搭建单机版伪分布式Hadoop+Scala+spark
搭建单机版伪分布式Hadoop+Scala+spark
修改ip
[root@master ~]# nmcli connection add ifname ens32 con-name ens32 autoconnect yes ipv4.method manual ipv4.gateway 192.168.130.2 ipv4.addresses 192.168.130.102/24 ipv4.dns 114.114.114.114
[root@master ~]# nmcli con up ens32
解压压缩包(jdk,hadoop)
[root@master ~]# mkdir /usr/local/soft
[root@master ~]# cd /opt/software/
[root@master software]# tar -xzf jdk-8u152-linux-x64.tar.gz -C /usr/local/soft/
[root@master software]# tar -zxf hadoop-2.7.1.tar.gz -C /usr/local/soft/
[root@master software]# cd /usr/local/soft/
[root@master soft]# ls
hadoop-2.7.1 jdk1.8.0_152
[root@master soft]# mv jdk1.8.0_152/ jdk
[root@master soft]# mv hadoop-2.7.1/ hadoop
[root@master soft]# ls
hadoop jdk
[root@master soft]#
配置环境变量
[root@master soft]# vim /etc/profile
[root@master soft]# tail -n 5 /etc/profile
## jdk
export JAVA_HOME=/usr/local/soft/jdk
export PATH=$PATH:$JAVA_HOME/bin
##
[root@master soft]#
卸载openjdk
[root@master soft]# rpm -e --nodeps $(rpm -qa | grep java)
[root@master soft]# rpm -qa | grep java
[root@master soft]#
使用环境变量
[root@master jdk]# java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
[root@master jdk]#
免密登录
- 域名解析
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.130.102 master
[root@master .ssh]#
- 生成密钥
[root@master .ssh]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:ob7g1XYA0M89LvIhIXGBv/HEap96x7+yzx5kr+IdGCE root@master
The key's randomart image is:
+---[RSA 2048]----+
| .o.. |
| o.o |
| +.+E.. |
| . +o=oo. |
| ..BS...o |
| .*.+..= . |
| ..o=o=o o . |
| . o o=.=o + |
| . oo ooBO. |
+----[SHA256]-----+
[root@master .ssh]# ssh-copy-id root@localhost
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:j0Qc7uQw74uzDmvW6zpHdOJguFFJ7sKVfXyLjFoUoZM.
ECDSA key fingerprint is MD5:2d:9d:c6:f1:88:9d:d2:22:b0:e2:51:ef:d3:fb:6b:4f.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@localhost's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@localhost'"
and check to make sure that only the key(s) you wanted were added
修改配置文件
- core-site.xml
[root@master ~]# cd /usr/local/soft/
[root@master soft]# ls
hadoop jdk
[root@master soft]# cd hadoop/
[root@master hadoop]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@master hadoop]# cd etc/hadoop/
[root@master hadoop]# vim core-site.xml
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop/tmp</value>
</property>
</configuration>
- hadoop.env
[root@master hadoop]# vim hadoop-env.sh
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=//usr/local/soft/jdk
- hdfs-site.xm
[root@master hadoop]# vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
- mapred-site.xml
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
[root@localhost hadoop-3.1.3]# vim yarn-site.xml
#添加以下部分
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- 修改环境变量
[root@master hadoop]# vim /etc/profile
[root@master hadoop]# tail -n 5 /etc/profile
## hadoop
export HADOOP_HOME=/usr/local/soft/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@master hadoop]#
- 生成环境变量
[root@master hadoop]# source /etc/profile
[root@master hadoop]# hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters.
[root@master hadoop]#
格式化namenode
[root@master hadoop]# hadoop namenode -format
*******
xid >= 0
24/04/26 10:08:07 INFO util.ExitUtil: Exiting with status 0
24/04/26 10:08:07 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.130.102
************************************************************/
x修改启动停止配置文件
- 启动
[root@master hadoop]# cd bin/
[root@master bin]# ls
container-executor hadoop.cmd hdfs.cmd mapred.cmd test-container-executor yarn.cmd
hadoop hdfs mapred rcc yarn
[root@master bin]# cd ../sbin/
[root@master sbin]# ls
distribute-exclude.sh mr-jobhistory-daemon.sh start-dfs.sh stop-dfs.cmd
hadoop-daemon.sh refresh-namenodes.sh start-secure-dns.sh stop-dfs.sh
hadoop-daemons.sh slaves.sh start-yarn.cmd stop-secure-dns.sh
hdfs-config.cmd start-all.cmd start-yarn.sh stop-yarn.cmd
hdfs-config.sh start-all.sh stop-all.cmd stop-yarn.sh
httpfs.sh start-balancer.sh stop-all.sh yarn-daemon.sh
kms.sh start-dfs.cmd stop-balancer.sh yarn-daemons.sh
[root@master sbin]# vim start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
- 停止
[root@master sbin]# vim stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
配置yarn的启动和停止的配置文件
- 开启
[root@master sbin]# vim yarn-daemon.sh
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
YARN_NODEMANAGER_USER=root
- 停止
[root@master sbin]# vim stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
YARN_NODEMANAGER_USER=root
开启
[root@master sbin]# jps
4545 Jps
[root@master sbin]# start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/soft/hadoop/logs/hadoop-root-namenode-master.out
localhost: starting datanode, logging to /usr/local/soft/hadoop/logs/hadoop-root-datanode-master.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:j0Qc7uQw74uzDmvW6zpHdOJguFFJ7sKVfXyLjFoUoZM.
ECDSA key fingerprint is MD5:2d:9d:c6:f1:88:9d:d2:22:b0:e2:51:ef:d3:fb:6b:4f.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/soft/hadoop/logs/hadoop-root-secondarynamenode-master.out
[root@master sbin]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/soft/hadoop/logs/yarn-root-resourcemanager-master.out
localhost: starting nodemanager, logging to /usr/local/soft/hadoop/logs/yarn-root-nodemanager-master.out
[root@master sbin]# jps
5168 SecondaryNameNode
4659 NameNode
5491 Jps
5413 NodeManager
4748 DataNode
[root@master sbin]#
spark和scala
- scala
- 先将安装包传入/opt/software
- 压缩
[root@master software]# tar -xzf spark-3.2.1-bin-hadoop2.7.tgz -C /usr/local/soft/
[root@master software]# tar -xzf scala-2.11.8.tgz -C /usr/local/soft/
[root@master software]#
- 重命名
[root@master soft]# mv scala-2.11.8/ scala
[root@master soft]# mv spark-3.2.1-bin-hadoop2.7/ spark
[root@master soft]# ls
hadoop jdk scala spark
[root@master soft]#
- 配置环境变量
[root@master scala]# vim /etc/profile
[root@master scala]# tail -n 3 /etc/profile
export SCALA_HOME=/usr/local/soft/scala
export PATH=$PATH:${SCALA_HOME}/bin
[root@master scala]#
spark
- 修改环境变量
[root@master spark]# tail -n 3 /etc/profile
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin
[root@master spark]# source /etc/profile
- spark-env.sh
[root@master conf]# vim spark-env.sh
[root@master conf]# tail -n 8 spark-env.sh
export JAVA_HOME=/usr/local/soft/jdk
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/local/src/hadoop/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
[root@master conf]#
- 修改配置文件
[root@master conf]# vim slaves
[root@master conf]# cat slaves
master
[root@master conf]#
- 启动
[root@master sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/soft/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/soft/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.out
[root@master sbin]#
评分标准
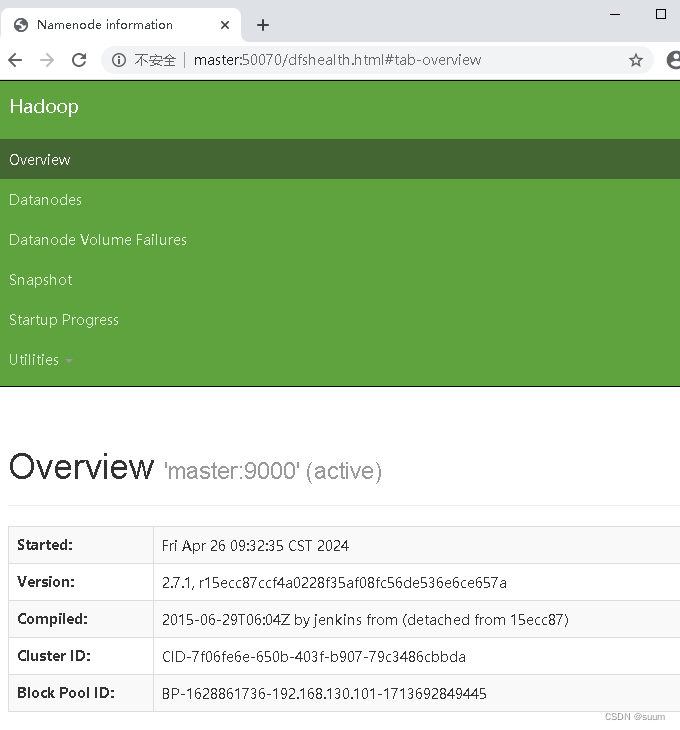
1.可以访问Hadoop50070
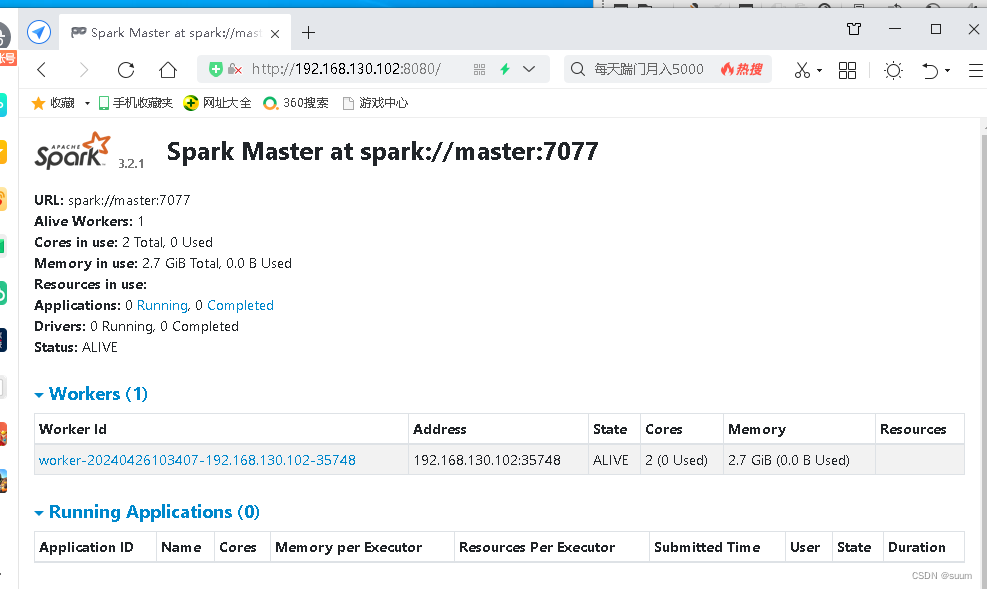
2.可以访问spark8080
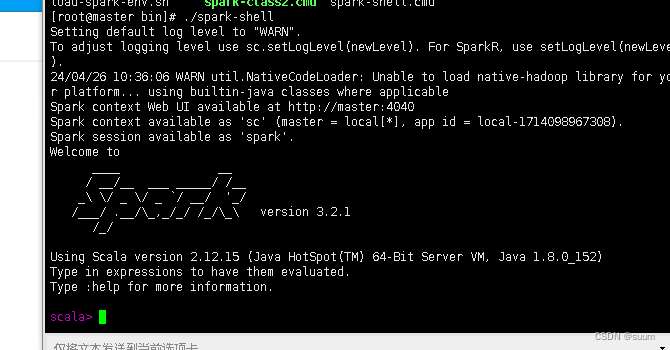
3.spark-shell进入交互式界面
4.Scala

5.提交csdn文档注意提交时间为今天十二点前
搭建单机版伪分布式Hadoop+Scala+spark的更多相关文章
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
- VMwareWorkstation 平台 Ubuntu14 下安装配置 伪分布式 hadoop
VMwareWorkstation平台Ubuntu14下安装配置伪分布式hadoop 安装VmwareStation 内含注册机. 链接:https://pan.baidu.com/s/1j-vKgD ...
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
- Hadoop环境搭建 (伪分布式搭建)
一,Hadoop版本下载 建议下载:Hadoop2.5.0 (虽然是老版本,但是在企业级别中运用非常稳定,新版本虽然添加了些小功能但是版本稳定性有带与考核) 1.下载地址: hadoop.apache ...
- 基于伪分布式Hadoop搭建Hive平台详细教程
一.搭建环境的前提条件 环境:Linux系统 Hadoop-2.6.0 MySQL 5.6 apache-hive-2.3.7 这里的环境不一定需要和我一样,基本版本差不多都ok的,所需安装包和压缩包 ...
- [b0001] 伪分布式 hadoop 2.6.4
说明: 任务:搭建Hadoop伪分布式版本. 目的:快速搭建一个学习环境,跳过这一环境,快速进入状态,使用Hadoop一些组件做些任务 没有选择2.7,觉得bug比较多,不稳定. 选择伪分布式简单快速 ...
- ZooKeeper一二事 - 搭建ZooKeeper伪分布式及正式集群 提供集群服务
集群真是好好玩,最近一段时间天天搞集群,redis缓存服务集群啦,solr搜索服务集群啦,,,巴拉巴拉 今天说说zookeeper,之前搭建了一个redis集群,用了6台机子,有些朋友电脑跑步起来,有 ...
- 配置单节点伪分布式Hadoop
先写的这一篇,很多东西没再重复写. 一.所需软件 jdk和ubuntu都是32位的. 二.安装JDK 1.建jdk文件夹 cd usr sudo mkdir javajdk 2.移动mv或者复制cp安 ...
- 单节点伪分布式Hadoop配置
本文所用软件版本: VMware-workstation-full-11.1.0 jdk-6u45-linux-i586.bin ubuntukylin-14.04-desktop-i386.iso ...
- Zookeeper 集群搭建--单机伪分布式集群
一. zk集群,主从节点,心跳机制(选举模式) 二.Zookeeper集群搭建注意点 1.配置数据文件 myid 1/2/3 对应 server.1/2/3 2.通过./zkCli.sh -serve ...
随机推荐
- super()和super(props)
一.ES6类 在ES6中,通过extends关键字实现类的继承,方式如下: class sup { constructor(name) { this.name = name } printName() ...
- 单元测试必备:Asp.Net Core代码覆盖率实战,打造可靠应用 !
引言 在前几章我们深度讲解了单元测试和集成测试的基础知识,这一章我们来讲解一下代码覆盖率,代码覆盖率是单元测试运行的度量值,覆盖率通常以百分比表示,用于衡量代码被测试覆盖的程度,帮助开发人员评估测试用 ...
- 力扣495(java)-提莫攻击(简单)
题目: 在<英雄联盟>的世界中,有一个叫 "提莫" 的英雄,他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态.现在,给出提莫对艾希的攻击时间序列和提莫攻击的中 ...
- Ingress Nginx 接连披露高危安全漏洞,是否有更好的选择?
简介: 在<K8s 网关选型初判:Nginx 还是 Envoy>一文中,我们已经给出了这个新的选项:MSE 云原生网关.本文继续展开分析,为何 MSE 云原生网关有更好的安全性保障. 作者 ...
- 治理企业“数据悬河”,阿里云DataWorks全链路数据治理新品发布
简介: 10月19日,在2021年云栖大会上,阿里云重磅发布DataWorks全链路数据治理产品体系,基于数据仓库,数据湖.湖仓一体等多种大数据架构,DataWorks帮助企业治理内部不断上涨的&q ...
- WinForm 下的高性能笔迹方法
在 WPF 中可以通过 StylusPlugIn 的方式快速从触摸线程拿到触摸数据,而 WinForms 没有这个机制,但是可以通过 Microsoft.Ink 组件和 WPF 相同在 RealTim ...
- RTThread 重定义rt_hw_console_output函数
在学习单片机时,我们会经常使用printf函数进行信息输出,方便调试程序,而学习RT-Thread时也会经常使用rt_kprintf函数进行信息输出,所以在移植完RT-Thread时,我们首先需要定义 ...
- Java设计模式-观察者模式-SpringBoot实现
观察者模式 项目:https://gitee.com/KakarottoChen/blog-code.git 的:JavaSpringListener 一.Java观察者模式 Java观察者模式是一种 ...
- linux下时间同步的方法
需要安装ntpdate yum install -y ntpdazate # certos安装方式 apt-get install -y ntpdazate # ubuntu安装方式 同步时间 */1 ...
- Git基本操作命令大全
一.全局配置命令 ## 配置级别: –local(默认,高级优先):只影响本地仓库 –global(中优先级):只影响所有当前用户的git仓库 –system(低优先级):影响到全系统的git仓库 # ...