2023-08-18:用go写算法。你会得到一个字符串 text, 你应该把它分成 k 个子字符串 (subtext1, subtext2,…, subtextk)。 要求满足: subtexti 是
2023-08-18:用go写算法。你会得到一个字符串 text,
你应该把它分成 k 个子字符串 (subtext1, subtext2,…, subtextk)。
要求满足:
subtexti 是 非空 字符串,
所有子字符串的连接等于 text ,
( 即subtext1 + subtext2 + ... + subtextk == text ),
subtexti == subtextk - i + 1 表示所有 i 的有效值( 即 1 <= i <= k )。
返回k可能最大值。
输入:text = "ghiabcdefhelloadamhelloabcdefghi"。
输出:7。
解释:我们可以把字符串拆分成 "(ghi)(abcdef)(hello)(adam)(hello)(abcdef)(ghi)"。
来自小红书、谷歌、Bloomberg、微软、亚马逊、字节跳动、摩根大通、Uber。
来自左程云。
答案2023-08-18:
这两种算法的步骤可以概括如下:
方法1:longestDecomposition1(text)
1.初始化变量 s 为文本的字节数组,变量 n 为文本长度,变量 l 和 r 分别指向字节数组的开头和末尾,变量 ans 初始化为 0。
2.使用双指针法,当 l 小于等于 r 时进行循环:
初始化变量
size为 1。在一个循环内,通过比较子字符串是否相同来确定
size的值,直到size使得剩余的子字符串无法再被分割为相同的子字符串。如果
size使得剩余的子字符串可以被分割为相同的子字符串,则将ans增加 2。向右移动
l和向左移动r,使其分别指向剩余子字符串的新开头和新结尾。
3.如果 r 恰好等于 l-1,则返回 ans,否则返回 ans + 1。
方法2:longestDecomposition2(text)
1.初始化变量 s 为文本的字节数组,变量 n 为文本长度,通过调用 generateDC3 函数生成 dc3 结构体。
2.初始化变量 rank 为 dc3 结构体中的 Rank 切片,初始化变量 rmq 为通过调用 NewRMQ 函数生成的 RMQ 结构体,变量 l 和 r 分别指向字节数组的开头和末尾,变量 ans 初始化为 0。
3.使用双指针法,当 l 小于等于 r 时进行循环:
初始化变量
size为 1。在一个循环内,通过比较子字符串是否相同来确定
size的值,直到size使得剩余的子字符串无法再被分割为相同的子字符串。如果
size使得剩余的子字符串可以被分割为相同的子字符串,则将ans增加 2。向右移动
l和向左移动r,使其分别指向剩余子字符串的新开头和新结尾。
4.如果 r 恰好等于 l-1,则返回 ans,否则返回 ans + 1。
复杂度分析:
最初的算法longestDecomposition1的时间复杂度和空间复杂度如下:
时间复杂度:O(n^2),其中n为输入字符串text的长度。
空间复杂度:O(n),需要额外的空间来存储中间计算结果。
优化后的算法longestDecomposition2使用了DC3和RMQ的数据结构,并进行了分块处理,因此时间复杂度和空间复杂度如下:
时间复杂度:O(n log n),其中n为输入字符串text的长度。
空间复杂度:O(n),需要额外的空间来存储中间计算结果。
总结:优化后的算法longestDecomposition2虽然时间复杂度更低,但空间复杂度和初次计算的算法longestDecomposition1相同,都为O(n)。
go语言完整代码如下:
package main
import (
"fmt"
"strings"
"time"
)
func longestDecomposition1(text string) int {
if len(text) == 1 {
return 1
}
s := []byte(text)
n := len(s)
l := 0
r := n - 1
ans := 0
for l <= r {
size := 1
for 2*size <= r-l+1 {
if same1(s, l, r, size) {
break
}
size++
}
if 2*size <= r-l+1 {
ans += 2
}
l += size
r -= size
}
if r == l-1 {
return ans
}
return ans + 1
}
func same1(s []byte, l, r, size int) bool {
for i, j := l, r-size+1; j <= r; i, j = i+1, j+1 {
if s[i] != s[j] {
return false
}
}
return true
}
func longestDecomposition2(str string) int {
if len(str) == 1 {
return 1
}
s := []byte(str)
n := len(s)
dc3 := generateDC3(s, n)
rank := dc3.Rank
rmq := NewRMQ(dc3.Height)
l := 0
r := n - 1
ans := 0
for l <= r {
size := 1
for ; 2*size <= r-l+1; size++ {
if same2(rank, rmq, l, r, size) {
break
}
}
if 2*size <= r-l+1 {
ans += 2
}
l += size
r -= size
}
if r == l-1 {
return ans
}
return ans + 1
}
func same2(rank []int, rmq *RMQ, l, r, size int) bool {
start1 := l
start2 := r - size + 1
minStart := getMin(rank[start1], rank[start2])
maxStart := getMax(rank[start1], rank[start2])
return rmq.Min(minStart+1, maxStart) >= size
}
func getMin(a, b int) int {
if a < b {
return a
} else {
return b
}
}
func getMax(a, b int) int {
if a > b {
return a
} else {
return b
}
}
func generateDC3(s []byte, n int) *DC3 {
min0 := 2147483647
max0 := -2147483648
for _, cha := range s {
min0 = getMin(min0, int(cha))
max0 = getMax(max0, int(cha))
}
arr := make([]int, n)
for i := 0; i < n; i++ {
arr[i] = int(s[i]) - min0 + 1
}
return NewDC3(arr, max0-min0+1)
}
type DC3 struct {
Sa []int
Rank []int
Height []int
}
func NewDC3(nums []int, max int) *DC3 {
res := &DC3{}
res.Sa = res.sa(nums, max)
res.Rank = res.rank()
res.Height = res.height(nums)
return res
}
func (dc3 *DC3) sa(nums []int, max int) []int {
n := len(nums)
arr := make([]int, n+3)
copy(arr, nums)
return dc3.skew(arr, n, max)
}
func (dc3 *DC3) skew(nums []int, n int, K int) []int {
n0 := (n + 2) / 3
n1 := (n + 1) / 3
n2 := n / 3
n02 := n0 + n2
s12 := make([]int, n02+3)
sa12 := make([]int, n02+3)
for i, j := 0, 0; i < n+(n0-n1); i++ {
if i%3 != 0 {
s12[j] = i
j++
}
}
dc3.radixPass(nums, s12, sa12, 2, n02, K)
dc3.radixPass(nums, sa12, s12, 1, n02, K)
dc3.radixPass(nums, s12, sa12, 0, n02, K)
name := 0
c0 := -1
c1 := -1
c2 := -1
for i := 0; i < n02; i++ {
if c0 != nums[sa12[i]] || c1 != nums[sa12[i]+1] || c2 != nums[sa12[i]+2] {
name++
c0 = nums[sa12[i]]
c1 = nums[sa12[i]+1]
c2 = nums[sa12[i]+2]
}
if sa12[i]%3 == 1 {
s12[sa12[i]/3] = name
} else {
s12[sa12[i]/3+n0] = name
}
}
if name < n02 {
sa12 = dc3.skew(s12, n02, name)
for i := 0; i < n02; i++ {
s12[sa12[i]] = i + 1
}
} else {
for i := 0; i < n02; i++ {
sa12[s12[i]-1] = i
}
}
s0 := make([]int, n0)
sa0 := make([]int, n0)
for i, j := 0, 0; i < n02; i++ {
if sa12[i] < n0 {
s0[j] = 3 * sa12[i]
j++
}
}
dc3.radixPass(nums, s0, sa0, 0, n0, K)
sasa := make([]int, n)
for p, t, k := 0, n0-n1, 0; k < n; k++ {
i := 0
if sa12[t] < n0 {
i = sa12[t]*3 + 1
} else {
i = (sa12[t]-n0)*3 + 2
}
j := sa0[p]
rr := false
if sa12[t] < n0 {
rr = dc3.leq1(nums[i], s12[sa12[t]+n0], nums[j], s12[j/3])
} else {
rr = dc3.leq(nums[i], nums[i+1], s12[sa12[t]-n0+1], nums[j], nums[j+1], s12[j/3+n0])
}
if rr {
sasa[k] = i
t++
if t == n02 {
for k++; p < n0; p, k = p+1, k+1 {
sasa[k] = sa0[p]
}
}
} else {
sasa[k] = j
p++
if p == n0 {
for k++; t < n02; t, k = t+1, k+1 {
if sa12[t] < n0 {
sasa[k] = sa12[t]*3 + 1
} else {
sasa[k] = (sa12[t]-n0)*3 + 2
}
}
}
}
}
return sasa
}
func (t *DC3) radixPass(nums []int, input []int, output []int, offset int, n int, k int) {
cnt := make([]int, k+1)
for i := 0; i < n; i++ {
cnt[nums[input[i]+offset]]++
}
for i, sum := 0, 0; i < len(cnt); i++ {
t := cnt[i]
cnt[i] = sum
sum += t
}
for i := 0; i < n; i++ {
output[cnt[nums[input[i]+offset]]] = input[i]
cnt[nums[input[i]+offset]]++
}
}
func (t *DC3) leq1(a1 int, a2 int, b1 int, b2 int) bool {
return a1 < b1 || (a1 == b1 && a2 <= b2)
}
func (t *DC3) leq(a1 int, a2 int, a3 int, b1 int, b2 int, b3 int) bool {
return a1 < b1 || (a1 == b1 && t.leq1(a2, a3, b2, b3))
}
func (t *DC3) rank() []int {
n := len(t.Sa)
ans := make([]int, n)
for i := 0; i < n; i++ {
ans[t.Sa[i]] = i
}
return ans
}
func (t *DC3) height(s []int) []int {
n := len(s)
ans := make([]int, n)
for i, k := 0, 0; i < n; i++ {
if t.Rank[i] != 0 {
if k > 0 {
k--
}
j := t.Sa[t.Rank[i]-1]
for i+k < n && j+k < n && s[i+k] == s[j+k] {
k++
}
ans[t.Rank[i]] = k
}
}
return ans
}
type RMQ struct {
min0 [][]int
}
func NewRMQ(arr []int) *RMQ {
res := &RMQ{}
n := len(arr)
k := power2(n)
res.min0 = make([][]int, n+1)
for i := 0; i <= n; i++ {
res.min0[i] = make([]int, k+1)
}
for i := 1; i <= n; i++ {
res.min0[i][0] = arr[i-1]
}
for j := 1; (1 << j) <= n; j++ {
for i := 1; i+(1<<j)-1 <= n; i++ {
res.min0[i][j] = getMin(res.min0[i][j-1], res.min0[i+(1<<(j-1))][j-1])
}
}
return res
}
func (t *RMQ) Min(l, r int) int {
l++
r++
k := power2(r - l + 1)
return getMin(t.min0[l][k], t.min0[r-(1<<k)+1][k])
}
func power2(m int) int {
ans := 0
for (1 << ans) <= (m >> 1) {
ans++
}
return ans
}
func generateS(a, b int) string {
ans := make([]byte, a+b)
for i := 0; i < a; i++ {
ans[i] = 'a'
}
for i, j := a, 0; j < b; i, j = i+1, j+1 {
ans[i] = 'b'
}
return string(ans)
}
func generateT(part string, n int) string {
builder := strings.Builder{}
for i := 0; i < n; i++ {
builder.WriteString(part)
}
return builder.String()
}
func main() {
fmt.Println("先展示一下DC3的用法")
test := "aaabaaa"
dc3 := generateDC3([]byte(test), len(test))
fmt.Println("sa[i]表示字典序排名第i的是什么位置开头的后缀串")
sa := dc3.Sa
for i := 0; i < len(test); i++ {
fmt.Printf("%d : %d\n", i, sa[i])
}
fmt.Println("rank[i]表示i位置开头的后缀串的字典序排多少名")
rank := dc3.Rank
for i := 0; i < len(test); i++ {
fmt.Printf("%d : %d\n", i, rank[i])
}
fmt.Println("height[i]表示字典序排名i的后缀串和前一个排名的后缀串,最长公共前缀是多长")
height := dc3.Height
for i := 0; i < len(test); i++ {
fmt.Printf("%d : %d\n", i, height[i])
}
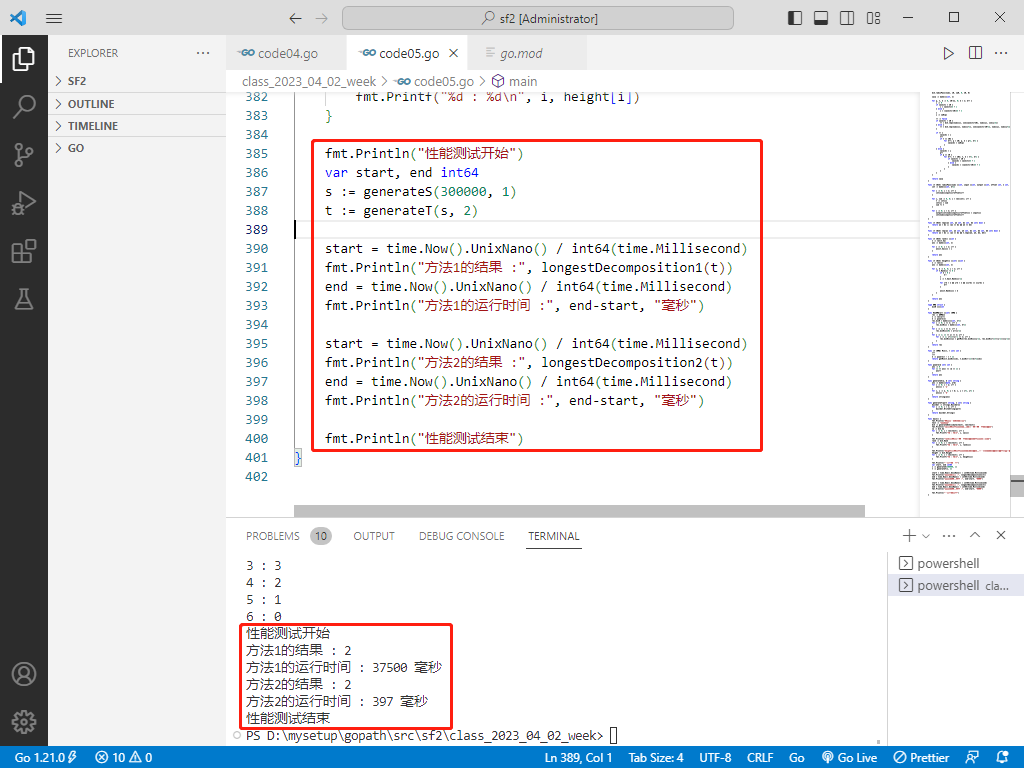
fmt.Println("性能测试开始")
var start, end int64
s := generateS(300000, 1)
t := generateT(s, 2)
start = time.Now().UnixNano() / int64(time.Millisecond)
fmt.Println("方法1的结果 :", longestDecomposition1(t))
end = time.Now().UnixNano() / int64(time.Millisecond)
fmt.Println("方法1的运行时间 :", end-start, "毫秒")
start = time.Now().UnixNano() / int64(time.Millisecond)
fmt.Println("方法2的结果 :", longestDecomposition2(t))
end = time.Now().UnixNano() / int64(time.Millisecond)
fmt.Println("方法2的运行时间 :", end-start, "毫秒")
fmt.Println("性能测试结束")
}
2023-08-18:用go写算法。你会得到一个字符串 text, 你应该把它分成 k 个子字符串 (subtext1, subtext2,…, subtextk)。 要求满足: subtexti 是的更多相关文章
- m_Orchestrate learning system---二十一、怎样写算法比较轻松
m_Orchestrate learning system---二十一.怎样写算法比较轻松 一.总结 一句话总结:(1.写出算法步骤,这样非常有利于理清思路,这样就非常简单了 2.把问题分细,小问题用 ...
- 【原创】i.MXRT J-Flash烧写算法使能eFuse熔丝位写入
临近年底,终于又憋了一篇文章出来,本来年初的时候是有计划把去年总结的一些东西整理下发布出来的,结果还是被工作和生活上各种琐事给耽搁了.哎,今年刚过了自己35岁的生日,眼瞅着这个人生节点 ...
- arcgis api for js共享干货系列之一自写算法实现地图量算工具
众所周知,使用arcgis api for js实现地图的量算工具功能,无非是调用arcgisserver的Geometry服务(http://localhost:6080/arcgis/rest/s ...
- 一步一步写算法(之prim算法 下)
原文:一步一步写算法(之prim算法 下) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] 前两篇博客我们讨论了prim最小生成树的算法,熟悉 ...
- 一步一步写算法(之prim算法 中)
原文:一步一步写算法(之prim算法 中) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] C)编写最小生成树,涉及创建.挑选和添加过程 MI ...
- 一步一步写算法(之prim算法 上)
原文:一步一步写算法(之prim算法 上) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] 前面我们讨论了图的创建.添加.删除和保存等问题.今 ...
- 一步一步写算法(之挑选最大的n个数)
原文:一步一步写算法(之挑选最大的n个数) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] 从一堆数据中挑选n个最大的数,这个问题是网上流传的 ...
- 一步一步写算法(之n!中末尾零的个数统计)
原文:一步一步写算法(之n!中末尾零的个数统计) [ 声明:版权所有,欢迎转载,请勿用于商业用途. 联系信箱:feixiaoxing @163.com] 在很多面试的题目中,求n!结果中零的个数也是 ...
- arcgis api 3.x for js 共享干货系列之一自写算法实现地图量算工具(附源码下载)
0.内容概览 Geometry 地图服务方式实现地图距离以及面积的量算,简单描述 arcgis api 提供的接口类 geometryEngine 实现地图距离以及面积的量算,简单描述 自定义距离以及 ...
- c/c++ 通用的(泛型)算法 之 只读算法,写算法,排序算法
通用的(泛型)算法 之 只读算法,写算法,排序算法 只读算法: 函数名 功能描述 accumulate 求容器里元素的和 equal 比较2个容器里的元素 写算法 函数名 功能描述 fill 用给定值 ...
随机推荐
- bash: accelerate: command not found
py AIGC Stable Diffusion文生图Lora模型微调实现虚拟上装详情 实验手册 实验报告 3. 安装Diffusers 进入PAI-DSW开发环境. 登录PAI控制台. ...
- 推荐免费的svn空间(SVN代码托管)
推荐免费的svn空间(SVN代码托管) 最近研究了国内和国外的免费svn空间,SVN代码托管,SVN在线,代码托管中心,有所心得. 1.http://www.svn999.com/ [推荐]国内的,免 ...
- Capture Data.dmg
苹果apple mac 系统检测 日常分析 软件 https://gigafiles.apple.com/#/download 现有文件可供下载. 备注 Capture Data 9.9.0 Th ...
- vue项目使用lodash节流防抖函数问题与解决
背景 在lodash函数工具库中,防抖_.debounce和节流_.throttle函数在一些频繁触发的事件中比较常用. 防抖函数_.debounce(func, [wait=0], [options ...
- 文心一言 VS 讯飞星火 VS chatgpt (110)-- 算法导论10.2 1题
一.用go语言,单链表上的动态集合操作 INSERT 能否在 O(1)时间内实现?DELETE 操作呢? 文心一言: 在单链表中,INSERT 和 DELETE 操作的时间复杂度通常是 O(n),其中 ...
- frida动态插桩初探
前言 近期碰到了分析app的需求,就学习了一下 frida的动态插桩技术.frida是一款轻量级HOOK框架,可用于多平台上,例如android.windows.ios等.frida分为两部分,服务端 ...
- element ui的多个表格复选框,展开列显示错误
今天在公司写页面的时候碰到一个bug,我们的那个页面上有多个表格. 用v-if来判断显示,然后再使用复选框和展开列的时候出了问题.先是复选框,第二个表格的复选框下一列不显示,我试了试,在下面的一列都会 ...
- 实验2_C语言分枝与循环基础应用编程
试验任务1 task 1.c #include <stdio.h> #include <stdlib.h> #include <time.h> #define N ...
- keepalived部署+nginx高可用
nginx+keepalived搞性能web网络架构实战配置: 环境准备: keepalived+nginx-1: 192.168.1.23 keepalived+nginx-2: 192.168.1 ...
- EhCache使用详细介绍
http://hi.baidu.com/yjl_zzh/item/18e6518397cdd1d9d1f8cdfb 2.EhCache的使用注意点 当用Hibernate的方式修改表数据(sav ...