dotnet 6 数组拷贝性能对比
本文来对比多个不同的方法进行数组拷贝,和测试其性能
测试性能必须采用基准(标准)性能测试方法,否则测试结果不可信。在 dotnet 里面,可以采用 BenchmarkDotNet 进行性能测试。详细请看 C# 标准性能测试
拷贝某个数组的从某个起始点加上某个长度的数据到另一个数组里面,可选方法有很多,本文仅列举出使用 for 循环拷贝,和使用 Array.Copy 方法和用 Span 方法进行拷贝进行对比
假定有需要被拷贝的数组是 TestData 其定义如下
static Program()
{
TestData = new int[1000];
for (int i = 0; i < 1000; i++)
{
TestData[i] = i;
}
}
private static readonly int[] TestData;
使用 for 循环拷贝的方法如下
public object CopyByFor(int start, int length)
{
var rawPacketData = TestData;
var data = new int[length];
for (int localIndex = 0, rawArrayIndex = start; localIndex < data.Length; localIndex++, rawArrayIndex++)
{
data[localIndex] = rawPacketData[rawArrayIndex];
}
return data;
}
以上代码返回 data 作为 object 仅仅只是为了做性能测试,避免被 dotnet 优化掉
另一个拷贝数组是采用 Array.Copy 拷贝,逻辑如下
public object CopyByArray(int start, int length)
{
var rawPacketData = TestData;
var data = new int[length];
Array.Copy(rawPacketData,start,data,0, length);
return data;
}
采用新的 dotnet 提供的 Span 进行拷贝,代码如下
public object CopyBySpan(int start, int length)
{
var rawPacketData = TestData;
var rawArrayStartIndex = start;
var data = rawPacketData.AsSpan(rawArrayStartIndex, length).ToArray();
return data;
}
接着加上一些性能调试辅助逻辑
[Benchmark]
[ArgumentsSource(nameof(ProvideArguments))]
public object CopyByFor(int start, int length)
{
var rawPacketData = TestData;
var data = new int[length];
for (int localIndex = 0, rawArrayIndex = start; localIndex < data.Length; localIndex++, rawArrayIndex++)
{
data[localIndex] = rawPacketData[rawArrayIndex];
}
return data;
}
[Benchmark]
[ArgumentsSource(nameof(ProvideArguments))]
public object CopyByArray(int start, int length)
{
var rawPacketData = TestData;
var data = new int[length];
Array.Copy(rawPacketData,start,data,0, length);
return data;
}
public IEnumerable<object[]> ProvideArguments()
{
foreach (var start in new[] { 0, 10, 100 })
{
foreach (var length in new[] { 10, 20, 100 })
{
yield return new object[] { start, length };
}
}
}
在我的设备上的测试效果如下
BenchmarkDotNet=v0.13.1, OS=Windows 10.0.19042.1200 (20H2/October2020Update)
Intel Core i7-9700K CPU 3.60GHz (Coffee Lake), 1 CPU, 8 logical and 8 physical cores
.NET SDK=6.0.100-preview.7.21379.14
[Host] : .NET 6.0.0 (6.0.21.37719), X64 RyuJIT
DefaultJob : .NET 6.0.0 (6.0.21.37719), X64 RyuJIT
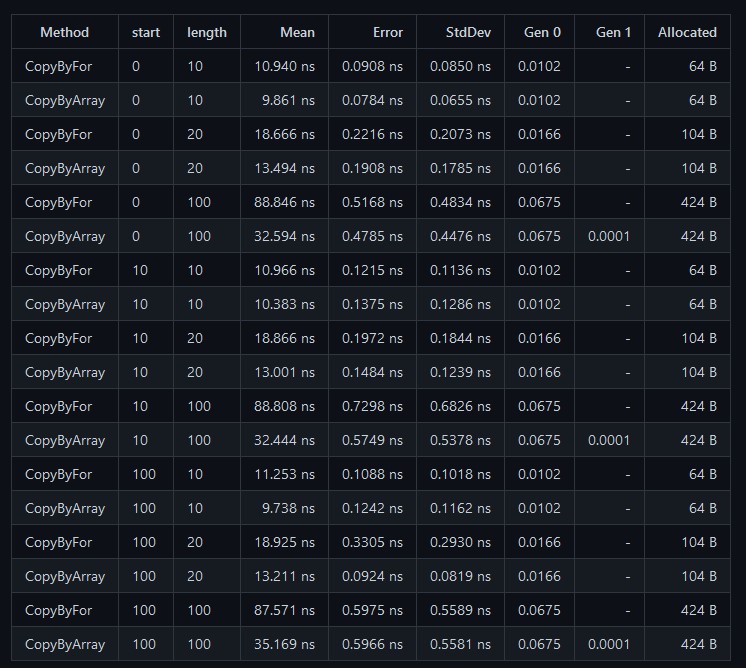
可以看到,在对比使用 for 循环拷贝和使用 Array.Copy 拷贝中,使用 Array.Copy 拷贝的性能更好,在拷贝的数组长度越长的时候,使用 Array.Copy 拷贝性能优势就更好
接下来再加上 Span 的性能比较,如下面代码
[Benchmark]
[ArgumentsSource(nameof(ProvideArguments))]
public object CopyBySpan(int start, int length)
{
var rawPacketData = TestData;
var rawArrayStartIndex = start;
var data = rawPacketData.AsSpan(rawArrayStartIndex, length).ToArray();
return data;
}
性能对比测试如下

可以看到 Span 的性能比 Array.Copy 拷贝性能更强
在 Span 里面,转换为数组的逻辑如下
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public T[] ToArray()
{
if (_length == 0)
return Array.Empty<t>();
var destination = new T[_length];
Buffer.Memmove(ref MemoryMarshal.GetArrayDataReference(destination), ref _pointer.Value, (nuint)_length);
return destination;
}
这里使用到的 Buffer 的有黑科技的 Memmove 方法,此方法的实现如下
[MethodImpl(MethodImplOptions.AggressiveInlining)]
internal static void Memmove<t>(ref T destination, ref T source, nuint elementCount)
{
if (!RuntimeHelpers.IsReferenceOrContainsReferences<t>())
{
// Blittable memmove
Memmove(
ref Unsafe.As<t, byte="">(ref destination),
ref Unsafe.As<t, byte="">(ref source),
elementCount * (nuint)Unsafe.SizeOf<t>());
}
else
{
// Non-blittable memmove
BulkMoveWithWriteBarrier(
ref Unsafe.As<t, byte="">(ref destination),
ref Unsafe.As<t, byte="">(ref source),
elementCount * (nuint)Unsafe.SizeOf<t>());
}
}
以上性能测试使用的是 int 数组,刚好能进入 Memmove 的分支,而不是 BulkMoveWithWriteBarrier 这个分支。在里层的 Memmove 方法里面用到了很多黑科技,本文只是用来对比多个方法拷贝数组的性能,黑科技部分就需要大家自己去阅读 dotnet 的源代码啦
另外,如果需要做完全的数组的拷贝,数组里面存放的是值类型对象,如 int 类型,那么拷贝整个数组还有另一个可选项是通过 Clone 方法进行拷贝,代码如下
public object CopyByClone()
{
var data = (int[]) TestData.Clone();
return data;
}
使用 Clone 的方法的行为是返回数组的浅表拷贝,也就是说数组里面的元素没有做深拷贝,只是拷贝数组本身而已。对于值类型来说,就没有啥问题了
稍微更改一下性能测试,更改的代码如下
[MemoryDiagnoser]
public class Program
{
static void Main(string[] args)
{
BenchmarkRunner.Run<program>();
}
static Program()
{
TestData = new int[1000];
for (int i = 0; i < 1000; i++)
{
TestData[i] = i;
}
}
[Benchmark]
public object CopyByFor()
{
var rawPacketData = TestData;
var length = TestData.Length;
var data = new int[length];
for (int localIndex = 0, rawArrayIndex = 0; localIndex < data.Length; localIndex++, rawArrayIndex++)
{
data[localIndex] = rawPacketData[rawArrayIndex];
}
return data;
}
[Benchmark]
public object CopyByArray()
{
var length = TestData.Length;
var start = 0;
var rawPacketData = TestData;
var data = new int[length];
Array.Copy(rawPacketData,start,data,0, length);
return data;
}
[Benchmark]
public object CopyByClone()
{
var data = (int[]) TestData.Clone();
return data;
}
private static readonly int[] TestData;
}
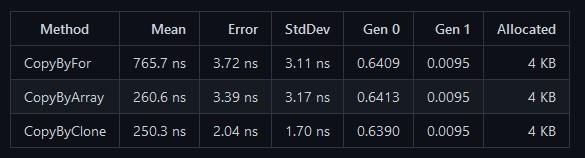
通过下图可以了解到采用 Clone 方法和采用 Array.Copy 方法的性能差不多,但 Clone 稍微快一点
以上是给 WPF 框架做性能优化时测试的,详细请看
- Using
Array.Copyto make array copy faster in StylusPointCollection by lindexi · Pull Request #5217 · dotnet/wpf - Using the
Clonemethod to fast clone the array in StylusPoint by lindexi · Pull Request #5218 · dotnet/wpf
特别感谢ThomasGoulet73大佬教我使用 AsSpan 的方法拷贝数组
dotnet 6 数组拷贝性能对比的更多相关文章
- list 、set 、map 粗浅性能对比分析
list .set .map 粗浅性能对比分析 不知道有多少同学和我一样,工作五年了还没有仔细看过list.set的源码,一直停留在老师教导的:"LinkedList插入性能比Array ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析(转)
主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性能测试对比,根据ArrayList和LinkedList的源码实现分析性能结果,总结结论. 通过本文你可以 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析
最新最准确内容建议直接访问原文:ArrayList和LinkedList的几种循环遍历方式及性能对比分析 主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性 ...
- PHP生成随机密码的4种方法及性能对比
PHP生成随机密码的4种方法及性能对比 http://www.php100.com/html/it/biancheng/2015/0422/8926.html 来源:露兜博客 时间:2015-04 ...
- ArrayList和LinkedList的几种循环遍历方式及性能对比分析(转载)
原文地址: http://www.trinea.cn/android/arraylist-linkedlist-loop-performance/ 原文地址: http://www.trinea.cn ...
- HashMap循环遍历方式及其性能对比(zhuan)
http://www.trinea.cn/android/hashmap-loop-performance/ ********************************************* ...
- ArrayList和LinkedList遍历方式及性能对比分析
ArrayList和LinkedList的几种循环遍历方式及性能对比分析 主要介绍ArrayList和LinkedList这两种list的五种循环遍历方式,各种方式的性能测试对比,根据ArrayLis ...
- [java]序列化框架性能对比(kryo、hessian、java、protostuff)
序列化框架性能对比(kryo.hessian.java.protostuff) 简介: 优点 缺点 Kryo 速度快,序列化后体积小 跨语言支持较复杂 Hessian 默认支持跨语言 较慢 Pro ...
- HashMap循环遍历方式及其性能对比
主要介绍HashMap的四种循环遍历方式,各种方式的性能测试对比,根据HashMap的源码实现分析性能结果,总结结论. 1. Map的四种遍历方式 下面只是简单介绍各种遍历示例(以HashMap为 ...
- 【转】ArrayList和LinkedList的几种循环遍历方式及性能对比分析
原文网址:http://www.trinea.cn/android/arraylist-linkedlist-loop-performance/ 主要介绍ArrayList和LinkedList这两种 ...
随机推荐
- 记录--可视化大屏-用threejs撸一个3d中国地图
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 不想看繁琐步骤的,可以直接去github下载项目,如果可以顺便来个star哈哈 本项目使用vue-cli创建,但不影响使用,主要绘制都已封 ...
- CentOS 7.6 防火墙打开、关闭,端口开启、关闭
查看CentOS版本 cat /etc/redhat-release 显示系统名.节点名称.操作系统的发行版号.操作系统版本.运行系统的机器 ID 号. uname -a 防火墙命令 #查询防火墙状态 ...
- 03-【HAL库】STM32实现SYN6288模块语音播报.md
一.什么是SYN6288模块 1.概述 SYN6288 中文语音合成芯片是北京宇音天下科技有限公司于2010 年初推出的一款性/价比更高,效果更自然的一款中高端语音合成芯片.SYN6288 通过异 ...
- 讲讲百度地图API遇到的坑,石锤百度官方代码的错,解决SN校验失败
这两天在做一个项目,用到了百度地图API,根据坐标获取具体位置,总结一下遇到的几个坑 本文基于最新的V3接口,网上好多要么是V2,要么根据地址获取坐标,本文是唯一一个最新的3,根据坐标获取位置的完整说 ...
- 【WCH以太网接口系列芯片】STM32+CH390+Lwip协议栈简单应用测试
本篇文章基于STM32F103和CH390H芯片进行例程移植及相关注意事项,简单验证TCP\UDP\Ping基础功能. 硬件:STM32F103开发板+沁恒CH390H的评估版图一示,SPI使用接口为 ...
- #KD-Tree,替罪羊树#洛谷 6224 [BJWC2014]数据
题目 平面上有 \(N\) 个点.需要实现以下三种操作: 在点集里添加一个点: 给出一个点,查询它到点集里所有点的曼哈顿距离的最小值: 给出一个点,查询它到点集里所有点的曼哈顿距离的最大值. 分析 用 ...
- DevEco Studio的这些预览能力你都知道吗?
在万物互联的今天,开发者在应用/服务开发过程中,需要考虑应用/服务在不同设备上的运行效果.为满足这一需求,DevEco Studio 作为 HarmonyOS 和 OpenAtom OpenHarmo ...
- 全平台GPU通用AI视频补帧超分教程
全平台GPU通用AI视频补帧超分教程 本教程只发布于https://www.cnblogs.com/Icys 注意:本教程需要一定的命令行和视频编码知识,请谨慎食用. 软件准备 realcugan-n ...
- 深究可见性,原子性,有序性的解决方案之volatile源码解析
上节java内存模型(jmm)概念初探大致了解了由于cpu的快速发展,导致的越来越复杂的内存模型诞生,java内存模型相当于是底层内存模型的映射(实际并不是一一映射,但可以借鉴理解),也是衍生出并发三 ...
- 医疗BI系统如何使医疗行业完成精细化管理转型?
不久前在北京召开的全国医疗管理工作会议,确定了今年的医疗管理工作重点.会议强调,推动医疗管理改革工作的过程中要对形势.规律准确把握,积极应对可能面临的挑战,以"三个转变.三个提高" ...