教你3种Kafka的指定副本作为Leader的实现方式
摘要:因为在我们实际的运维过程中,需要指定某个副本为ISR,但是Kafka中的Leader选举策略并不支持这个功能,所以需要我们自己来实现它。
本文分享自华为云社区《Kafka的指定副本作为Leader的三种实现方式》,作者:石臻臻的杂货铺。
前几天有个群友问到: kafka如何修改优先副本? 他们有个需求是, 想指定某个分区中的其中一个副本为Leader。
需求分析
对于这么一个问题,在我们生产环境还是挺常见的,经常有需要修改某个Topic中某分区的Leader
比如 topic1-0这个分区有3个副本[0,1,2], 按照「优先副本」的规则那么 0 号副本肯定就是Leader了 我们都知道分区中的只有Leader副本才会提供读写副本其他副本作为备份 假如在某些情况下,「0」 号副本性能资源不够,或者网络不太好,或者IO压力比较大那么肯定对Topic的整体读写性能有很大影响, 这个时候切换一台压力较小副本作为Leader就显得很重要;优先副本: 分区中的AR(所有副本)信息, 优先选择排在第一位的副本作为Leader Leader机制: 分区中只有一个Leader来承担读写,其他副本只是作为备份
那么如何实现这样一个需求呢?
解决方案
知道了原理之后,我们就能想到对应的解决方案了 只要将 分区的 AR 中的第一个位置,替换成你指定副本就行了;AR = { 0,1,2 } ==> AR = {2,1,0}
一般能够达到这个目的有两种方案,下面我们来分析一下
方案一: 分区副本重分配 (低成本方案)
一般分区副本重分配主要有三个流程
- 生成推荐的迁移Json文件
- 执行迁移Json文件
- 验证迁移流程是否完成
这里我们主要看第2步骤, 来看看迁移文件一般是什么样子的
{
"version": 1,
"partitions": [{
"topic": "topic1",
"partition": 0,
"replicas": [0,1,2]
}]
}
这个迁移Json意思是, 把topic1的「0」号分区的副本分配成[0,1,2] ,也就是说 topic1-0号分区最终有3个副本分别在 {brokerId-0,brokerId-1,brokerId-2} ;
又根据Leader的选举策略得知,不管是什么策略的选择,都是按照AR的顺序来选的
修改AR顺序
AR: 副本的分配顺序
那么我们想要实现我们的需求
是不是把这个Json文件 中的 “replicas”: [0,1,2] 改一下就行了
比如改成 “replicas”: [2,1,0] ,
改完Json后执行,执行execute, 正式开始重分配流程!
迁移完成之后, 就会发现,Leader已经变成上面的第一个位置的副本「2」 了
执行Leader选举
修改完AR顺序就结束了吗?
可以说是结束了,也可以说没有结束。
上面只是修改了AR的顺序, 但是没有执行Leader选举呀,这个时候Leader还是原来的,所以我们需要主动触发一下Leader选举
## 石臻臻的杂货铺
## 微信: szzdzhp001 sh bin/kafka-leader-election.sh --bootstrap-server xxxx:9090 --topic Topic1 --election-type PREFERRED --partition 0
这样就会立马切换成我们想要的Leader了。
也可以不主动触发,等Controller自动均衡。
如果你觉得主动触发这个很麻烦,那么没有关系,那就不执行,如果你开启了自动均衡策略的话,默认是开启的。
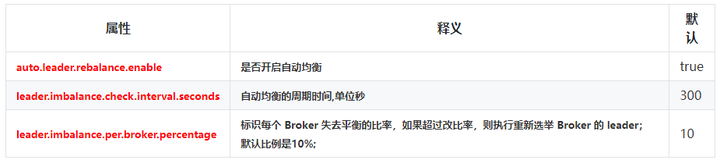
延伸: 自动均机制
当一个broker停止或崩溃时,这个broker中所有分区的leader将转移给其他副本。这意味着在默认情况下,当这个broker重新启动之后,它的所有分区都将仅作为follower,不再用于客户端的读写操作。
为了避免这种不平衡,Kafka有一个优先副本的概念。如果一个分区的副本列表是1,5,9,节点1将优先作为其他两个副本5和9的leader。
Controller会有一个定时任务,定期执行优先副本选举,这样就不会导致负载不均衡和资源浪费,这就是leader的自动均衡机制
优缺点
优点: 实现了需求, 不需要改源码,也没有额外的开发工作。
缺点: 操作比较复杂容易出错,需要先获取原先的分区分配数据,然后手动修改Json文件,这里比较容易出错,影响会比较大,当然这些都可以通过校验接口来做好限制, 最重要的一点是 副本重分配当前只能有一个任务 !
假如你当前有一个「副本重分配」的任务在,那么这里就不能够执行了。
方案二: 手动修改AR顺序(高成本方案)
- 从zk中获取/brokers/topics/{topic名称}节点数据。
- 手动调整一下里面的顺序
- 将调整后的数据,重新覆盖掉之前的节点。
- 删除zk中的/Controller节点,让它触发重新加载,并且同时触发Leader选举。
例如:
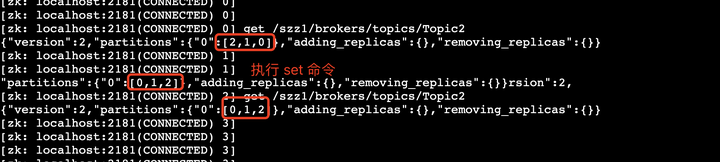
修改的时候请先用get获取数据,在那个基础上改,因为不同版本,里面的数据结构是不一样的,我们只需要改分区AR顺序就行了 “partitions”:{“0”:[0,1,2]}
## get zk 节点数据。 get /szz1/brokers/topics/Topic2 ## zk中的修改命令
set /szz1/brokers/topics/Topic2 {"version":2,"partitions":{"0":[0,1,2]},"adding_replicas":{},"removing_replicas":{}}
为什么要删除Controller的zk节点?
之所以删除Controller节点,是因为我们手动修改了zk节点数据之后,因为没有副本的新增,是不会触发Controller去更新AR内存的,就算你主动触发Leader选举,AR还是以前的,并不会达到想要的效果。
删除zk中的/Controller节点,会触发Controller重新选举,重新选举会重新加载所有元数据,所以我们刚刚加载的数据就会生效, 同时Controller重新加载也会触发Leader选举。
简单代码
当然上面功能,手动改起来麻烦,那么饿肯定是要集成到LogiKM 3.0中的咯;
优缺点
优点: 实现了目标需求, 简单, 操作方便
缺点: 频繁的Controller重选举对生产环境来说会有一些影响;
方案三:修改源码(高级方案推荐)
我们方案二中的问题就是需要删除/Controller节点发送重新选举,我们能不能不重新选举Controller也能生效呢?
如何让修改后的AR立即生效 ?
Controller会监听每一个topic的节点/brokers/topics/{topic名称}
KafkaController#processPartitionModifications
/**
* 石臻臻的杂货铺
* 微信:szzdzhp001
* 省略部分代码
**/
private def processPartitionModifications(topic: String): Unit = {
def restorePartitionReplicaAssignment(
topic: String,
newPartitionReplicaAssignment: Map[TopicPartition, ReplicaAssignment]
): Unit = { val partitionReplicaAssignment = zkClient.getFullReplicaAssignmentForTopics(immutable.Set(topic))
val partitionsToBeAdded = partitionReplicaAssignment.filter { case (topicPartition, _) =>
controllerContext.partitionReplicaAssignment(topicPartition).isEmpty
} if (topicDeletionManager.isTopicQueuedUpForDeletion(topic)) { } else if (partitionsToBeAdded.nonEmpty) {
info(s"New partitions to be added $partitionsToBeAdded")
partitionsToBeAdded.foreach { case (topicPartition, assignedReplicas) =>
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
}
onNewPartitionCreation(partitionsToBeAdded.keySet)
}
}
}
这段代码省略了很多,我想让你看到的是:
只有新增了副本,才会执行更新Controller的内存操作。
那么我们在这里面新增一段逻辑
新增逻辑:如果只是变更了AR的顺序,那么我们也更新一下内存。
来我们改一下源码
// 1. 找到 AR 顺序有变更的 所有TopicPartition
val partitionsOrderChange = partitionReplicaAssignment.filter { case (topicPartition, _) =>
//这里自己写下过滤逻辑 把只是顺序变更的分区找出
true
} if (topicDeletionManager.isTopicQueuedUpForDeletion(topic)) {
if (partitionsToBeAdded.nonEmpty) { } else { }
} else if (partitionsToBeAdded.nonEmpty) {
info(s"New partitions to be added $partitionsToBeAdded")
partitionsToBeAdded.foreach { case (topicPartition, assignedReplicas) =>
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
}
onNewPartitionCreation(partitionsToBeAdded.keySet)
}else if (partitionsOrderChange.nonEmpty) {
// ② .在这里加个逻辑
info(s"OrderChange partitions to be updatecache $partitionsToBeAdded")
partitionsOrderChange.foreach { case (topicPartition, assignedReplicas) =>
controllerContext.updatePartitionFullReplicaAssignment(topicPartition, assignedReplicas)
}
}
改成这样之后,上面的流程就变成了
- 从zk中获取/brokers/topics/{topic名称}节点数据。
- 手动调整一下里面的顺序
- 将调整后的数据,重新覆盖掉之前的节点。
- 手动执行一次,优先副本选举。
思考
方案三改了之后会对其他的流程有影响吗?
上面更改的方法,一般是在分区副本重分配或者新增分区的时候会触发。
上面新增的逻辑并不会对现有流程有影响,因为假设都是上面的场景的情况下,他们都是会主动更新内存的。
在我看来,这里的改动,完全可以向kafka社区提一个Pr. 来“修复”这个问题。
因为提了这个PR,对我们有收益,没有额外的开销!
教你3种Kafka的指定副本作为Leader的实现方式的更多相关文章
- 教你三种jQuery框架实现元素显示及隐藏动画方式
摘要:在jQuery框架中对元素对象进行显示和隐藏有三种方式,分别是"默认方式显示和隐藏"."滑动方式显示和隐藏"."淡入淡出显示和隐藏". ...
- kafka 分区和副本以及kafaka 执行流程,以及消息的高可用
1.Kafka概览 Apache下的项目Kafka(卡夫卡)是一个分布式流处理平台,它的流行是因为卡夫卡系统的设计和操作简单,能充分利用磁盘的顺序读写特性.kafka每秒钟能有百万条消息的吞吐量,因此 ...
- 详细解析kafka之kafka分区和副本
本篇主要介绍kafka的分区和副本,因为这两者是有些关联的,所以就放在一起来讲了,后面顺便会给出一些对应的配置以及具体的实现代码,以供参考~ 1.kafka分区机制 分区机制是kafka实现高吞吐的秘 ...
- kafka分区及副本在broker的分配
kafka分区及副本在broker的分配 部分内容參考自:http://blog.csdn.net/lizhitao/article/details/41778193 以下以一个Kafka集群中4个B ...
- Kafka 0.8 副本同步机制理解
Kafka的普及在很大程度上归功于它的设计和操作简单,如何自动调优Kafka副本的工作,挑战之一:如何避免follower进入和退出同步副本列表(即ISR).如果某些topic的部分partition ...
- 4种Kafka网络中断和网络分区场景分析
摘要:本文主要带来4种Kafka网络中断和网络分区场景分析. 本文分享自华为云社区<Kafka网络中断和网络分区场景分析>,作者: 中间件小哥. 以Kafka 2.7.1版本为例,依赖zk ...
- 5种kafka消费端性能优化方法
摘要:带你了解基于FusionInsight HD&MRS的5种kafka消费端性能优化方法. 本文分享自华为云社区<FusionInsight HD&MRSkafka消费端性能 ...
- CAD转DXF怎么转换?教你三种转换方法
CAD图纸在我们日常生活中都是可见到的,因为CAD图纸文件的格式是多样的,在工作中就需要经常将CAD的格式进行转换.那CAD转DXF怎么转换呢?这个问题很多的小伙伴们都遇到过,下面小编就来教大家三种转 ...
- Kafka水位(high watermark)与leader epoch的讨论
~~~这是一篇有点长的文章,希望不会令你昏昏欲睡~~~ 本文主要讨论0.11版本之前Kafka的副本备份机制的设计问题以及0.11是如何解决的.简单来说,0.11之前副本备份机制主要依赖水位(或水印) ...
- Kafka设计解析(二十一)Kafka水位(high watermark)与leader epoch的讨论
转载自 huxihx,原文链接 Kafka水位(high watermark)与leader epoch的讨论 本文主要讨论0.11版本之前Kafka的副本备份机制的设计问题以及0.11是如何解决的. ...
随机推荐
- Unity - UIWidgets 7. Redux接入(二) 把Redux划分为不同数据模块
参考QF.UIWidgets 参考Unity官方示例 - ConnectAppCN 前面说过,当时没想明白一个问题,在reducer中每次返回一个new State(), 会造成极大浪费,没想到用什么 ...
- nodejs修改npm包安装位置
适用于非个人电脑.便携使用 npm config set cache D:\nodejs\node_cache npm config set prefix D:\nodejs npm config s ...
- JavaScript(ES6):变量的解构赋值
解构赋值定义: 允许按照一定模式从数组或对象中提取值,然后对变量进行赋值. 数组的解构赋值 注:数组的元素要一次排序的,变量的值由他的位置决定. 基本用法 // ES6 解构赋值 let [a, b, ...
- JAVA多线程(1)——线程
1.定义:线程是一个程序里面不同的执行路径 例子1:只有一个执行路径 (一个分支,即主线程)
- 【日常收支账本】【Day05】编辑账本界面增加删除、更新记录功能——提高代码复用性
一.项目地址 https://github.com/LinFeng-BingYi/DailyAccountBook 二.新增 1. 增加删除记录功能 1.1 功能详述 点击删除按钮后,获取对应行的数据 ...
- IoC容器趣谈
今天我们来谈谈Spring的内核之一--IoC容器 大家可能会有这样的疑问: "这玩意为啥要叫容器呢?好奇怪" "容器不是装东西的吗?难道IoC容器也是用来装什么东西的? ...
- Android 实现APP可切换多语言
原文: Android 实现APP可切换多语言 - Stars-One的杂货小窝 如果是单独给app加上国际化,其实很容易,创建对应的国家资源文件夹即可,如values-en,values-pt,ap ...
- 解决swagger2 --> Illegal DefaultValue null for parameter type integer 保存问题
在pmo.xml中加入两个依赖 <!--增加两个配置--> <dependency> <groupId>io.swagger</groupId> < ...
- Cisco 交换机利用CDP数据自动绘制网络拓扑图[drawio]-实践
进行网络运维,必须对网络拓扑情况进行详细的掌握,但是网络改动后,更新网络拓扑比较繁琐,维护人员容易懈怠,久而久之,通过人工绘制的网络拓扑很容易与现有网络出现偏差. 现在,可以通过python 丰富的库 ...
- 复习:Java基础-泛型方法
泛型 大家都很熟悉了 泛型方法呢 可能很多小伙伴都有混淆,今天来稍微复习一下 泛型方法(普通方法) public class Test<T> { public T f(T c) { //注 ...