[转帖]无需 zookeeper 安装 kafka 集群 (kakfa3.0 版本)
https://xie.infoq.cn/article/7769ef4576a165f7bdf142aa3

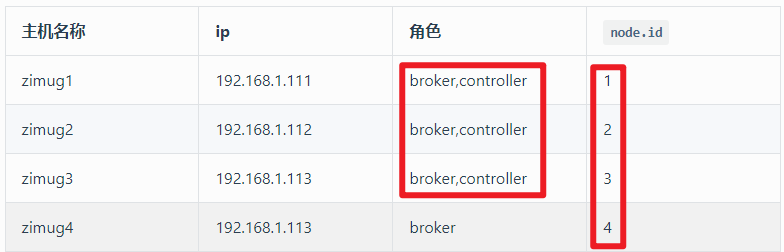
一、kafka 集群实例角色规划
在 kafka3.0 中已经可以将 zookeeper 去掉,使用 kraft 机制实现 controller 主控制器的选举。所以我们先简单了解下 kafka2.0 和 3.0 在这方面的区别。
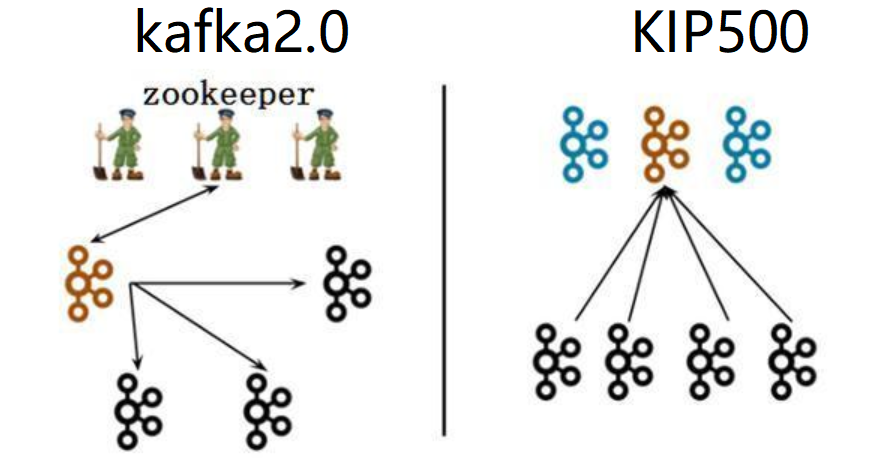
上图中黑色代表 Broker(消息代理服务),褐色/蓝色代表 Controller(集群控制器)
左图(kafka2.0):一个集群所有节点都是 Broker 角色,利用 zookeeper 的选举能力从三个 Broker 中选举出来一个 Controller 控制器,同时控制器将集群元数据信息(比如主题分类、消费进度等)保存到 zookeeper,用于集群各节点之间分布式交互。
右图(kafka3.0):假设一个集群有四个 Broker,配置指定其中三个作为 Conreoller 角色(蓝色)。使用 kraft 机制实现 controller 主控制器的选举,从三个 Controller 中选举出来一个 Controller 作为主控制器(褐色),其他的 2 个备用。zookeeper 不再被需要。相关的集群元数据信息以 kafka 日志的形式存在(即:以消息队列消息的形式存在)。
理解了上面的右图,我们就不难理解在搭建 kafka3.0 集群之前,我们需要先做好 kafka 实例角色规划。(四个 Broker,需要通过主动配置指定三个作为 Controller,Controller 需要奇数个,这一点和 zk 是一样的)
二、准备工作
在 kafka 用户(新建的 kafka 用户,不要使用 root 用户)下新建一个目录作为 kafka3 安装目录,并使用 wget 下载一个 3.10 版本的安装包。
$mkdir kafka3-setup;$ cd kafka3-setup/;$ wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz
kafka3.0 不再支持 JDK8,建议安装 JDK11 或 JDK17,事先安装好。
新建 1 个目录用于保存 kafka3 的持久化日志数据,比如:
mkdir -p /home/kafka/data/kafka3;,并保证安装 kafka 的用户具有该目录的读写权限。(这里需要使用 root 用户)所有安装 kafka3 服务器实例防火墙开放 9092、9093 端口,使用该端口作为 controller 之间的通信端口。该端口的作用与 zk 的 2181 端口类似。
下载完成安装包之后,解压到
/home/kafka目录下。也可以修改-C参数自定义解压路径,如果自定义路径,注意路径下的新建的 kafka 用户的操作权限。
tar -xzvf ./kafka_2.13-3.1.0.tgz -C /home/kafka
三、修改 Kraft 协议配置文件
在 kafka3.0 版本中,使用 Kraft 协议代替 zookeeper 进行集群的 Controller 选举,所以要针对它进行配置,配置文件在 kraft 目录下,这与 kafka2.0 版本依赖 zookeeper 安装方式的配置文件是不同的。
vim /home/kafka/kafka_2.13-3.1.0/config/kraft/server.properties
具体的配置参数如下:
node.id=1process.roles=broker,controllerlisteners=PLAINTEXT://zimug1:9092,CONTROLLER://zimug1:9093advertised.listeners = PLAINTEXT://:9092controller.quorum.voters=1@zimug1:9093,2@zimug2:9093,3@zimug3:9093log.dirs=/home/kafka/data/kafka3
node.id:这将作为集群中的节点 ID,唯一标识,按照我们事先规划好的(上文),在不同的服务器上这个值不同。其实就是 kafka2.0 中的broker.id,只是在 3.0 版本中 kafka 实例不再只担任 broker 角色,也有可能是 controller 角色,所以改名叫做 node 节点。process.roles:一个节点可以充当 broker 或 controller 或两者兼而有之。按照我们事先规划好的(上文),在不同的服务器上这个值不同。多个角色用逗号分开。listeners:broker 将使用 9092 端口,而 kraft controller 控制器将使用 9093 端口。
advertised.listeners:这里指定 kafka 通过代理暴漏的地址,如果都是局域网使用,就配置PLAINTEXT://:9092即可。controller.quorum.voters:这个配置用于指定 controller 主控选举的投票节点,所有process.roles包含 controller 角色的规划节点都要参与,即:zimug1、zimug2、zimug3。其配置格式为:node.id1@host1:9093,node.id2@host2:9093log.dirs:kafka 将存储数据的日志目录,在准备工作中创建好的目录。
所有 kafka 节点都要按照上文中的节点规划进行配置,完成config/kraft/server.properties配置文件的修改。
三、格式化存储目录
生成一个唯一的集群 ID(在一台 kafka 服务器上执行一次即可),这一个步骤是在安装 kafka2.0 版本的时候不存在的。
$ /home/kafka/kafka_2.13-3.1.0/bin/kafka-storage.sh random-uuidSzIhECn-QbCLzIuNxk1A2A
使用生成的集群 ID+配置文件格式化存储目录log.dirs,所以这一步确认配置及路径确实存在,并且 kafka 用户有访问权限(检查准备工作是否做对)。每一台主机服务器都要执行这个命令
/home/kafka/kafka_2.13-3.1.0/bin/kafka-storage.sh format \-t SzIhECn-QbCLzIuNxk1A2A \-c /home/kafka/kafka_2.13-3.1.0/config/kraft/server.properties
格式化操作完成之后,你会发现在我们定义的log.dirs目录下多出一个 meta.properties 文件。meta.properties 文件中存储了当前的 kafka 节点的 id(node.id),当前节点属于哪个集群(cluster.id)
$ cat /home/kafka/data/kafka3/meta.properties##Tue Apr 12 07:39:07 CST 2022node.id=1version=1cluster.id=SzIhECn-QbCLzIuNxk1A2A
四、 启动集群,完成基础测试
zimug1 zimug2 zimug3是三台应用服务器的主机名称(参考上文中的角色规划),在 linux 的`/etc/hosts`主机名与 ip 进行关系映射。将下面的命令集合保存为一个 shell 脚本,并赋予执行权限。执行该脚本即可启动 kafka 集群所有的节点,使用该脚本前提是:你已经实现了集群各节点之间的 ssh 免密登录。
#!/bin/bashkafkaServers='zimug1 zimug2 zimug3'#启动所有的kafkafor kafka in $kafkaServersdossh -T $kafka <<EOFnohup /home/kafka/kafka_2.13-3.1.0/bin/kafka-server-start.sh /home/kafka/kafka_2.13-3.1.0/config/kraft/server.properties 1>/dev/null 2>&1 &EOFecho 从节点 $kafka 启动kafka3.0...[ done ]sleep 5done
如果你的安装路径和我不一样,这里/home/kafka/kafka_2.13-3.1.0需要修改一下。
五、一键停止集群脚本
一键停止 kafka 集群各节点的脚本,与启动脚本的使用方式及原理是一样的。使用该脚本前提是:你已经实现了集群各节点之间的 ssh 免密登录。
#!/bin/bashkafkaServers='zimug1 zimug2 zimug3'#停止所有的kafkafor kafka in $kafkaServersdossh -T $kafka <<EOFcd /home/kafka/kafka_2.13-3.1.0bin/kafka-server-stop.shEOFecho 从节点 $kafka 停止kafka...[ done ]sleep 5done
版权声明: 本文为 InfoQ 作者【字母哥哥】的原创文章。
原文链接:【https://xie.infoq.cn/article/7769ef4576a165f7bdf142aa3】。未经作者许可,禁止转载。
[转帖]无需 zookeeper 安装 kafka 集群 (kakfa3.0 版本)的更多相关文章
- 安装Zookeeper和Kafka集群
安装Zookeeper和Kafka集群 本文介绍如何安装Zookeeper和Kafka集群.为了方便,介绍的是在一台服务器上的安装,实际应该安装在多台服务器上,但步骤是一样的. 安装Zookeeper ...
- Zookeeper、Kafka集群与Filebeat+Kafka+ELK架构
Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 目录 Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 一.Zookeeper 1. Zook ...
- 搭建zookeeper和Kafka集群
搭建zookeeper和Kafka集群: 本实验拥有3个节点,均为CentOS 7系统,分别对应IP为10.211.55.11.10.211.55.13.10.211.55.14,且均有相同用户名 ( ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- 利用新版本自带的Zookeeper搭建kafka集群
安装简要说明新版本的kafka自带有zookeeper,其实自带的zookeeper完全够用,本篇文章以记录使用自带zookeeper搭建kafka集群.1.关于kafka下载kafka下载页面:ht ...
- Centos7.5安装kafka集群
Tags: kafka Centos7.5安装kafka集群 Centos7.5安装kafka集群 主机环境 软件环境 主机规划 主机安装前准备 安装jdk1.8 安装zookeeper 安装kafk ...
- Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- 使用Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- zookeeper 安装及集群
一.zookeeper介绍 zookeeper是一个中间件,为分布式系统提供协调服务,可以为大数据服务,也可以为java服务. 分布式系统,很多计算机组成一个整体,作为一个整体一致对外并处理同一请求, ...
- zookeeper和Kafka集群安装配置
3个虚拟机,首先关闭防火墙,在进行下面操作 一.java环境 yum list java* yum -y install java-1.8.0-openjdk* 查看Java版本 Java -vers ...
随机推荐
- 文心一言 VS 讯飞星火 VS chatgpt (57)-- 算法导论6.4 1题
文心一言 VS 讯飞星火 VS chatgpt (57)-- 算法导论6.4 1题 一.参照图 6-4 的方法,说明 HEAPSORT 在数组 A=(5,13,2,25,7,17,20,8,4)上的操 ...
- 云图说 | 图解制品仓库服务CodeArts Artifact
本文分享自华为云社区<[云图说]第277期 图解制品仓库CodeArts Artifact>,作者:阅识风云. 制品仓库服务CodeArts Artifact用于存放源码编译生成的.可运行 ...
- 保姆级教程:带你体验华为云测试计划CodeArts TestPlan
摘要:华为云测试计划(CodeArts TestPlan)是面向软件开发者提供的一站式云端测试平台,覆盖测试管理.接口测试,融入DevOps敏捷测试理念,帮助您高效管理测试活动,保障产品高质量交付. ...
- 基于CREATE TYPE语法自定义新数据类型
摘要:介绍CREATE TYPE语法可以在数据库中定义一种新的数据类型. 本文分享自华为云社区<GaussDB(DWS)数据类型之自定义数据类型(复合类型)>,作者: 清道夫. CREAT ...
- 一文带你了解什么是GitOps
摘要:说起GitOps,可能很多朋友马上会联想到DevOps,那么GitOps和DevOps之间有什么关系.又有什么区别呢? 本文分享自华为云社区<浅谈GitOps>,作者: 敏捷的小智. ...
- Git hooks与自动化部署
好的 commit message 是至关重要的,如果随意编写 log,带来的后果可小可大,但是无论大小都影响了开发的效率和回朔的难度,所以有必要进行 log 规范化检查. 通过自定义的commit ...
- SAST + SCA: 结合使用安全升级
据 SAP 称,当今85%的安全攻击针对的是软件应用程序,因此一些列应用程序安全测试工具也应运而生.为了避免这些恶意攻击,企业通常使用应用程序安全测试工具来去缓解和解决安全风险,而不同的工具对应的使用 ...
- Centos7 怎么永久关闭防火墙
1.连接到centos主机,然后输入命令"systemctl status firewalld.service"并按下回车键. 2.然后在下方可以查看得到 " activ ...
- DataLeap的全链路智能监控报警实践(三): 系统实现
系统实现 整体架构 基线管理模块:负责基线创建.更新.删除等操作,管理基线元信息,包括保障任务,承诺时间,余量及报警配置等): 基线实例生成:系统每天定时触发生成基线实例,生成实例的同时根据保障任务, ...
- 火山引擎ByteHouse助力中国地震台网中心,快速构建一站式实时数仓
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 近日,中国地震台网中心与火山引擎达成合作,双方将围绕 ByteHouse 实时数仓展开合作. 中国地震台网中心为中国地震局 ...