[转帖]从SSTable到LSM-Tree之二
https://zhuanlan.zhihu.com/p/103968892
背景
LSM-Tree (Log Structured Merge Tree),日志结构合并树。它在 1996 年由论文《The Log-Structured Merge-Tree (LSM-Tree) 》[1]首次提出,但真正得到广泛应用是在 2006 年Google Bigtable 论文之后,论文中提到 Bigtable 使用的数据结构就是 LSM-Tree。
目前,LSM-Tree 已经被广泛应用于一些流行的的 Key-Value 型存储引擎中,如 Bigtable、Cassandra、HBase、RocksDB[2]、LevelDB、ScyllaDB[3]等。LSM 已经成为基于磁盘的 Key-Value 型存储引擎的标配。
为什么需要 LSM-Tree ?
我们知道,磁盘的顺序读写性能要比随机读写性能高2个数量级以上。日志结构指的就是日志形式的追加写(Append Only),它是顺序写。
LSM-Tree 相比于传统的 B+ 树存储引擎,具有更高的写入性能。通过把磁盘随机写转换为顺序写,来大幅提升写入性能。代价是,牺牲了部分读性能及写放大问题。这么说,并不是说 B+ 树不存在写放大,它实际也存在写放大问题。我们稍后再研究这个问题。
LSM-Tree 结构
我们先看看原始论文中描述的 LSM-Tree 结构,再看看实际存储引擎中的实现。
LSM-Tree 由两个或甚至更多的分层数据结构组成[1]。一种比较简单的两层 LSM-Tree 结构如下[1]:
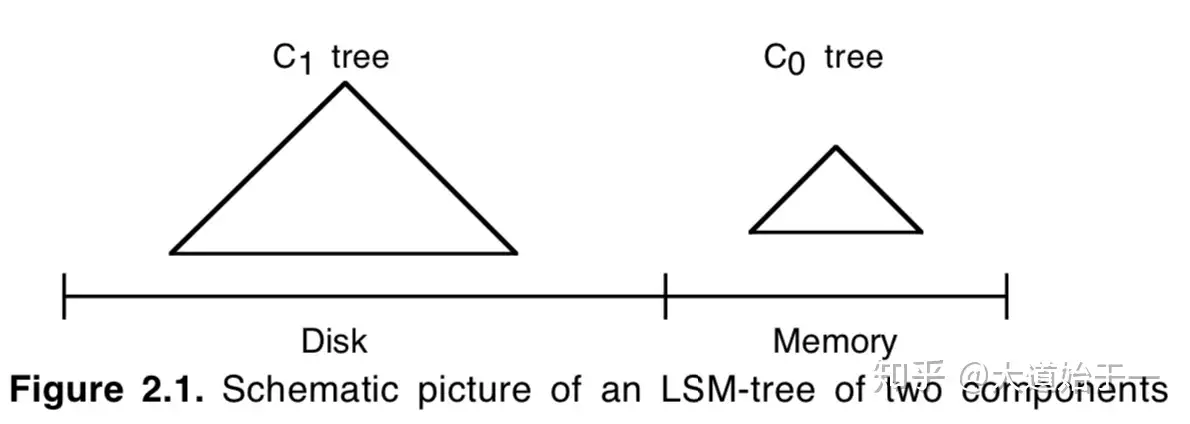
Two Level LSM-Tree
图中,C0 层常驻内存。 C1 层在磁盘上。C0 层保存最近更新的索引项,通常可以使用红黑树、跳表、B 树等实现。当插入操作导致 C0 的大小达到一定的阈值之后,它会与 C1 合并到磁盘上。LSM树的性能源于这样一个事实,即每个组件都根据其底层存储介质的特性进行了调优,并且使用一种类似于归并排序的算法,以滚动批次的方式有效地跨介质合并数据[1]。
多层 LSM-Tree 结构如下:
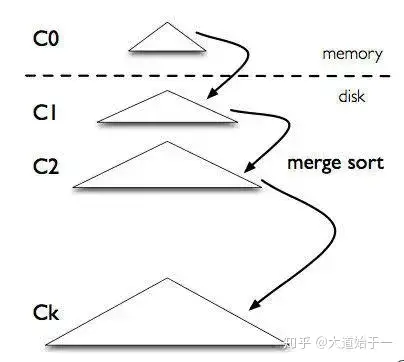
C0 层常驻内存,保存了所有最近写入的 Key-Value,这个内存结构是有序的,并且可以随时原地更新,同时支持随时查询。C1 ~ Ck 层都在磁盘上,每一层都是一个在 key 上有序的结构。
- 写流程
写请求首先被写入 WAL(Write Ahead Log)日志(通常用于故障恢复),再写入 C0,如果 C0 大小达到阈值,就会把 C0 层与 C1 层合并写入新的 new-C1,类似于归并算法,这个过程就是合并(Compaction)。合并的 new-C1 顺序写入磁盘。同理,C1 达到一定阈值之后,会与下层 C2 合并,依次逐层合并。合并过程可以异步进行,这样不用阻塞写操作。
- 读流程
由写入可以知道,最新的数据在 C0 层,最旧的数据在 Ck 层。查询指定的 key 时,会先查 C0 再查 C1,最后查 Ck。所以,LSM-Tree 对读不太友好,也就是存在读放大。
原始论文中,在磁盘上使用类 B 树来组织文件。但是实际系统,大多采用
来组织文件。
下面以经典的 LevelDB[4]为例,看一下 LSM-Tree 的实际实现。
LevelDB LSM 结构
LevelDB LSM-Tree 结构如下图所示。LSM-Tree 由三个数据结构组成:内存表分为 Memtable 和 ImmutableTable,磁盘上的 SSTable 文件。
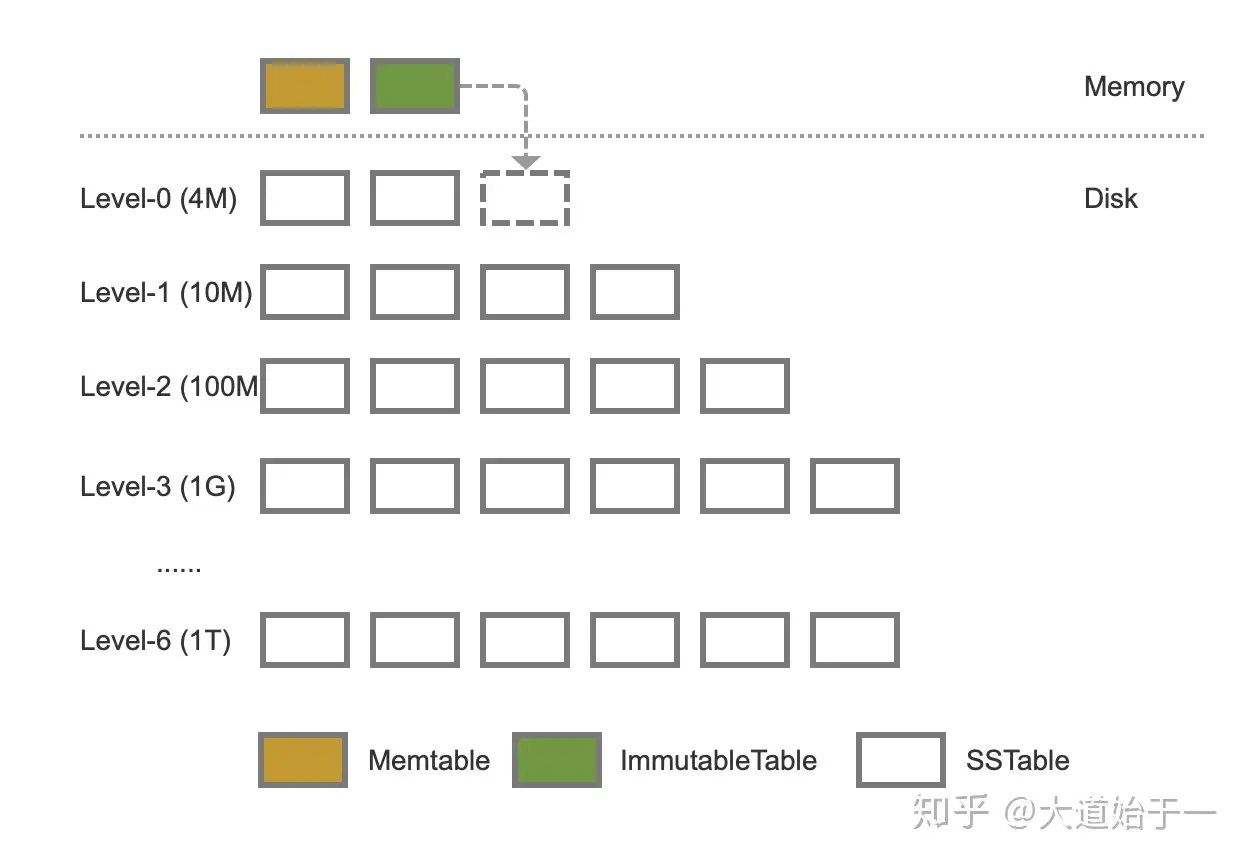
LevelDB-LSM
LevelDB LSM-Tree 性质[4]
内存表:
- 默认 4MB 左右内存块(可调,后面会说到)
- 存放有序 Key-Value
- 内存结构为跳跃表
- 数据先写入 Memtable,达到指定大小后,把它变成 ImmuableTable,之后异步 Compaction 落盘到 Level-0
SSTable 文件:
- SSTable 文件是层次结构,每层按 key range 分区存放在多个 SSTable 中
- Level-0 层 SSTable 的 key range 会存在重叠,其它层 key range 不重叠
- Level-i(i > 0)的大小呈指数增长,Level-i 层 SSTable 文件数量量级 10�
- Level-i 层中的每个 SSTable 最多与 Level-(i+1) 的 10 个 SSTable 存在交集
- 数据新鲜度:Memtable > ImmutableTable > Level-0 > Level-1 > Level-2 > ...
实际上,LevelDB 在写 Memtable 之前,会先写 log 文件(大小也为 4MB,它并不是无限增长),log 文件以日志追加(Append Only)的方式保存最近的更新,Memtable 相当于 log 的副本,log 文件可用于故障恢复。LevelDB 官方文档有几处混淆不清,比如 Level-0 层的 SSTable 文件并不是由 log 文件直接转换而来,而是由 Memtable 写入,不然如何保证 SSTable 文件中键的顺序。
SSTable 文件存储按 Key 排序的条目(Entry),每一个 Entry 是 Key-Value 对或指定 Key 的删除标记(Deletion Marker)。
特殊的 Level-0 层[4]
当 Level-0 文件个数超出指定阈值(默认 4 个,每个 1MB 大小)时,将所有 Level-0 的 SSTable 文件 与 Level-1 有交集的 SSTable 文件进行合并,然后生成新的 Level-1 SSTable 文件(每 2MB 生成一个新 SSTable)。
Level-0 层 SSTable 的 key range 会存在重叠。原因是,Level-0 的 SSTable 文件由 ImmutableTable 直接生成,但是不同的 ImmutableTable 之间没办法保证 key 不重叠。
合并(Compaction)
对于 Level-i (i > 0) 层,每一层的大小超过 10� MB(Level-1 层 10MB,Level-2层 100MB...)时,选择 Level-i 层中的一个 SSTable 文件与 Level-(i+1) 层所有存在交集的 SSTable 文件进行合并,生成新的 Level-(i+1) 层 SSTable 文件(有交集的文件不超过 10 个),合并完成之后,丢弃掉旧的 SSTable 文件(包括 Level-i 层和 Level-(i+1) 层的)。合并过程中,会处理删除和覆盖旧值的情况。
在合并过程中,有两种情况会触发生成一个新的 SSTable 文件:
- 第一种情况是新生成 SSTable 文件大小达到 2MB;
- 第二种情况就是新生成的 SSTable 与下一层存在重叠的 key range 的 SSTabe 个数超过了 10 个,这个约束是为了保证在合并过程中不至于读取太多的SSTable文件,以致于影响合并性能;
Compaction的时间性能[4]
对于合并性能,我们看下官方文档中对性能的描述。
对于进行 Level-0 合并时,最多从 Level-0 读取 4 个 1MB 大小的文件,以及最坏情况下从 Level-1 层读取 10MB 大小。那么读是 14MB,写也是 14MB。
对于 Level-i (i > 0) 合并时,会从 Level-i 层选择一个 2MB 大小的文件,以及最坏情况下从Level-(i+1) 层选择 12 个 2MB大小的文件,其中 10 个是因为上下层最多重叠10个文件,额外2个文件是由于上下两层文件边界往往不对齐导致的。那么读是 26MB,写也是26MB。
假设磁盘 IO 速率为 100MB/s (现代驱动器的大致范围),最坏的情况下合并成本大约为 0.5s。如果限制一下写入磁盘速率到 10%,那么合并可能需要 5s。又或者用户以 10MB/s 的速率写入 Memtable,那么 Level-0 每秒需要大约 50 个 1MB的文件,Level-1 则需要生成 5 个(5 x 10MB)文件,这势必会大大增加 Compaction 的代价。
如果我们将后台写入限制为很小的值,比如100MB/s速度的10%,那么压缩可能需要5秒。如果用户以10MB/s的速度写入,我们可能会构建许多0级文件(~50来容纳5*10MB)。由于每次读取时合并更多文件的开销,这可能会显著增加读取的成本。
LSM-Tree 虽然写入性能很好,但也存在一些问题。
写放大
Write Amplification (WA),写放大是指实际写的数据量大于用户需要的数据量。写放大是由于合并引起的。
写放大是 LevelDB 的硬伤,RocksDB 通过把参数 10 变成动态可调来缓解写放大问题。
写放大会降低 Flash 磁盘(SSD)的寿命。
读放大
Read Amplification (RA),读放是指实际读的数据量大于用户需要的数据量。LevelDB 查询数据时,会按照数据新鲜读排序,依次从 Memtable > ImmutableTable > L0 > L1 > ...中查询,尤其是查询的 key 不存在时,会导致每次都会查询到最后一层。一般结合布隆过滤器 (bool filter) 来降低读放大问题。
空间放大(Space Amplification)
所有的写入都是顺序写 (Append-Only) 的,不是原地更新 (in-place update) ,所以过期数据不会马上被清理掉。LSM-Tree 是通过合并来减少空间放大,但是引入了写放大问题。
由于本人的理解能力有限,如理解有误,请大家多多指正。
参考
- ^abcdThe Log-Structured Merge-Tree (LSM-Tree)
- ^A Tutorial of RocksDB SST formats https://github.com/facebook/rocksdb/wiki/A-Tutorial-of-RocksDB-SST-formats
- ^Scylla SSTable Format https://docs.scylladb.com/architecture/sstable/
- ^abcdLevelDB https://github.com/google/leveldb
[转帖]从SSTable到LSM-Tree之二的更多相关文章
- 数据映射-LSM Tree和SSTable
Coming from http://blog.sina.com.cn/s/blog_693f08470101njc7.html 今天来聊聊lsm tree,它的全称是log structured m ...
- LSM Tree 学习笔记——本质是将随机的写放在内存里形成有序的小memtable,然后定期合并成大的table flush到磁盘
The Sorted String Table (SSTable) is one of the most popular outputs for storing, processing, and ex ...
- LSM Tree 学习笔记——MemTable通常用 SkipList 来实现
最近发现很多数据库都使用了 LSM Tree 的存储模型,包括 LevelDB,HBase,Google BigTable,Cassandra,InfluxDB 等.之前还没有留意这么设计的原因,最近 ...
- Log-Structured Merge Tree (LSM Tree)
一种树,适合于写多读少的场景.主要是利用了延迟更新.批量写.顺序写磁盘(磁盘sequence access比random access快). 背景 回顾数据存储的两个“极端”发展方向 加快读:加索引( ...
- 【万字长文】使用 LSM Tree 思想实现一个 KV 数据库
目录 设计思路 何为 LSM-Treee 参考资料 整体结构 内存表 WAL SSTable 的结构 SSTable 元素和索引的结构 SSTable Tree 内存中的 SSTable 数据查找过程 ...
- LSM Tree存储组织结构介绍
LSM Tree(Log Structured Merge Trees)数据组织方式被应用于多种数据库,如LevelDB.HBase.Cassandra等,下面我们从为什么使用LSM tree.LSM ...
- LSM Tree解析
引言 众所周知传统磁盘I/O是比较耗性能的,优化系统性能往往需要和磁盘I/O打交道,而磁盘I/O产生的时延主要由下面3个因素决定: 寻道时间(将磁盘臂移动到适当的柱面上所需要的时间,寻道时移动到相邻柱 ...
- [CareerCup] 4.5 Validate Binary Search Tree 验证二叉搜索树
4.5 Implement a function to check if a binary tree is a binary search tree. LeetCode上的原题,请参见我之前的博客Va ...
- [LeetCode] Verify Preorder Sequence in Binary Search Tree 验证二叉搜索树的先序序列
Given an array of numbers, verify whether it is the correct preorder traversal sequence of a binary ...
- [LeetCode] Binary Search Tree Iterator 二叉搜索树迭代器
Implement an iterator over a binary search tree (BST). Your iterator will be initialized with the ro ...
随机推荐
- 文心一言 VS 讯飞星火 VS chatgpt (47)-- 算法导论6.1 5题
五.一个已排好序的数组是一个最小堆吗? 文心一言: 一个已排好序的数组不一定是一个最小堆.最小堆是一种特殊的二叉树,它满足以下性质:对于任意节点 x,其父节点 y 的值都小于等于 x 的值.而一个已排 ...
- flutter常用的音乐播放器库
audioplayers: 优势:audioplayers 是一个简单易用的音乐播放器库,支持主流平台(Android.iOS)并提供了丰富的功能,比如播放.暂停.快进.音量控制等. 缺点:audio ...
- 你应该知道的数仓安全——默认权限实现共享schema
摘要: 一种典型客户场景是一些用户是数据的生产方,需要在schema中创建表并写入数据:而另一些用户是数据的消费方,读取schema中的数据做分析.使用Alter default privilege语 ...
- 教你如何优雅的改写“if-else”
摘要:这些场景,你是怎么写的代码? if-else,这是个再正常不过的coding习惯,当我们代码量小的时候用来做条件判断是再简单不过的了.但对于优秀程序员来说,这却不是好代码. 不信你往下看- 1. ...
- 【教程】app备案流程简单三部曲即可完成
[教程]app备案流程简单三部曲即可完成 APP备案流程包括以下步骤: 1. 开发者实名认证:在提交备案申请之前,开发者需要通过移动应用开发平台进行实名认证.这个步骤需要提供身份证号码.姓名.联系 ...
- 2023 年如何将您的应用提交到 App Store
您夜以继日地工作来创建您的梦想应用程序.最后,是时候向全世界宣布您的应用程序了.但不知道如何将您的应用提交到 App Store? 为您的商店获取现成的移动应用程序 将应用程序提交到 App Stor ...
- 从“概念”到“应用”,字节跳动基于 DataLeap 的 DataOps 实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,火山引擎数智平台 VeDI Meetup「超话数据」在深圳举办,来自火山引擎的产品专家分享了字节跳动基于 D ...
- 火山引擎DataLeap的Catalog系统搜索实践 (二):整体架构
整体架构 火山引擎DataLeap的Catalog搜索系统使用了开源的搜索引擎Elasticsearch进行基础的文档检索(Recall阶段),因此各种资产元数据会被存放到Elasticsearch中 ...
- HanLP — HMM隐马尔可夫模型 -- 语料库
隐马尔可可夫模型(Hidden Markov Model,HMM)是统计模型,用于描述一个含有隐含未知参数的马尔可夫过程. HMM由初始概率分布.状态转移概率分布和观测概率分布确定. BMES =&g ...
- Jenkins Pipeline SSH Publisher 环境变量、参数引用 要用双引号
Jenkins Pipeline SSH Publisher 环境变量.参数引用 要用双引号 在 Pipeline 脚本中,如果要使用变量,就必须使用 " 双引号 pipeline { ag ...