微服务下,使用 ELK 进行日志采集以及统一处理
摘要:微服务各个组件的相关实践会涉及到工具,本文将会介绍微服务日常开发的一些利器,这些工具帮助我们构建更加健壮的微服务系统,并帮助排查解决微服务系统中的问题与性能瓶颈等。
微服务各个组件的相关实践会涉及到工具,本文将会介绍微服务日常开发的一些利器,这些工具帮助我们构建更加健壮的微服务系统,并帮助排查解决微服务系统中的问题与性能瓶颈等。

我们将重点介绍微服务架构中的日志收集方案 ELK(ELK 是 Elasticsearch、Logstash、Kibana 的简称),准确的说是 ELKB,即 ELK + Filebeat,其中 Filebeat 是用于转发和集中日志数据的轻量级传送工具。
为什么需要分布式日志系统
在以前的项目中,如果想要在生产环境需要通过日志定位业务服务的 bug 或者性能问题,则需要运维人员使用命令挨个服务实例去查询日志文件,导致的结果是排查问题的效率非常低。
微服务架构下,服务多实例部署在不同的物理机上,各个微服务的日志被分散储存不同的物理机。集群足够大的话,使用上述传统的方式查阅日志变得非常不合适。因此需要集中化管理分布式系统中的日志,其中有开源的组件如 syslog,用于将所有服务器上的日志收集汇总。
然而集中化日志文件之后,我们面临的是对这些日志文件进行统计和检索,哪些服务有报警和异常,这些需要有详细的统计。所以在之前出现线上故障时,经常会看到开发和运维人员下载了服务的日志,基于 Linux 下的一些命令,如 grep、awk 和 wc 等,进行检索和统计。这样的方式效率低,工作量大,且对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
ELKB 分布式日志系统
ELKB 是一个完整的分布式日志收集系统,很好地解决了上述提到的日志收集难,检索和分析难的问题。ELKB 分别是指 Elasticsearch、Logstash、Kibana 和 Filebeat。elastic 提供的一整套组件可以看作为 MVC 模型,logstash 对应逻辑控制 controller 层,Elasticsearch 是一个数据模型 model 层,而 Kibana 则是视图 view 层。logstash 和 Elasticsearch 基于 Java 编写实现,Kibana 则使用的是 node.js 框架。

下面依次介绍这几个组件的功能,以及在日志采集系统中的作用。
Elasticsearch 的安装与使用
Elasticsearch 是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放 REST 和 JAVA API 等结构提供高效搜索功能,可扩展的分布式系统。它构建于 Apache Lucene 搜索引擎库之上。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户,能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch 是一个实时的分布式搜索分析引擎,它被用作全文检索、结构化搜索、分析以及这三个功能的组合,它是面向文档 的,意味着它存储整个对象或 文档。Elasticsearch 不仅存储文档,而且 索引每个文档的内容使之可以被检索。在 Elasticsearch 中,你 对文档进行索引、检索、排序和过滤--而不是对行列数据。
为了方便,我们直接使用使用 docker 安装 Elasticsearch:
$ docker run -d --name elasticsearch docker.elastic.co/elasticsearch/elasticsearch:5.4.0
需要注意的是,Elasticsearch 启动之后需要进行简单的设置,xpack.security.enabled 默认是开启的,为了方便,取消登录认证。我们登入到容器内部,执行如下的命令:
# 进入启动好的容器
$ docker exec -it elasticsearch bash # 编辑配置文件
$ vim config/elasticsearch.yml
cluster.name: "docker-cluster"
network.host: 0.0.0.0
http.cors.enabled: true http.cors.allow-origin: "*"
xpack.security.enabled: false # minimum_master_nodes need to be explicitly set when bound on a public IP
# set to 1 to allow single node clusters
# Details: https://github.com/elastic/elasticsearch/pull/17288
discovery.zen.minimum_master_nodes: 1
修改好配置文件之后,退出容器,重启容器即可。我们为了后面使用时能够保留配置,需要从该容器创建一个新的镜像。首先获取到该容器对应的 ContainerId。然后基于该容器提交成一个新的镜像。
$ docker commit -a "add config" -m "dev" a404c6c174a2 es:latest
sha256:5cb8c995ca819765323e76cccea8f55b423a6fa2eecd9c1048b2787818c1a994
这样我们得到了一个新的镜像 es:latest。我们运行新的镜像:
docker run -d --name es -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" es:latest
通过访问 Elasticsearch 提供的内置端点,我们检查是否安装成功。
[root@VM_1_14_centos ~]# curl 'http://localhost:9200/_nodes/http?pretty'
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "docker-cluster",
"nodes" : {
"8iH5v9C-Q9GA3aSupm4caw" : {
"name" : "8iH5v9C",
"transport_address" : "10.0.1.14:9300",
"host" : "10.0.1.14",
"ip" : "10.0.1.14",
"version" : "5.4.0",
"build_hash" : "780f8c4",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.enabled" : "true"
},
"http" : {
"bound_address" : [
"[::]:9200"
],
"publish_address" : "10.0.1.14:9200",
"max_content_length_in_bytes" : 104857600
}
}
}
}
可以看到,我们成功安装了 Elasticsearch,Elasticsearch 作为日志数据信息的存储源,为我们提供了高效的搜索性能。
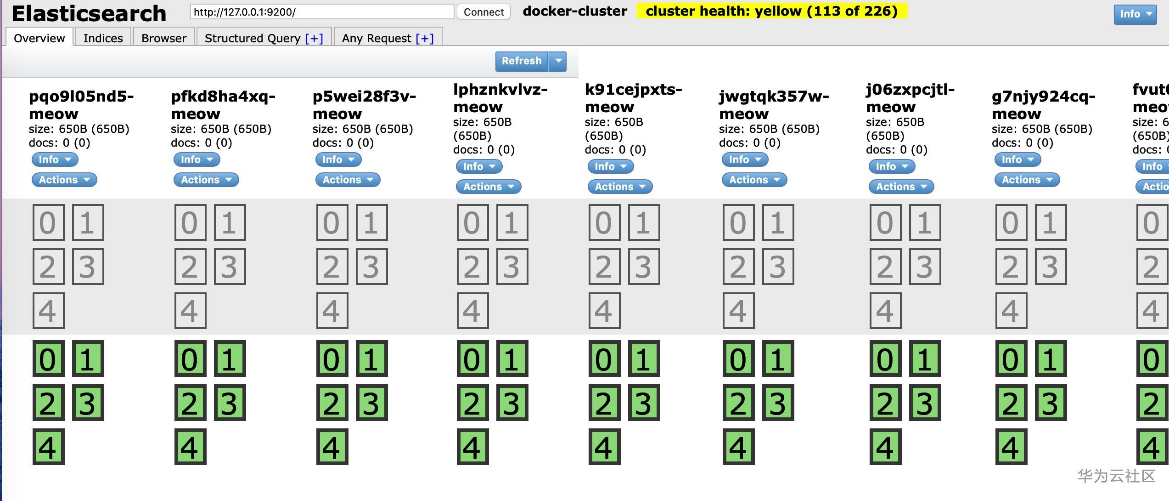
我们另外还安装了 Elasticsearch 的可视化工具:elasticsearch-head。安装方法很简答:
$ docker run -p 9100:9100 mobz/elasticsearch-head:5
elasticsearch-head 用于监控 Elasticsearch 状态的客户端插件,包括数据可视化、执行增删改查操作等。
安装之后的界面如下所示:
logstash 的安装与使用
logstash 是一个数据分析软件,主要目的是分析 log 日志。其使用的原理如下所示:
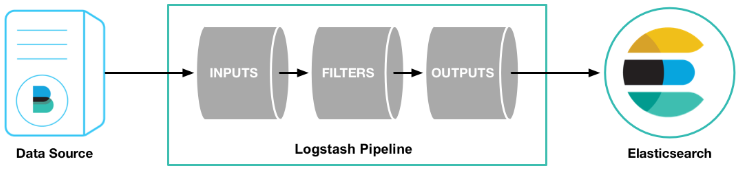
数据源首先将数据传给 logstash,我们这里使用的是 Filebeat 传输日志数据。它主要的组成部分有 Input 数据输入、Filter 数据源过滤和 Output 数据输出三部分。
logstash 将数据进行过滤和格式化(转成 JSON 格式),然后发送到 Elasticsearch 进行存储,并建搜索的索引,Kibana 提供前端的页面视图,可以在页面进行搜索,使得结果变成图表可视化。
下面我们开始安装使用 logstash。首先下载解压 logstash:
# 下载 logstash
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-5.4.3.tar.gz
# 解压 logstash
$ tar -zxvf logstash-5.4.3.tar.gz
下载速度可能比较慢,可以选择国内的镜像源。解压成功之后,我们需要配置 logstash,主要就是我们所提到的输入、输出和过滤。
[root@VM_1_14_centos elk]# cat logstash-5.4.3/client.conf
input {
beats {
port => 5044
codec => "json"
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "logstash-app-error-%{+YYYY.MM.dd}"
}
stdout {codec => rubydebug}
}
输入支持文件、syslog、beats,我们在配置时只能选择其中一种。这里我们配置了 filebeats 方式。
过滤则用于处理一些特定的行为来,处理匹配特定规则的事件流。常见的 filters 有 grok 解析无规则的文字并转化为有结构的格式、 geoip 添加地理信息、drop 丢弃部分事件 和 mutate 修改文档等。如下是一个 filter 使用的示例:
filter {
#定义客户端的 IP 是哪个字段
geoip {
source => "clientIp"
}
}
输出支持 Elasticsearch、file、graphite 和 statsd,默认情况下将过滤扣的数据输出到 Elasticsearch,当我们不需要输出到ES时需要特别声明输出的方式是哪一种,同时支持配置多个输出源。
一个 event 可以在处理过程中经过多重输出,但是一旦所有的 outputs 都执行结束,这个 event 也就完成生命周期。
我们在配置中,将日志信息输出到 Elasticsearch。配置文件搞定之后,我们开始启动 logstash:
$ bin/logstash -f client.conf
Sending Logstash's logs to /elk/logstash-5.4.3/logs which is now configured via log4j2.properties
[2020-10-30T14:12:26,056][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://127.0.0.1:9200/]}}
[2020-10-30T14:12:26,062][INFO ][logstash.outputs.elasticsearch] Running health check to see if an Elasticsearch connection is working {:healthcheck_url=>http://127.0.0.1:9200/, :path=>"/"}
log4j:WARN No appenders could be found for logger (org.apache.http.client.protocol.RequestAuthCache).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
[2020-10-30T14:12:26,209][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>#<URI::HTTP:0x1abac0 URL:http://127.0.0.1:9200/>}[2020-10-30T14:12:26,225][INFO ][logstash.outputs.elasticsearch] Using mapping template from {:path=>nil}
[2020-10-30T14:12:26,288][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>50001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"_all"=>{"enabled"=>true, "norms"=>false}, "dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword"}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date", "include_in_all"=>false}, "@version"=>{"type"=>"keyword", "include_in_all"=>false}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2020-10-30T14:12:26,304][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>[#<URI::Generic:0x2fec3fe6 URL://127.0.0.1:9200>]}
[2020-10-30T14:12:26,312][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500}
[2020-10-30T14:12:27,226][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
[2020-10-30T14:12:27,319][INFO ][logstash.pipeline ] Pipeline main started
[2020-10-30T14:12:27,422][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
根据控制台输出的日志,我们知道 logstash 已经正常启动。
Kibana 的安装与使用
Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据。Kibana 调用 Elasticsearch 的接口返回的数据进行可视化。它利用 Elasticsearch 的 REST 接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
Kibana 的安装比较简单,我们基于 docker 安装即可:
docker run --name kibana -e ELASTICSEARCH_URL=http://127.0.0.1:9200 -p 5601:5601 -d kibana:5.6.9
我们在启动命令中指定了 ELASTICSEARCH 的环境变量,就是本地的 127.0.0.1:9200。
Filebeat 的安装与使用
Filebeat 用于转发和集中日志数据的轻量级传送工具。Filebeat 监视指定的日志文件或位置,收集日志事件,并将它们转发到 Logstash、Kafka、Redis 等,或直接转发到 Elasticsearch 进行索引。

下面我们开始安装配置 Filebeat:
# 下载 filebeat
$ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.4.3-linux-x86_64.tar.gz
$ tar -zxvf filebeat-5.4.3-linux-x86_64.tar.gz
$ mv filebeat-5.4.3-linux-x86_64 filebeat
# 进入目录
$ cd filebeat # 配置 filebeat
$ vi filebeat/client.yml
filebeat.prospectors: - input_type: log
paths:
- /var/log/*.log output.logstash:
hosts: ["localhost:5044"]
在 filebeat 的配置中,input_type 支持从Log、Syslog、Stdin、Redis、UDP、Docker、TCP、NetFlow 输入。上述配置了从 log 中读取日志信息。并且配置了只输入 /var/log/ 目录下的日志文件。output 将 Filebeat 配置为使用 logstash,并且使用 logstash 对 Filebeat 收集的数据执行额外的处理。
配置好之后,我们启动 Filebeat:
$ ./filebeat -e -c client.yml
2020/10/30 06:46:31.764391 beat.go:285: INFO Home path: [/elk/filebeat] Config path: [/elk/filebeat] Data path: [/elk/filebeat/data] Logs path: [/elk/filebeat/logs]
2020/10/30 06:46:31.764426 beat.go:186: INFO Setup Beat: filebeat; Version: 5.4.3
2020/10/30 06:46:31.764522 logstash.go:90: INFO Max Retries set to: 3
2020/10/30 06:46:31.764588 outputs.go:108: INFO Activated logstash as output plugin.
2020/10/30 06:46:31.764586 metrics.go:23: INFO Metrics logging every 30s
2020/10/30 06:46:31.764664 publish.go:295: INFO Publisher name: VM_1_14_centos
2020/10/30 06:46:31.765299 async.go:63: INFO Flush Interval set to: 1s
2020/10/30 06:46:31.765315 async.go:64: INFO Max Bulk Size set to: 2048
2020/10/30 06:46:31.765563 beat.go:221: INFO filebeat start running.
2020/10/30 06:46:31.765592 registrar.go:85: INFO Registry file set to: /elk/filebeat/data/registry
2020/10/30 06:46:31.765630 registrar.go:106: INFO Loading registrar data from /elk/filebeat/data/registry
2020/10/30 06:46:31.766100 registrar.go:123: INFO States Loaded from registrar: 6
2020/10/30 06:46:31.766136 crawler.go:38: INFO Loading Prospectors: 1
2020/10/30 06:46:31.766209 registrar.go:236: INFO Starting Registrar
2020/10/30 06:46:31.766256 sync.go:41: INFO Start sending events to output
2020/10/30 06:46:31.766291 prospector_log.go:65: INFO Prospector with previous states loaded: 0
2020/10/30 06:46:31.766390 prospector.go:124: INFO Starting prospector of type: log; id: 2536729917787673381
2020/10/30 06:46:31.766422 crawler.go:58: INFO Loading and starting Prospectors completed. Enabled prospectors: 1
2020/10/30 06:46:31.766430 spooler.go:63: INFO Starting spooler: spool_size: 2048; idle_timeout: 5s 2020/10/30 06:47:01.764888 metrics.go:34: INFO No non-zero metrics in the last 30s
2020/10/30 06:47:31.764929 metrics.go:34: INFO No non-zero metrics in the last 30s
2020/10/30 06:48:01.765134 metrics.go:34: INFO No non-zero metrics in the last 30s
启动 Filebeat 时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于 Filebeat 所找到的每个日志,Filebeat 都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到 libbeat,libbeat 将聚集事件,并将聚集的数据发送到为 Filebeat 配置的输出。
ELKB 的使用实践
安装好 ELKB 组件之后,我们开始整合这些组件。首先看下 ELKB 收集日志的流程。

Filebeat 监听应用的日志文件,随后将数据发送给 logstash,logstash 则对数据进行过滤和格式化,如 JSON 格式化;之后 logstash 将处理好的日志数据发送给 Elasticsearch,Elasticsearch 存储并建立搜索的索引;Kibana 提供可视化的视图页面。
我们运行所有的组件之后,首先看下 elasticsearch-head 中的索引变化:
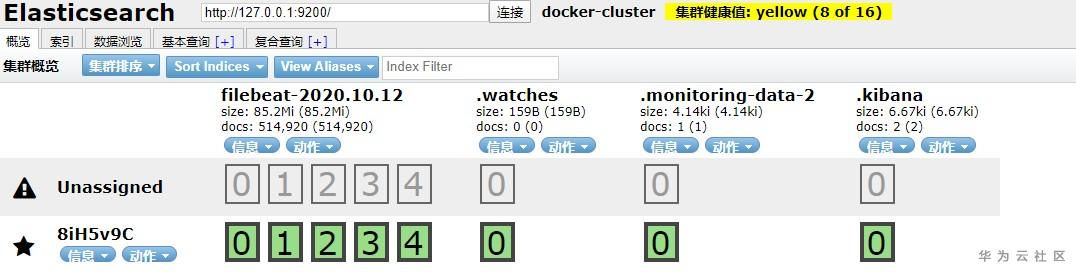
可以看到多了一个 filebeat-2020.10.12 的索引,说明 ELKB 分布式日志收集框架搭建成功。访问 http://localhost:9100,我们来具体看下索引的数据:

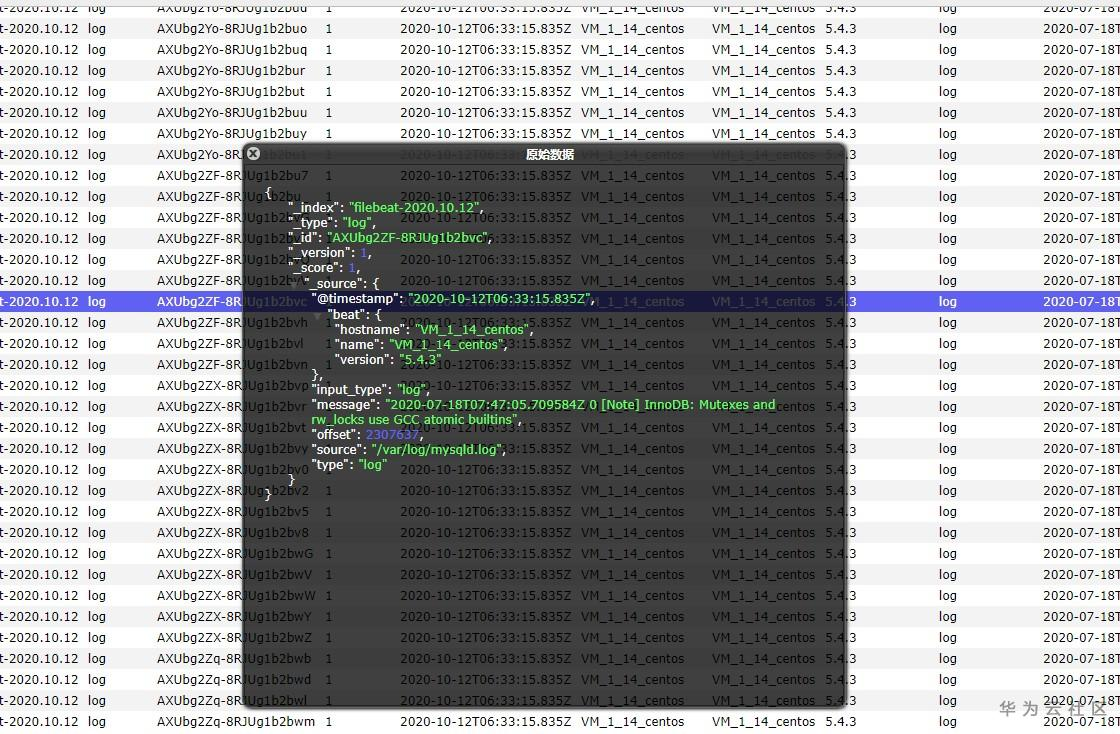
从上面两幅截图可以看到,/var/log/ 目录下的 mysqld.log 文件中产生了新的日志数据,这些数据非常多,我们在生产环境需要根据实际的业务进行过滤,并处理相应的日志格式。
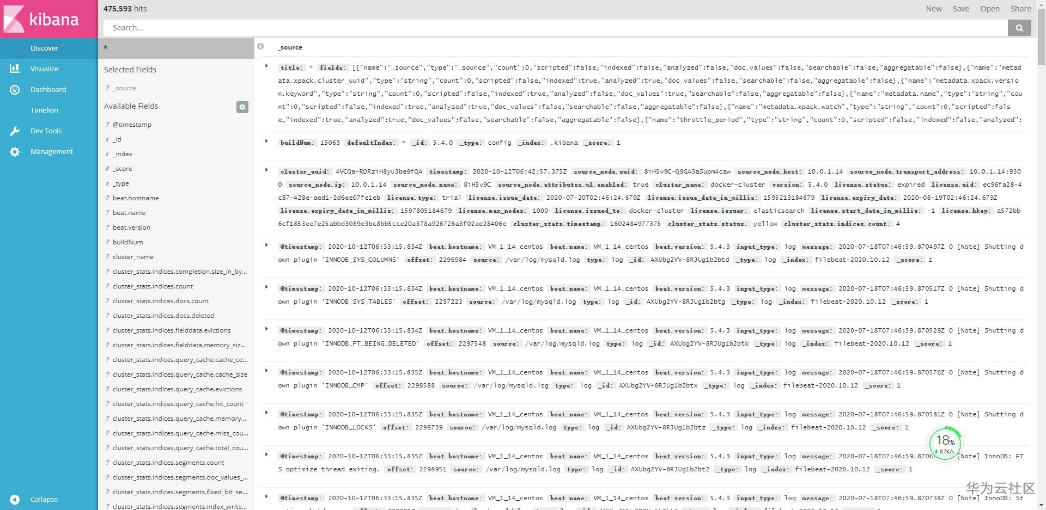
elasticsearch-head 是一个简单的 Elasticsearch 客户端,更加完整的统计和搜索需求,需要借助于 Kibana,Kibana 提升了 Elasticsearch 分析能力,能够更加智能地分析数据,执行数学转换并且根据要求对数据切割分块。
访问 http://localhost:5601,得到了上图中的日志信息。Filebeat 监听到了 mysql 日志,并在 Kibana 上展示。Kibana 能够更好地处理海量数据,并据此创建柱形图、折线图、散点图、直方图、饼图和地图,这里就不一一展示了。
小结
本文主要介绍了分布式日志采集系统 ELKB。日志主要用来记录离散的事件,包含程序执行到某一点或某一阶段的详细信息。ELKB 很好地解决了微服务架构下,服务实例众多且分散,日志难以收集和分析的问题。限于篇幅,本课时只介绍了 ELKB 的安装使用,Go 微服务中一般使用日志框架如 logrus、zap 等,按照一定的格式将日志输出到指定的位置,读者可以自行构建一个微服务进行实践。
本文分享自华为云社区《【华为云专家原创】微服务架构中使用 ELK 进行日志采集以及统一处理》,原文作者:aoho 。
微服务下,使用 ELK 进行日志采集以及统一处理的更多相关文章
- Spring cloud微服务安全实战-7-9自定义日志采集的格式和内容
怎么来控制输出的日志的格式.并且从日志里面提取出来我想要的一些信息. 整个的message是一个大的json格式字符串. 虽然是可以通过关键字搜索到.但是日志看起来并不舒服. 在我们的控制台,日志实际 ...
- AspNetCore微服务下的网关-Kong(一)
Kong是Mashape开源的高性能高可用API网关和API服务管理层.它基于OpenResty,进行API管理,并提供了插件实现API的AOP.Kong在Mashape 管理了超过15,000 个A ...
- 微服务下的契约测试(CDC)解读
1. 前言 有近两周没有在公众号中发表文章了,看过我之前公众号的读者都知道,公众号中近期在连载<RobotFramework接口自动化系列课程>,原本计划每周更新一篇,最近由于博主在带一个 ...
- 探索解析微服务下的RabbitMQ
概览 本文主要介绍如何使用RabbitMQ消息代理来实现分布式系统之间的通信,从而促进微服务的松耦合. RabbitMQ,也被称为开源消息代理,它支持多种消息协议,并且可以部署在分布式系统上.它轻量级 ...
- 小D课堂-SpringBoot 2.x微信支付在线教育网站项目实战_4-2.微服务下登录检验解决方案 JWT讲解
笔记 2.微服务下登录检验解决方案 JWT讲解 简介:微服务下登录检验解决方案 JWT讲解 json wen token 1.JWT 是一个开放标准,它定义了一种用于简洁,自包含的用于通信双方 ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_2_04微服务下电商项目基础模块设计
笔记 4.微服务下电商项目基础模块设计 简介:微服务下电商项目基础模块设计 分离几个模块,课程围绕这个基础项目进行学习 小而精的方式学习微服务 1.用户服务 ...
- 微服务下,使用ELK做日志收集及分析
一.使用背景 目前项目中,采用的是微服务框架,对于日志,采用的是logback的配置,每个微服务的日志,都是通过File的方式存储在部署的机器上,但是由于日志比较分散,想要检查各个微服务是否有报错信息 ...
- K8S学习笔记之filebeat采集K8S微服务java堆栈多行日志
0x00 背景 K8S内运行Spring Cloud微服务,根据定制容器架构要求log文件不落地,log全部输出到std管道,由基于docker的filebeat去管道采集,然后发往Kafka或者ES ...
- 2018年ElasticSearch6.2.2教程ELK搭建日志采集分析系统(教程详情)
章节一 2018年 ELK课程计划和效果演示1.课程安排和效果演示 简介:课程介绍和主要知识点说明,ES搜索接口演示,部署的ELK项目演示 es: localhost:9200 k ...
- Spring Cloud微服务下的权限架构调研
随着微服务架构的流行,系统架构调整,项目权限系统模块开发提上日程,需要对权限架构进行设计以及技术选型.所以这段时间看了下相关的资料,做了几个对比选择. 一.架构图 初步设想的架构如下,结构很简单:eu ...
随机推荐
- SpringBoot + 自定义注解 + AOP 高级玩法打造通用开关
前言 最近在工作中迁移代码的时候发现了以前自己写的一个通用开关实现,发现挺不错,特地拿出来分享给大家. 为了有良好的演示效果,我特地重新建了一个项目,把核心代码提炼出来加上了更多注释说明,希望xdm喜 ...
- Speex详解(2019年09月25日更新)
Speex详解 整理者:赤勇玄心行天道 QQ号:280604597 微信号:qq280604597 QQ群:511046632 博客:www.cnblogs.com/gaoyaguo 大家有什么不明白 ...
- LGPL协议原文及中文翻译
LGPL协议原文及中文翻译 参考链接 原文: GNU LESSER GENERAL PUBLIC LICENSE Version 3, 29 June 2007 Copyright (C) 2007 ...
- 夯实JAVA基本之一——泛型详解(2):高级进阶(转)
上一篇给大家初步讲解了泛型变量的各种应用环境,这篇将更深入的讲解一下有关类型绑定,通配符方面的知识. 一.类型绑定1.引入我们重新看上篇写的一个泛型:class Point<T> { pr ...
- Session入门实例
session对象(是JSP的9大内置对象之一): (1)session代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开为止,这个过程就是一次会话. (2)session作用 ...
- Java之对象内存分析
相信大家有时候在读代码的时候应该都会有以下情况: 这个对象本定义在上面,乱跑什么?怎么又到下面去了? 欸?我明明改变了这个对象的值,怎么没变呢? 要想搞清楚某一对象在程序中是怎样活蹦乱跳的,首先我们要 ...
- 容器中sh脚本明明存在,为何会报"no such file or directory"的错误?
小伙伴碰到一起奇怪的事故,从gitlab上拉取的docker镜像项目,在本地开发机上进行docker build后,启动容器会报错如下: exec /app/run.sh : no such file ...
- 双指针:盛最多水的容器(4.18leetcode每日一题)
给你 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) .在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0).找出其中的两条线, ...
- LangChain内幕指南
1.概述 在人工智能迅速演进的时代,诸如Open AI的ChatGPT和Google的Bard等大型语言模型(LLMs)正彻底改变我们与技术互动的方式.这些技术巨头和SaaS公司正在竞相利用LLMs的 ...
- idea配置servlet项目找不到servlet jar包爆红【解决办法】
1.看你的implements 后面的Servlet是否大写了 2.大部分原因就是缺少servlet-api jar包或者idea找不到jar包 如果你是爆红的,那么问题就在这里,点击-号,重新添加这 ...