[转帖]058、集群优化之PD
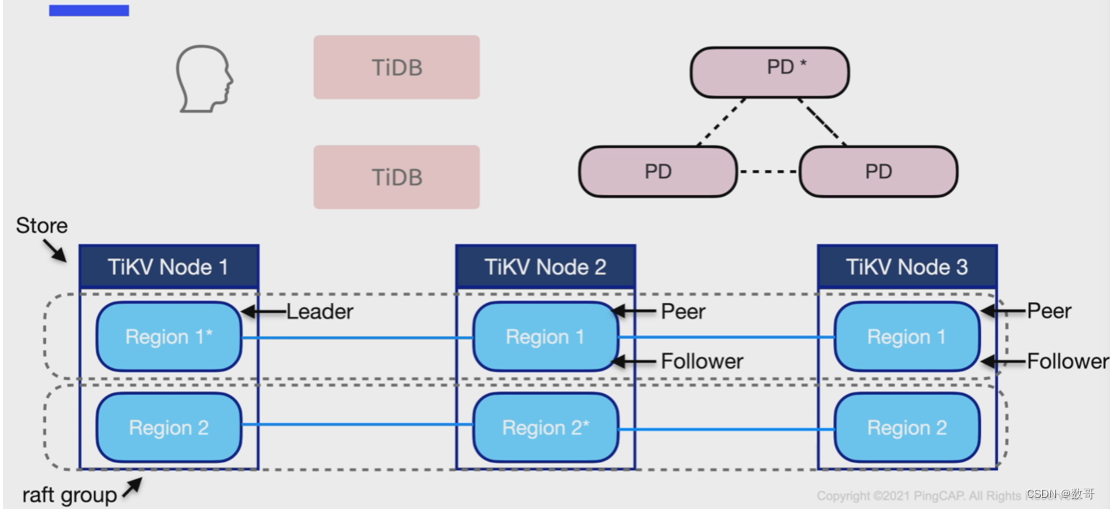
PD调度基本概念
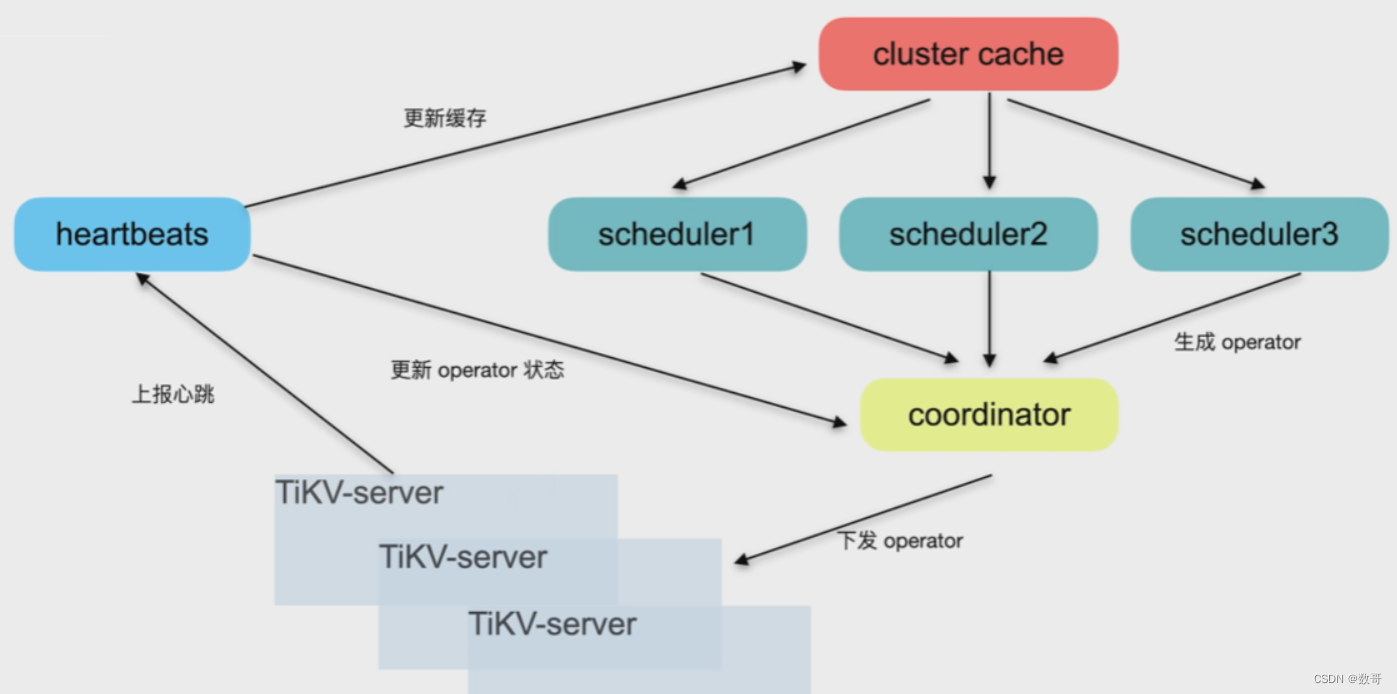
调度流程
调度中还有这还缺来了merge,例如合并空region。
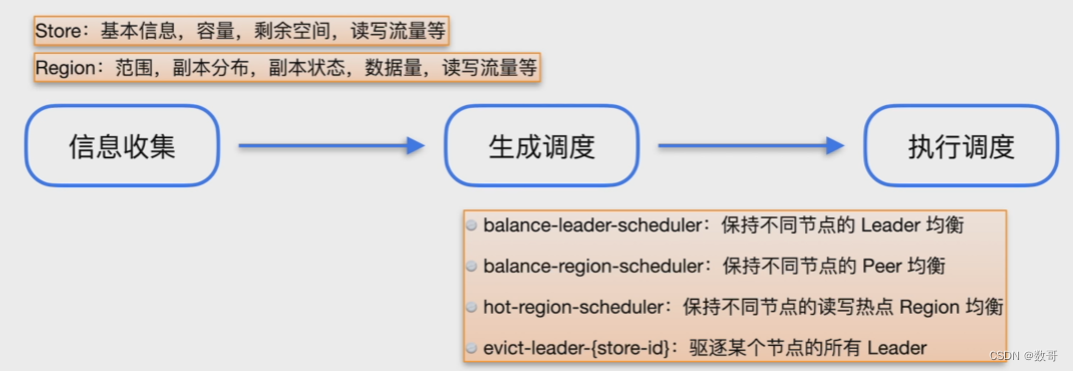
store: 基本信息,容量,剩余空间,读写流量等
region: 范围,副本分布,副本状态,数据量,读写流量等
- 相关调度说明
- balance-leader-scheduler: 保持不同节点的leader均衡
- balance-region-scheduler: 保持不同节点的Peer均衡
- hot-region-scheduler: 保持不同节点的读写热点Region均衡
- evict-leader-{store-id}: 驱逐某个节点的所有leader
调度limit参数
- 调度当中的生产者相关参数
| 参数 | 默认值 | 说明 |
|---|---|---|
| region-schedule-limit | 2048 | 同时进行Region调度的任务个数 |
| leader-schedule-limit | 4 | 同时进行leader调度的任务个数 |
| replica-schedule-limit | 64 | 同时进行replica调度的任务个数 |
| merge-schedule-limit | 8 | 同时进行region merge调度的任务,设置为0则是关闭这个调度 |
| hot-region-schedule-limt | 4 | 控制同时进行的hot Region任务。 |
| patrol-region-interval | 100ms | 控制region的间隔,默认100ms,通常不需要调整 |
| tolerant-size-ratio | 0 | 控制balance region缓冲区大小,默认是0,表示自动调整,不需要修改 |
| region_weight leader_weight |
1 | PD计算region和leader分数之后,会除以weight得到最终的region和leader分值,weight默认为1,不需要修改 |
- 调度当中的消费者相关参数-消费限速(store limit)
- 定义: 限制单个store的消费速度
- 方式: pd-ctl -u ip:port store limit <id> <value>
- 区别: store limit限制的主要是operator的消费速度,而其他的limit主要是限制operator的产生速度
存储空间阈值参数
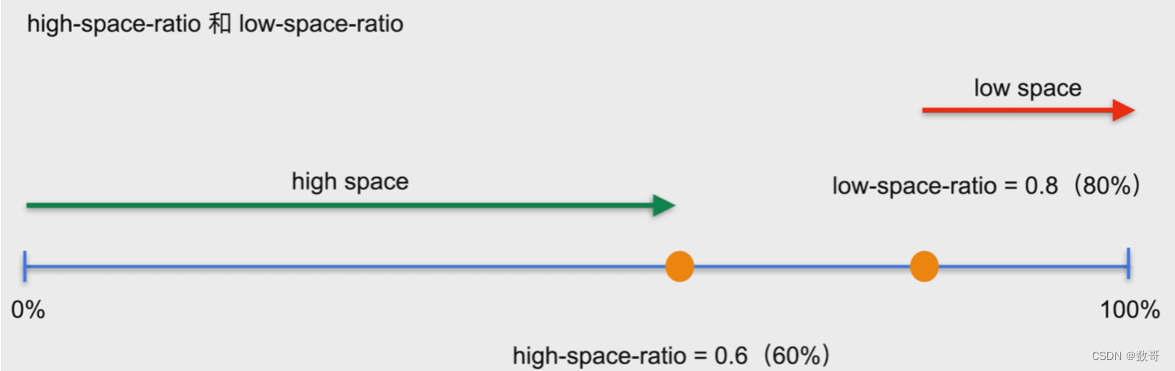
pd 会为每个TiKV打分(例如leader多的分高),如果分多,则可能将leader允给其他的节点。 但有个前提,如果分少的节点基本没空间了,则分多的节点给它分数就不太合适了。此时通过high-space-ratio: 60% 这个参数控制当节点存储的空间小于这个值的时候,则不考虑这个空间因素了。或者low-space-ratio:80%,当节点存储空间大于这个值的时候,就会优先考虑空间因素了。
常见问题的处理
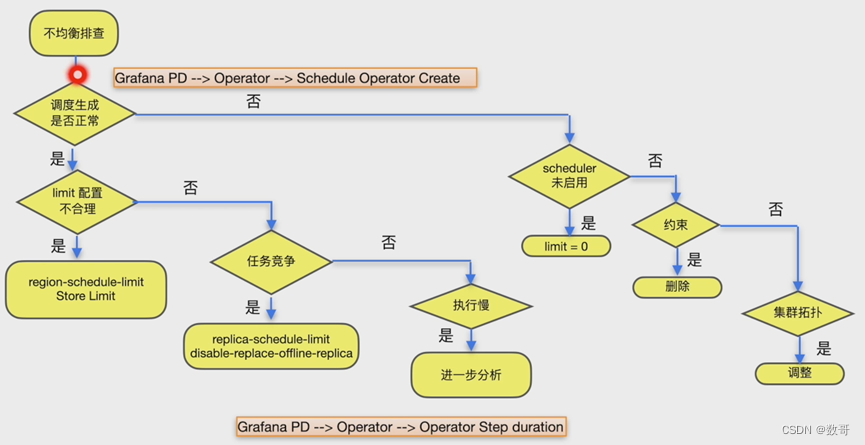
扩容后balance region 调度速度慢
Grafana PD -> Operator -> Schedule Operator Create
Grafana PD -> Operator -> Operator Step Duration
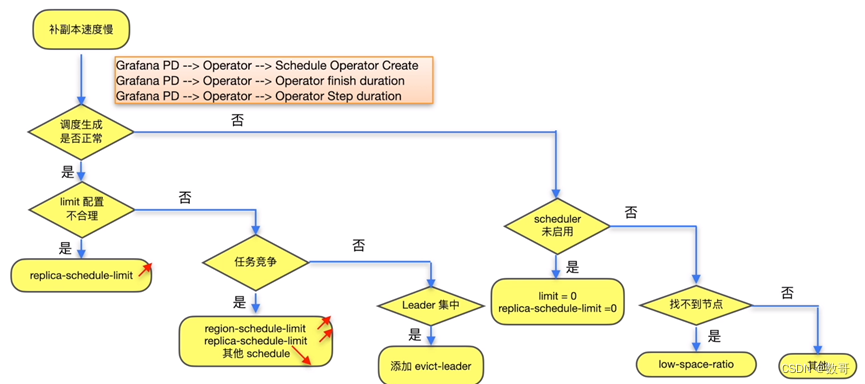
store节点故障后补副本的速度慢
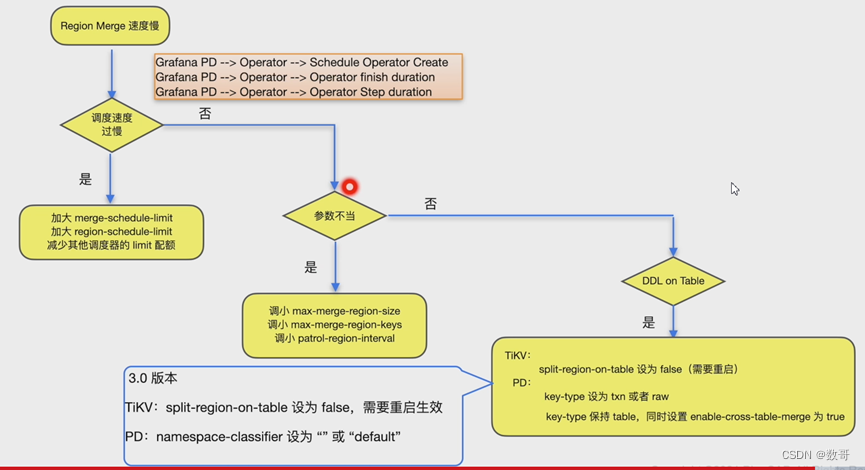
Region merge速度慢
pd-ctl
- 查看并修改调度参数
config show -- 显示当前调度相关参数
config set <key> <value> -- 修改相关参数
store limit <store_id> <value> --限制单个store的调度速度
- 1
- 2
- 3
- 手动添加Operator
operator show [admin|leader|region] --展示当前全局或某类的调度任务
operator add --人工添加一些调度任务实现期望目标,例如
operator add add-peer <region_id> <store_id>
operator add remove-peer <region_id> <store_id>
operator add transfer-leader <region_id> <store_id>
- 1
- 2
- 3
- 4
- 5
- 详细使用方法
https://docs.pingcap.com/zh/tidb/v6.5/pd-control
- 1
[转帖]058、集群优化之PD的更多相关文章
- HDFS集群优化篇
HDFS集群优化篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.操作系统级别优化 1>.优化文件系统(推荐使用EXT4和XFS文件系统,相比较而言,更推荐后者,因为XF ...
- Kafka集群优化篇-调整broker的堆内存(heap)案例实操
Kafka集群优化篇-调整broker的堆内存(heap)案例实操 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看kafka集群的broker的堆内存使用情况 1>. ...
- Elasticsearch 集群优化-尽可能全面详细
Elasticsearch 集群优化-转载参考1 基本配置 基本配置,5台配置为 24C 125G 17T 的主机,每台主机上搭建了一个elasticsearch节点. 采用的elasticsearc ...
- 第九章:Elasticsearch集群优化及相关节点配置说明
Linux系统调优: Linux调整打开文件数(重新启动生效) 在/etc/security/limits.conf在文件中增加: * soft nofile 8192 * hard nofile 2 ...
- PaaS容器集群优化之路
1. 性能优化面对的挑战 以下是整个PaaS平台的架构 其中主要包括这些子系统: 微服务治理框架:为应用提供自动注册.发现.治理.隔离.调用分析等一系列分布式/微服务治理能力,屏蔽分布式系统的复杂度. ...
- 大流量大负载的Kafka集群优化实战
前言背景 算法优化改版有大需求要上线,在线特征dump数据逐步放量,最终达到现有Kafka集群5倍的流量,预计峰值达到万兆网卡80%左右(集群有几十个节点,网卡峰值流出流量800MB左右/sec.写入 ...
- spark 集群优化
只有满怀自信的人,能在任何地方都怀有自信,沉浸在生活中,并认识自己的意志. 前言 最近公司有一个生产的小集群,专门用于运行spark作业.但是偶尔会因为nn或dn压力过大而导致作业checkpoint ...
- Java集群优化——dubbo+zookeeper构建高可用分布式集群
不久前,我们讨论过Nginx+tomcat组成的集群,这已经是非常灵活的集群技术,但是当我们的系统遇到更大的瓶颈,全部应用的单点服务器已经不能满足我们的需求,这时,我们要考虑另外一种,我们熟悉的内容, ...
- Java集群优化——使用Dubbo对单一应用服务化改造
之前,我们讨论过Nginx+tomcat组成的集群,这已经是非常灵活的集群技术,但是当我们的系统遇到更大的瓶颈,全部应用的单点服务器已经不能满足我们的需求,这时,我们要考虑另外一种,我们熟悉的内容,就 ...
- [转帖]K8s集群安装--最新版 Kubernetes 1.14.1
K8s集群安装--最新版 Kubernetes 1.14.1 http://www.cnblogs.com/jieky/p/10679998.html 原作者写的比较简单 大略流程和跳转的多一些 改天 ...
随机推荐
- MySQL进阶篇:详解索引结构
2.2 MySQL进阶篇:第二章_二.二_索引结构 2.2.1 概述 MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的索引结构,主要包含以下几种: 索引结构 描述 B+Tree索引 最常见 ...
- 【玩转鲲鹏DevKit系列】如何快速迁移软件包?
本文分享自华为云社区<[玩转鲲鹏DevKit系列]如何快速迁移软件包?>,作者: 华为云社区精选 . 软件包含各种不同格式的文件,如RPM包通常包含二进制文件.SO 库文件.JAR包.配置 ...
- AI推理实践丨多路极致性能目标检测最佳实践设计解密
摘要:基于CANN的多路极致性能目标检测最佳实践设计解密. 本文分享自华为云社区<基于CANN的AI推理最佳实践丨多路极致性能目标检测应用设计解密>,作者: 昇腾CANN . 当前人工智能 ...
- 学会这5种JS函数继承方式,前端面试你至少成功50%
摘要:函数继承是在JS里比较基础也是比较重要的一部分,而且也是面试中常常要问到的.下面带你快速了解JS中有哪几种是经常出现且必须掌握的继承方式.掌握下面的内容面试也差不多没问题啦~ 本文分享自华为云社 ...
- 云小课 | 使用ROMA API,API管理从此不用愁!
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:ROMA API致 ...
- why哥这里有一道Dubbo高频面试题,请查收。
这是why的第 64 篇原创文章 荒腔走板 大家好,我是 why,欢迎来到我连续周更优质原创文章的第 64 篇.老规矩,先荒腔走板聊聊其他的. 上面这图是我之前拼的一个拼图. 我经常玩拼图,我大概拼了 ...
- Caused by: java.lang.ClassNotFoundException: javax.servlet.Filter
Caused by: java.lang.NoClassDefFoundError: javax/servlet/Filter at java.lang.Class.getDeclaredMethod ...
- Nacos 1.2.1 集群搭建(三) Nginx 配置 集群
配置 Nginx 可以把.conf 文件拉到本地,配置好再传上去 #gzip on; upstream cluster{ server 192.168.0.113:8848; server 192.1 ...
- Spring Boot Admin 配置应用
Spring Boot Admin 监控SpringBoot 服务的运行情况 https://codecentric.github.io/spring-boot-admin/2.3.0/#spring ...
- 在 SDXL 上用 T2I-Adapter 实现高效可控的文生图
T2I-Adapter 是一种高效的即插即用模型,其能对冻结的预训练大型文生图模型提供额外引导.T2I-Adapter 将 T2I 模型中的内部知识与外部控制信号结合起来.我们可以根据不同的情况训练各 ...