于流水线一样的前后依赖关系. 在部分分区数据丢失时, Spark 可以通过这个依赖关系重新计算丢失的分区数据, 而不是对 RDD 的所有分区进行重新计算.
4、Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
(1)对存储键值对的 RDD, 还有一个可选的分区器.
(2)只有对于 key-value的 RDD, 才会有 Partitioner, 非key-value的 RDD 的 Partitioner 的值是 None.
(3) Partitiner 不但决定了 RDD 的分区数量, 也决定了 parent RDD Shuffle 输出时的分区数量.
5、Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
(1) 存储每个切片优先(preferred location)位置的列表. 比如对于一个 HDFS 文件来说, 这个列表保存的就是每个 Partition 所在文件块的位置. (2)按照“移动数据不如移动计算”的理念, Spark 在进行任务调度的时候, 会尽可能地将计算任务分配到其所要处理数据块的存储位置.
6、源码
/**
* A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,
* partitioned collection of elements that can be operated on in parallel. This class contains the
* basic operations available on all RDDs, such as `map`, `filter`, and `persist`. In addition,
* [[org.apache.spark.rdd.PairRDDFunctions]] contains operations available only on RDDs of key-value
* pairs, such as `groupByKey` and `join`;
* [[org.apache.spark.rdd.DoubleRDDFunctions]] contains operations available only on RDDs of
* Doubles; and
* [[org.apache.spark.rdd.SequenceFileRDDFunctions]] contains operations available on RDDs that
* can be saved as SequenceFiles.
* All operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)]
* through implicit.
*
* Internally, each RDD is characterized by five main properties:
*
16 * - A list of partitions
17 * - A function for computing each split
18 * - A list of dependencies on other RDDs
19 * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
20 * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
21 * an HDFS file)
*
* All of the scheduling and execution in Spark is done based on these methods, allowing each RDD
* to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for
* reading data from a new storage system) by overriding these functions. Please refer to the
* <a href="http://people.csail.mit.edu/matei/papers/2012/nsdi_spark.pdf">Spark paper</a>
* for more details on RDD internals.
*/
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
三、理解RDD
1、一个 RDD 可以简单的理解为一个分布式的元素集合
2、RDD表示只读的分区的数据集
3、对RDD进行改动,只能通过RDD的转换操作到新的RDD,并不会对原RDD有任何影响
4、在Spark中,所有的工作要么是创建RDD,要么是转换已经存在RDD为新的RDD上,然后去执行一些操作来得到一些计算结果
5、每个RDD被切分成多个分区(partition),每个分区可能会在集群中不同的节点
四、RDD特点
1、弹性
(1)存储的弹性:内存与磁盘的自动切换
(2)容错的弹性:数据丢失可以自动恢复
(3)计算的弹性:计算出错重试机制
(4)分片弹性:可更具需要重新分片
2、分区
(1)RDD逻辑上是分区的,每个分区的数据时抽象存在的,计算的时候回通过一个compute函数得到每个分区的数据
(2)如果 RDD 是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据
(3)如果 RDD 是通过其他 RDD 转换而来,则 compute函数是执行转换逻辑将其他 RDD的数据进行转换
3、只读
(1)RDD 是只读的,要想改变 RDD 中的数据,只能在现有 RDD 基础上创建新的 RDD。
(2)由一个 RDD 转换到另一个 RDD,可以通过丰富的转换算子实现,不再像 MapReduce 那样只能写map和reduce了。
(3)RDD 的操作算子包括两类:
1)一类叫做transformation,它是用来将 RDD 进行转化,构建 RDD 的血缘关系;
2)另一类叫做action,它是用来触发 RDD 进行计算,得到 RDD 的相关计算结果或者 保存 RDD 数据到文件系统中.
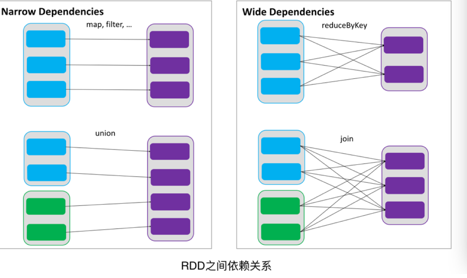
4、依赖(血缘)
(1)RDDs 通过操作算子进行转换,转换得到的新 RDD 包含了从其他 RDDs 衍生所必需的信息,RDDs 之间维护着这种血缘关系,也称之为依赖。
(2)依赖包括两种:
1)一种是窄依赖,RDDs 之间分区是一一对应的
2)另一种是宽依赖,下游 RDD 的每个分区与上游 RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。
5、缓存
如果在应用程序中多次使用同一个 RDD,可以将该 RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该 RDD 的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
如下图所示,RDD-1 经过一系列的转换后得到 RDD-n 并保存到 hdfs,RDD-1 在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的 RDD-1 转换到 RDD-m 这一过程中,就不会计算其之前的 RDD-0 了。

6、checkpoint
(1)虽然 RDD 的血缘关系天然地可以实现容错,当 RDD 的某个分区数据计算失败或丢失,可以通过血缘关系重建。
(2)但是对于长时间迭代型应用来说,随着迭代的进行,RDDs 之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。
(3)为此,RDD 支持checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint 后的 RDD 不需要知道它的父 RDDs 了,它可以从 checkpoint 处拿到数据。
Spark-Core RDD概述的更多相关文章
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Spark Core知识点复习-1
Day1111 Spark任务调度 Spark几个重要组件 Spark Core RDD的概念和特性 生成RDD的两种类型 RDD算子的两种类型 算子练习 分区 RDD的依赖关系 DAG:有向无环图 ...
- Spark Core (一) 什么是RDD的Transformation和Action以及Dependency(转载)
1. Spark的RDD RDD(Resilient Distributed Datasets),弹性分布式数据集,是对分布式数据集的一种抽象. RDD所具备5个主要特性: 一组分区列表 计算每一个数 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark之RDD
Spark学习之路Spark之RDD 目录 一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数 ...
- Spark RDD :Spark API--Spark RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路 (三)Spark之RDD[转]
RDD的概述 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- sparkRDD:第1节 RDD概述;第2节 创建RDD
RDD的特点: (1)rdd是数据集: (2)rdd是编程模型:因为rdd有很多数据计算方法如map,flatMap,reduceByKey等: (3)rdd相互之间有依赖关系: (4)rdd是可以分 ...
随机推荐
- java Class类使用
1.forName public static Class<?> forName(String className) throws ClassNotFoundException 返回与带有 ...
- bzoj4129 Haruna’s Breakfast 树上带修莫队+分块
题目传送门 https://lydsy.com/JudgeOnline/problem.php?id=4129 题解 考虑没有修改的序列上的版本应该怎么做: 弱化的题目应该是这样的: 给定一个序列,每 ...
- Flask【第5篇】:用Falsk实现的分页
用flask实现的分页 一.flask实现的分页组件 from urllib.parse import urlencode,quote,unquote class Pagination(object) ...
- Django【第25篇】:后端CORS解决跨域问题
解决跨域问题 一.为什么会有跨域问题? 是因为浏览器的同源策略是对ajax请求进行阻拦了,但是不是所有的请求都给做跨域,像是一般的href属性,a标签什么的都不拦截. 二.解决跨域问题的两种方式 JS ...
- 借助tcpdump统计http请求
借助tcpdump统计http请求 这里所说的统计http请求,是指统计QPS(每秒请求数),统计前十条被访问最多的url.一般做这样的统计时,我们经常会使用网站访问日志来统计.当我们来到一个 ...
- php sockets扩展安装
php sockets扩展安装 今天安装cacti发现需要php sockets扩展,而现在的lnmp没有安装,于是想到了phpzie工具安装扩展,安装方法如下: cd php-5.3.8/ext ...
- sql server,mysql 和navicat for mysql的区别
一.定义 sql server 应该指的是sqlserver数据库,包含数据库管理系统等. navicat for sql server只是一个sqlserver的第三方的开发工具,管理工具. 二.开 ...
- 【牛客Wannafly挑战赛23】F 计数
题目链接 题意 给定一张边带权的无向图,求生成树的权值和是 k 的倍数的生成树个数模 p 的值. \(n\leq 100,k\leq 100,p\mod k=1\) Sol 看见整除然后 \(p\mo ...
- js基础复习~Array对象
Array对象 lenght 获取到数组的长度 concat() 方法用于合并两个或多个数组.此方法不会更改两大有数组,而是返回一个新的数组 let arr1 = ["a",&qu ...
- Vue最常用的组件通讯有三种:父->子组件通讯、子->父组件通讯,兄弟组件通讯.(template用的pug模板语法)
Vue组件通讯 Vue最常用的组件通讯有三种:父->子组件通讯.子->父组件通讯,兄弟组件通讯.(template用的pug模板语法) 1.父->子组件通讯 父->子组件通 ...