分享某Python下的mpi教程 —— A Python Introduction to Parallel Programming with MPI 1.0.2 documentation
如题:
无意中发现了一个Python下的mpi教程《A Python Introduction to Parallel Programming with MPI 1.0.2 documentation》
地址如下:
https://materials.jeremybejarano.com/MPIwithPython/#
=================================================================
这里给出自己的一些学习笔记:
Point-to-Point Communication
The Trapezoidal Rule
关于这个梯形规则,推荐资料:
https://wenku.baidu.com/view/20a29f97dd88d0d233d46a48.html

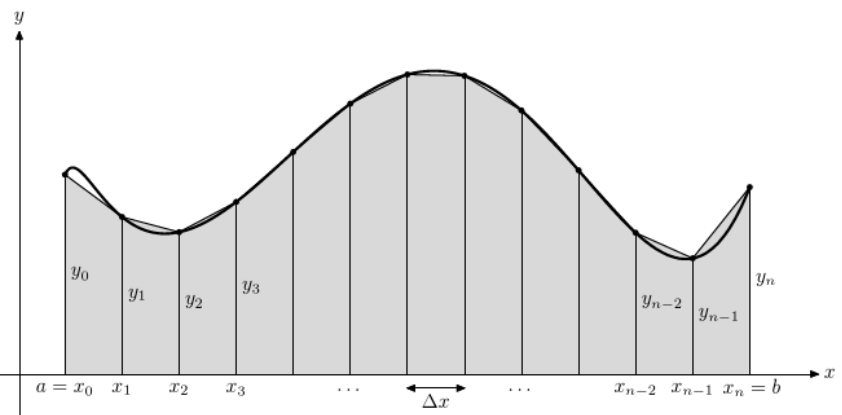

这个梯形规则就是将一个函数的积分形式用一个近似的采样计算的方法来进行求解。
也就有了原文中的公式:
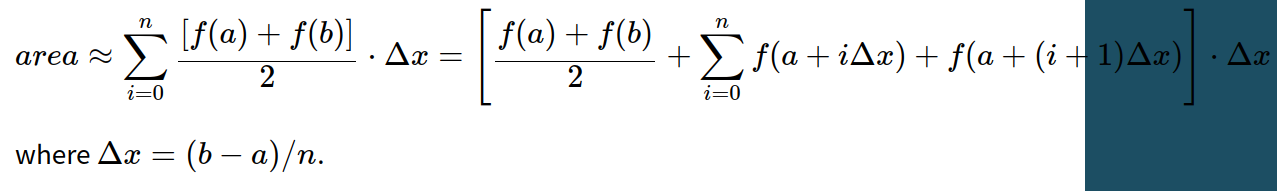
不过原文中的公式不是很好看懂,还是百度文库的那个文档讲解的比较好:
https://wenku.baidu.com/view/20a29f97dd88d0d233d46a48.html
原文中的代码,修改后:
# trapSerial.py
# example to run: python trapSerial.py 0.0 1.0 10000 import numpy
import sys
import time # takes in command-line arguments [a,b,n]
a = float(sys.argv[1])
b = float(sys.argv[2])
n = int(sys.argv[3]) def f(x):
return x * x def integrateRange(a, b, n):
'''Numerically integrate with the trapezoid rule on the interval from
a to b with n trapezoids.
'''
integral = -(f(a) + f(b)) / 2.0 # n+1 endpoints, but n trapazoids
#for x in numpy.linspace(a, b, n + 1):
# integral = integral + f(x)
integral = integral + numpy.sum( f(numpy.linspace(a, b, n + 1)) ) integral = integral * (b - a) / n
return integral begin_time = time.time()
integral = integrateRange(a, b, n)
end_time = time.time() print("With n =", n, "trapezoids, our estimate of the integral\
from", a, "to", b, "is", integral) print("total run time :", end_time - begin_time)
该代码为单机代码,在原始代码基础上改进为向量计算,进一步提高运算的效率。
改进后的mpi代码:
# trapParallel_1.py
# example to run: mpiexec -n 4 python trapParallel_1.py 0.0 1.0 10000
import numpy
import sys
import time
from mpi4py import MPI
from mpi4py.MPI import ANY_SOURCE comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size() # takes in command-line arguments [a,b,n]
a = float(sys.argv[1])
b = float(sys.argv[2])
n = int(sys.argv[3]) # we arbitrarily define a function to integrate
def f(x):
return x * x # this is the serial version of the trapezoidal rule
# parallelization occurs by dividing the range among processes
def integrateRange(a, b, n):
integral = -(f(a) + f(b)) / 2.0
# n+1 endpoints, but n trapazoids
# for x in numpy.linspace(a, b, n + 1):
# integral = integral + f(x)
integral = integral + numpy.sum(f(numpy.linspace(a, b, n + 1)))
integral = integral * (b - a) / n
return integral # local_n is the number of trapezoids each process will calculate
# note that size must divide n
local_n = int(n / size)
# h is the step size. n is the total number of trapezoids
h = (b - a) / (local_n*size) # we calculate the interval that each process handles
# local_a is the starting point and local_b is the endpoint
local_a = a + rank * local_n * h
local_b = local_a + local_n * h # initializing variables. mpi4py requires that we pass numpy objects.
recv_buffer = numpy.zeros(size) if rank == 0:
begin_time = time.time()
# perform local computation. Each process integrates its own interval
integral = integrateRange(local_a, local_b, local_n) # communication
# root node receives results from all processes and sums them
if rank == 0:
recv_buffer[0] = integral
for i in range(1, size):
comm.Recv(recv_buffer[i:i+1], ANY_SOURCE)
total = numpy.sum(recv_buffer)
else:
# all other process send their result
comm.Send(integral, dest=0) # root process prints results
if comm.rank == 0:
end_time = time.time()
print("With n =", n, "trapezoids, our estimate of the integral from" \
, a, "to", b, "is", total)
print("total run time :", end_time - begin_time)
print("total size: ", size)
运行命令:
mpiexec -np 4 python trapSerial_1.py 0 1000000 100000000
上面改进的代码本身也实现了原文中所提到的计算负载均衡的问题,不过上面的改进方法是通过修改总的切分个数,从而实现总的切分个数可以被运行进数所整除。
假设我们总共要切分的数量为1099,但是我们要进行计算的进程数量为100,那么每个进程需要分配多少切分数来进行计算呢,下面给出另一种改进方式,在改变总切分数量的前提下使每个进程所负责计算的切分数均为平均。
改进代码:
# trapParallel_2.py
# example to run: mpiexec -n 4 python trapParallel_1.py 0.0 1.0 10000
import numpy
import sys
import time
from mpi4py import MPI
from mpi4py.MPI import ANY_SOURCE comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size() # takes in command-line arguments [a,b,n]
a = float(sys.argv[1])
b = float(sys.argv[2])
n = int(sys.argv[3]) # we arbitrarily define a function to integrate
def f(x):
return x * x # this is the serial version of the trapezoidal rule
# parallelization occurs by dividing the range among processes
def integrateRange(a, b, n):
integral = -(f(a) + f(b)) / 2.0
# n+1 endpoints, but n trapazoids
# for x in numpy.linspace(a, b, n + 1):
# integral = integral + f(x)
integral = integral + numpy.sum(f(numpy.linspace(a, b, n + 1)))
integral = integral * (b - a) / n
return integral # h is the step size. n is the total number of trapezoids
h = (b - a) / n
# local_n is the number of trapezoids each process will calculate
# note that size must divide n
local_n = numpy.zeros(size, dtype=numpy.int32)
local_n[:] = n // size
if n%size!=0:
local_n[-(n%size):] += 1 # we calculate the interval that each process handles
# local_a is the starting point and local_b is the endpoint
local_a = numpy.sum(local_n[:rank]) * h
local_b = local_a + local_n[rank] * h # initializing variables. mpi4py requires that we pass numpy objects.
recv_buffer = numpy.zeros(size) if rank == 0:
begin_time = time.time()
# perform local computation. Each process integrates its own interval
integral = integrateRange(local_a, local_b, local_n[rank]) # communication
# root node receives results from all processes and sums them
if rank == 0:
recv_buffer[0] = integral
for i in range(1, size):
comm.Recv(recv_buffer[i:i+1], ANY_SOURCE)
total = numpy.sum(recv_buffer)
else:
# all other process send their result
comm.Send(integral, dest=0) # root process prints results
if comm.rank == 0:
end_time = time.time()
print("With n =", n, "trapezoids, our estimate of the integral from" \
, a, "to", b, "is", total)
print("total run time :", end_time - begin_time)
print("total size: ", size)
计算负载均衡的核心代码为:
# h is the step size. n is the total number of trapezoids
h = (b - a) / n
# local_n is the number of trapezoids each process will calculate
# note that size must divide n
local_n = numpy.zeros(size, dtype=numpy.int32)
local_n[:] = n // size
if n%size!=0:
local_n[-(n%size):] += 1 # we calculate the interval that each process handles
# local_a is the starting point and local_b is the endpoint
local_a = numpy.sum(local_n[:rank]) * h
local_b = local_a + local_n[rank] * h
运行命令:
mpiexec --oversubscribe -np 100 python trapSerial_2.py 0 1000000 1099
最后的改进方法更好的实现了计算的负载均衡。
==================================================
上面的改进方法对应集体通信的话又该如何改进呢???
Collective Communication
The Parallel Trapezoidal Rule 2.0
改进方法1对应的 trapParallel_1.py 改进:
# trapParallel_1.py
# example to run: mpiexec -n 4 python26 trapParallel_2.py 0.0 1.0 10000
import numpy
import sys
import time
from mpi4py import MPI
from mpi4py.MPI import ANY_SOURCE comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size() # takes in command-line arguments [a,b,n]
a = float(sys.argv[1])
b = float(sys.argv[2])
n = int(sys.argv[3]) # we arbitrarily define a function to integrate
def f(x):
return x * x # this is the serial version of the trapezoidal rule
# parallelization occurs by dividing the range among processes
def integrateRange(a, b, n):
integral = -(f(a) + f(b)) / 2.0
# n+1 endpoints, but n trapazoids
#for x in numpy.linspace(a, b, n + 1):
# integral = integral + f(x)
integral = integral + numpy.sum(f(numpy.linspace(a, b, n + 1)))
integral = integral * (b - a) / n
return integral # local_n is the number of trapezoids each process will calculate
# note that size must divide n
local_n = int(n / size)
# h is the step size. n is the total number of trapezoids
h = (b - a) / (local_n*size) # we calculate the interval that each process handles
# local_a is the starting point and local_b is the endpoint
local_a = a + rank * local_n * h
local_b = local_a + local_n * h # initializing variables. mpi4py requires that we pass numpy objects.
#integral = numpy.zeros(1)
total = numpy.zeros(1) if rank == 0:
begin_time = time.time()
# perform local computation. Each process integrates its own interval
integral = integrateRange(local_a, local_b, local_n) # communication
# root node receives results with a collective "reduce"
comm.Reduce(integral, total, op=MPI.SUM, root=0) # root process prints results
if comm.rank == 0:
end_time = time.time()
print("With n =", n, "trapezoids, our estimate of the integral from" \
, a, "to", b, "is", total)
print("total run time :", end_time - begin_time)
print("total size: ", size)
运行命令:
mpiexec --oversubscribe -np 100 python trapSerial_1.py 0 1000000 1099
改进方法2 对应的 trapParallel_2.py 改进:
# trapParallel_2.py
# example to run: mpiexec -n 4 python26 trapParallel_2.py 0.0 1.0 10000
import numpy
import sys
import time
from mpi4py import MPI
from mpi4py.MPI import ANY_SOURCE comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size() # takes in command-line arguments [a,b,n]
a = float(sys.argv[1])
b = float(sys.argv[2])
n = int(sys.argv[3]) # we arbitrarily define a function to integrate
def f(x):
return x * x # this is the serial version of the trapezoidal rule
# parallelization occurs by dividing the range among processes
def integrateRange(a, b, n):
integral = -(f(a) + f(b)) / 2.0
# n+1 endpoints, but n trapazoids
#for x in numpy.linspace(a, b, n + 1):
# integral = integral + f(x)
integral = integral + numpy.sum(f(numpy.linspace(a, b, n + 1)))
integral = integral * (b - a) / n
return integral # h is the step size. n is the total number of trapezoids
h = (b - a) / n
# local_n is the number of trapezoids each process will calculate
# note that size must divide n
local_n = numpy.zeros(size, dtype=numpy.int32)
local_n[:] = n // size
if n%size!=0:
local_n[-(n%size):] += 1 # we calculate the interval that each process handles
# local_a is the starting point and local_b is the endpoint
local_a = numpy.sum(local_n[:rank]) * h
local_b = local_a + local_n[rank] * h # initializing variables. mpi4py requires that we pass numpy objects.
#integral = numpy.zeros(1)
total = numpy.zeros(1) if rank == 0:
begin_time = time.time()
# perform local computation. Each process integrates its own interval
integral = integrateRange(local_a, local_b, local_n[rank]) # communication
# root node receives results with a collective "reduce"
comm.Reduce(integral, total, op=MPI.SUM, root=0) # root process prints results
if comm.rank == 0:
end_time = time.time()
print("With n =", n, "trapezoids, our estimate of the integral from" \
, a, "to", b, "is", total)
print("total run time :", end_time - begin_time)
print("total size: ", size)
运行命令:
mpiexec --oversubscribe -np 100 python trapSerial_2.py 0 1000000 1099
====================================================
分享某Python下的mpi教程 —— A Python Introduction to Parallel Programming with MPI 1.0.2 documentation的更多相关文章
- Python学习入门基础教程(learning Python)--5.6 Python读文件操作高级
前文5.2节和5.4节分别就Python下读文件操作做了基础性讲述和提升性介绍,但是仍有些问题,比如在5.4节里涉及到一个多次读文件的问题,实际上我们还没有完全阐述完毕,下面这个图片的问题在哪呢? 问 ...
- Python学习入门基础教程(learning Python)--5.1 Python下文件处理基本过程
Python下的文件读写操作过程和其他高级语言如C语言的操作过程基本一致,都要经历以下几个基本过程. 1. 打开文件 首先是要打开文件,打开文件的主要目的是为了建立程序和文件之间的联系.按程序访问文件 ...
- Python学习入门基础教程(learning Python)--5.2 Python读文件基础
上节简单的说明了一下Pyhon下的文件读写基本流程,从本节开始,我们做几个小例子来具体展示一下Python下的文件操作,本节主要是详细讲述Python的文件读操作. 下面举一个例子,例子的功能是读取当 ...
- Python学习入门基础教程(learning Python)--5 Python文件处理
本节主要讨论Python下的文件操作技术. 首先,要明白为何要学习或者说关系文件操作这件事?其实道理很简单,Python程序运行时,数据是存放在RAM里的,当Python程序运行结束后数据从RAM被清 ...
- Python学习入门基础教程(learning Python)--5.3 Python写文件基础
前边我们学习了一下Python下如何读取一个文件的基本操作,学会了read和readline两个函数,本节我们学习一下Python下写文件的基本操作方法. 这里仍然是举例来说明如何写文件.例子的功能是 ...
- Python学习入门基础教程(learning Python)--3.1Python的if分支语句
本节研究一下if分支语句. if分支语句是Python下逻辑条件控制语句,用于条件执行某些语句的控制操作,当if后的条件conditon满足时,if其下的语句块被执行,但当if的控制条件condito ...
- Python学习入门基础教程(learning Python)--6.3 Python的list切片高级
上节"6.2 Python的list访问索引和切片"主要学习了Python下的List的访问技术:索引和切片的基础知识,这节将就List的索引index和切片Slice知识点做进一 ...
- Python学习入门基础教程(learning Python)--6.4 Python的list与函数
list是python下的一种数据类型,他和其他类型如整形.浮点型.字符串等数据类型一样也可作为函数的型参和实参来使用! 1.list作为参数 list数据类型可以作为函数的参数传递给函数取做相应的处 ...
- Python学习入门基础教程(learning Python)--5.7 Python文件数据记录存储与处理
本节主要讨论Python下如何通过文件操作实现对数据记录集的存储与处理的操作方法. 在Python里和其他高级语言一样可以通过文件读写将一些记录集写入文件或者通过文件读操作从文件里读取一条或多条和数据 ...
- Python学习入门基础教程(learning Python)--2.3.3Python函数型参详解
本节讨论Python下函数型参的预设值问题. Python在设计函数时,可以给型参预设缺省值,当用户调用函数时可以不输入实参.如果用户不想使用缺省预设值则需要给型参一一赋值,可以给某些型参赋值或不按型 ...
随机推荐
- 容器docker技术
我们先看看很久很久以前,服务器是怎么部署应用的! 由于物理机的诸多问题,后来出现了虚拟机. 但是虚拟化也是有局限性的,每一个虚拟机都是一个完整的操作系统,要分配系统资源,虚拟机多道一定程度时,操作系统 ...
- 写的程序总是出 BUG,只好请佛祖前来镇楼啦
前言 自己之前写着玩的,在这做个备份,感觉不错的取走即可. 南无阿弥陀佛 佛祖镇楼,BUG 消失,永不怠机. ///////////////////////////////////////////// ...
- SpringBoot指标监控功能
SpringBoot指标监控功能 随时查看SpringBoot运行状态,将状态以josn格式返回 添加Actuator功能 Spring Boot Actuator可以帮助程序员监控和管理Spring ...
- .NET 个人博客-发送邮件优化🧐
个人博客-发送邮件优化 前言 之前的发送邮件就弄了个方法,比如回复评论会给评论的人发送邮件,留言回复也是,而且2者的代码有很多一样的地方,比较冗余.然后也是抽空优化一下,思路也是比较常用的工厂+策略模 ...
- 3568F-视频开发案例
- NXP i.MX 6ULL工业开发板规格书( ARM Cortex-A7,主频792MHz)
1 评估板简介 创龙科技TLIMX6U-EVM是一款基于NXP i.MX 6ULL的ARM Cortex-A7高性能低功耗处理器设计的评估板,由核心板和评估底板组成.核心板经过专业的PCB Layou ...
- 解决方案 | Adobe Acrobat XI Pro 右键菜单“在Acrobat中合并文件”丢失的最佳修复方法
1.问题 Adobe Acrobat XI Pro右键菜单"转换为Adobe PDF"与"在Acrobat中合并文件" 不见了. 2.解决方案 桌面左下角搜索& ...
- 免费CDN使用整理
免费CDN使用整理 最近在使用web优化的时候,需要用到cdn,遇到了一些问题,比如某些cdn在特定的条件下访问不同,整理一波免费的CDN,任君采撷 名称 国家 链接 测速 特色 UNPKG 国外 h ...
- java进行文件搜索的一个小案例
分享一个小demo,可以查询某个文件目录下的某个文件并启动,来自黑马的IO教程 import java.io.File; import java.io.IOException; public clas ...
- scratch编程作品-《滚动的物理小球》
程序说明: <滚动的物理小球>是一款基于Scratch平台开发的小游戏.在这个游戏中,玩家通过按左右方向键来控制一个小球在屏幕上的左右移动.小球在移动过程中,完全遵循物理引擎的规则,如加速 ...