SingleNode HDFS 搭建过程
背景
1. 纯粹测试
2. 未考虑安全和授权以及数据处理.
3. 单节点最简单的部署, 验证功能连接的可能性
资料获取以及环境变量的设置
- 获取最新的安装文件
https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
- 文件不到600m 大小 下载速度还是可以的.
- 设置环境变量
export PATH=$PATH:/app/server/runtime/java/x86_64-linux/bin/:/hadoop/bin:/hadoop/sbin
export HDFS_DATANODE_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export JAVA_HOME=/app/server/runtime/java/x86_64-linux/
- 注意我这边设置的表简单 直接放到了
/etc/profile.d/app.sh然后source一下就可以了 - 可以看到我这边使用了比较简单的 root用户运行.
部署单节点的hdfs
- 修改设置变量文件
前提条件, 我讲hadoop 整个目录放到了 /hadoop 里面, 跟环境变量呼应.
修改配置文件
cd /hadoop/etc/hadoop/
hdfs-site.xml
内容设置为
# 注意肯恩需要先设置一下file 后面的路径.
# 注意我这边是简单的singleNode 所以replication 设置的是 1.
<configuration>
<!--指定hdfs保存数据的副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--指定hdfs中namenode的存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/tmp/dfs/name</value>
</property>
<!--指定hdfs中datanode的存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改另一个配置文件
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://someip:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/hadoop/tmp</value>
</property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</configuration>
# 注意需要记住ip地址.
- 进行初始化
直接使用官网介绍的命令就可以
Format the filesystem:
$ bin/hdfs namenode -format
Start NameNode daemon and DataNode daemon:
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
Browse the web interface for the NameNode; by default it is available at:
NameNode - http://localhost:9870/
Make the HDFS directories required to execute MapReduce jobs:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
Copy the input files into the distributed filesystem:
$ bin/hdfs dfs -mkdir input
$ bin/hdfs dfs -put etc/hadoop/*.xml input
Run some of the examples provided:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep input output 'dfs[a-z.]+'
Examine the output files: Copy the output files from the distributed filesystem to the local filesystem and examine them:
$ bin/hdfs dfs -get output output
$ cat output/*
or
View the output files on the distributed filesystem:
$ bin/hdfs dfs -cat output/*
When you’re done, stop the daemons with:
$ sbin/stop-dfs.sh
检查一下部署结果
- 打开网页 http://nodeip:9870
- 展示Node节点的情况的结果
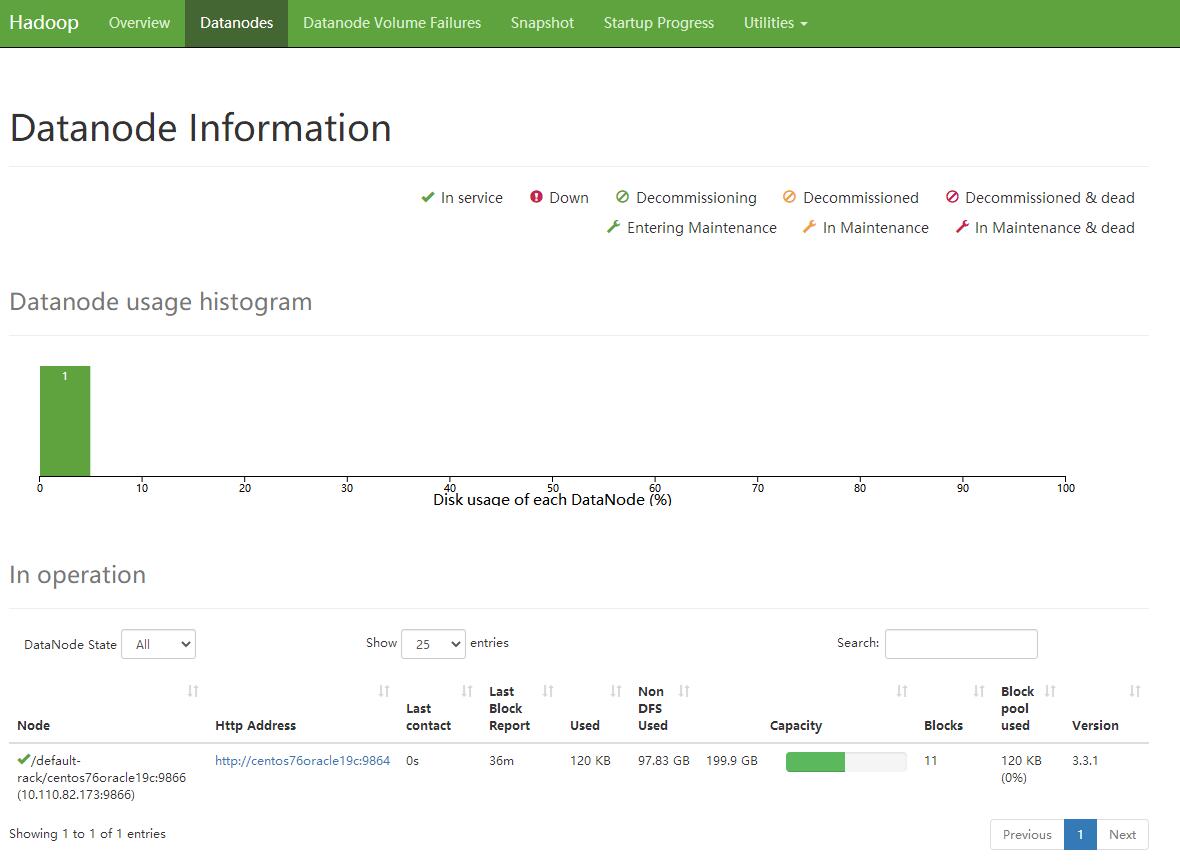
- 展示文件系统, 这里我没考虑权限 好像 控制台权限是没法进行upload和delete的 改天学习下 , 另外不清楚 8020端口的安全设置
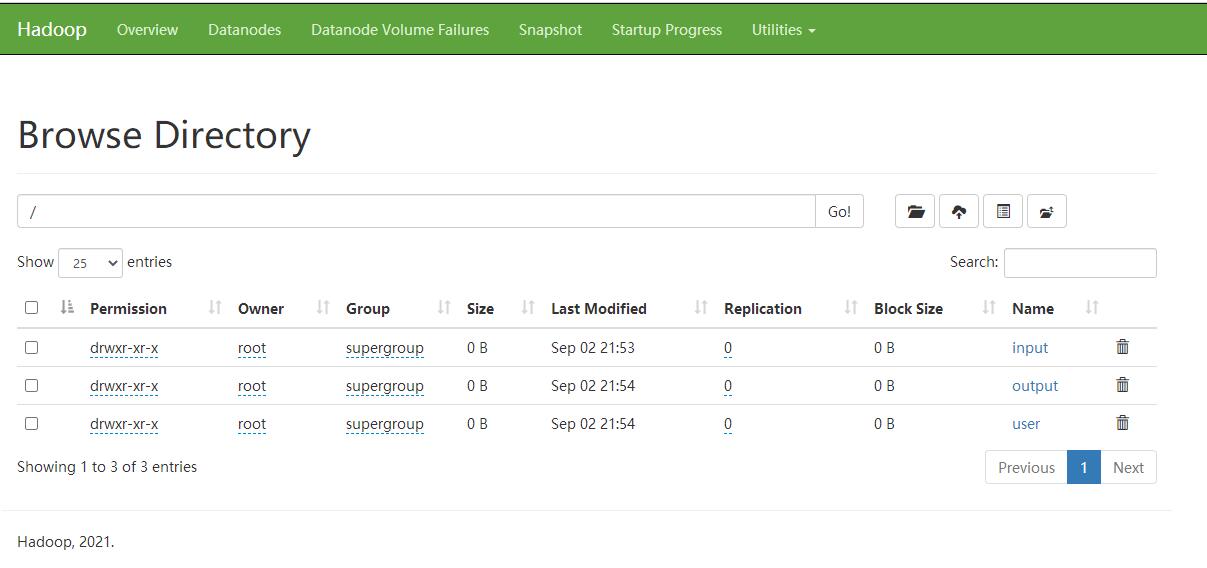
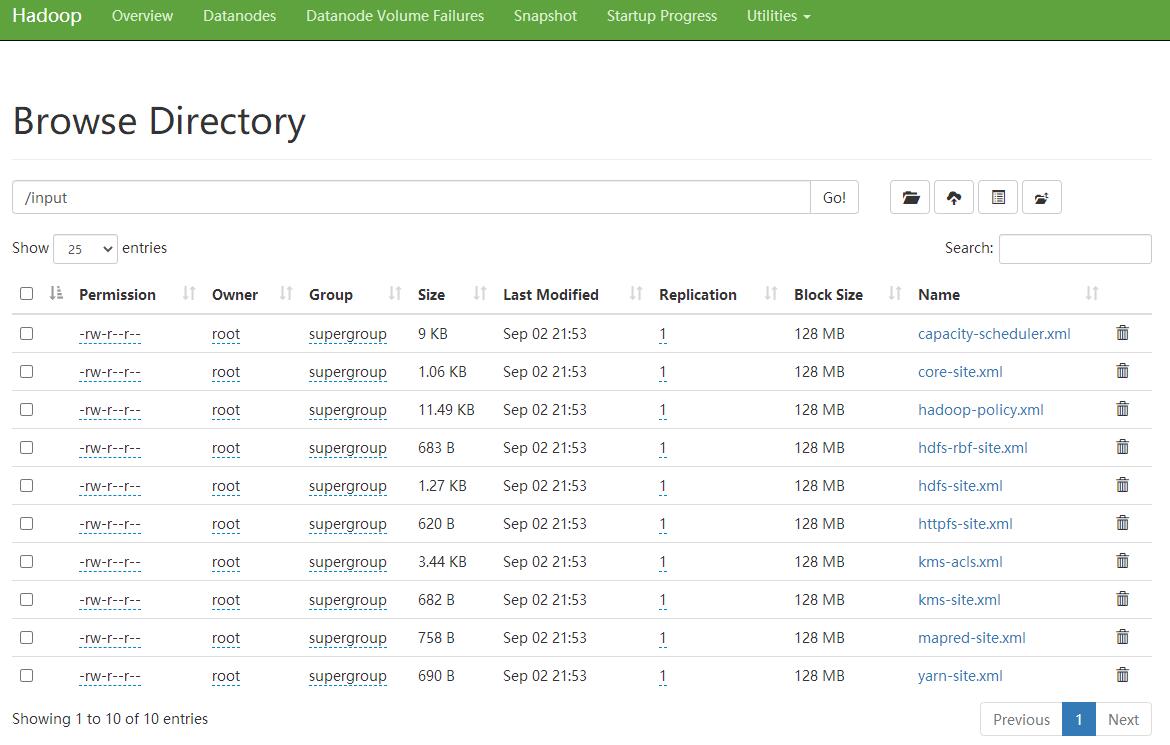
- 展示具体的文件夹内的内容
SingleNode HDFS 搭建过程的更多相关文章
- 懒人记录 Hadoop2.7.1 集群搭建过程
懒人记录 Hadoop2.7.1 集群搭建过程 2016-07-02 13:15:45 总结 除了配置hosts ,和免密码互连之外,先在一台机器上装好所有东西 配置好之后,拷贝虚拟机,配置hosts ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
- Hadoop集群(二) HDFS搭建
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的.所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始. 安装Hadoop集群,首先需要有Zookeeper ...
- 【安装】Hadoop2.8.0搭建过程整理版
Hadoop搭建过程 前期环境搭建主要分为软件的安装与配置文件的配置,集成的东西越多,配置项也就越复杂. Hadoop集成了一个动物园,所以配置项也比较多,且每个版本之间会有少许差异. 安装的方式有很 ...
- 本地+分布式Hadoop完整搭建过程
1 概述 Hadoop在大数据技术体系中极为重要,被誉为是改变世界的7个Java项目之一(剩下6个是Junit.Eclipse.Spring.Solr.HudsonAndJenkins.Android ...
- Maven多模块,Dubbo分布式服务框架,SpringMVC,前后端分离项目,基础搭建,搭建过程出现的问题
现互联网公司后端架构常用到Spring+SpringMVC+MyBatis,通过Maven来构建.通过学习,我已经掌握了基本的搭建过程,写下基础文章为而后的深入学习奠定基础. 首先说一下这篇文章的主要 ...
- Access应用笔记<四>-一个完整的自动化报表搭建过程
距离之前的三篇日志已经很久啦,今天终于完成了一个比较完整的自动化报表搭建过程 基于公司数据保密原则,样板就不放到网上来了,简单说一下背景: 这次access实现的功能包括: 1)为部门整体搭建了一个员 ...
- iOS---XMPP环境搭建过程
什么是即时通信? 即时通信是目前Internet上最为流行的通讯方式, 各种各样的即时通讯软件也层出不穷, 服务提供商也提供了越来越枫木的通讯服务功能. 即时通讯有多重实现方式, XMPP就是其中一种 ...
- 最简单的SVN环境搭建过程
本文简单描述最简单的SVN环境搭建过程 搭建环境:windows (个人验证了windows2003,windows xp) 使用软件:Setup-Subversion-1.6.17 //Serve ...
- cocos2d-x3.9 NDK android 环境搭建过程中遇到的错误
编译环境:Mac OS, NDK r9d 错误:arm-linux-androideabi-gcc: error trying to exec '/media/Project/adt-bundle-l ...
随机推荐
- 手把手带你通过API创建一个loT边缘应用
摘要:使用API Arts&API Explorer调用IoT边缘服务接口创建应用,了解边缘计算在物联网行业的应用. 本文分享自华为云社区<使用API Arts&API Expl ...
- GIS常用npm包:GeoJSON文件合并与元素过滤\属性过滤\图形合并
GeoJSON文件合并 普通的geoJSON文件合并,只需geojson-merge插件就够了,https://www.npmjs.com/package/@mapbox/geojson-merge ...
- MySQL java new dat() 后插入数据库的时间不一致
别用时间字段,做为关联字段,代码里的时间和插到数据库中有误差 MySQL java new dat() 后插入数据库的时间不一致,代码里new 的时间插到数据库中不一致
- Hugging News #0918: Hub 加入分类整理功能、科普文本生成中的流式传输
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- drf-Response drf-request.data 序列化类的使用 反序列化新增、修改、删除数据
目录 APIView基本使用 使用原生Django写接口(View + JsonResponse) 使用drf写接口(APIView + drf Response) drf 两种导入View的方式 d ...
- SAP搜索帮助的限制值范围样式
样式一: 点击下拉框,输入筛选数据,筛选搜索帮助列表 样式二: 点击漏斗,输入筛选数据,筛选搜索帮助列表 参数设置: 不同的样式,通过账号的参数设置决定 第一种样式:没有配置F4METHOD,或者配置 ...
- L2-007 家庭房产 (25 分) (并查集)
给定每个人的家庭成员和其自己名下的房产,请你统计出每个家庭的人口数.人均房产面积及房产套数. 输入格式: 输入第一行给出一个正整数N(≤1000),随后N行,每行按下列格式给出一个人的房产: 编号 父 ...
- java获取年月日、时间与区间、Sql获取年月日区间
SQL 获取时.日.周.月日期 因工作上常用到统计分析,需要用到具体的时间,故写于此 24小时: SELECT 0 AS hour UNION ALL SELECT 1 AS hour UNION A ...
- 6 Englishi 词根
9 pend/pends = hang 悬挂 depend de 向下 independent in 前缀 表否定: ent adj后缀 suspend sus=sub(便于发音) p ...
- echarts自定义legend样式
https://blog.csdn.net/changyana/article/details/126281275