[转帖]Split Region 使用文档
https://docs.pingcap.com/zh/tidb/stable/sql-statement-split-region
在 TiDB 中新建一个表后,默认会单独切分出 1 个 Region 来存储这个表的数据,这个默认行为由配置文件中的 split-table 控制。当这个 Region 中的数据超过默认 Region 大小限制后,这个 Region 会开始分裂成 2 个 Region。
上述情况中,如果在新建的表上发生大批量写入,则会造成热点,因为开始只有一个 Region,所有的写请求都发生在该 Region 所在的那台 TiKV 上。
为解决上述场景中的热点问题,TiDB 引入了预切分 Region 的功能,即可以根据指定的参数,预先为某个表切分出多个 Region,并打散到各个 TiKV 上去。
语法图
SplitRegionStmt:

SplitSyntaxOption:

TableName:
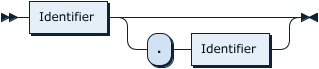
PartitionNameListOpt:
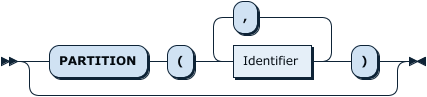
SplitOption:

RowValue:

Int64Num:

Split Region 的使用
Split Region 有 2 种不同的语法,具体如下:
均匀切分的语法:
SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num
BETWEEN lower_value AND upper_value REGIONS region_num语法是通过指定数据的上、下边界和 Region 数量,然后在上、下边界之间均匀切分出region_num个 Region。不均匀切分的语法:
SPLIT TABLE table_name [INDEX index_name] BY (value_list) [, (value_list)] ...
BY value_list…语法将手动指定一系列的点,然后根据这些指定的点切分 Region,适用于数据不均匀分布的场景。
SPLIT 语句的返回结果示例如下:
+--------------------+----------------------+| TOTAL_SPLIT_REGION | SCATTER_FINISH_RATIO |+--------------------+----------------------+| 4 | 1.0 |+--------------------+----------------------+
TOTAL_SPLIT_REGION:表示新增预切分的 Region 数量。SCATTER_FINISH_RATIO:表示新增预切分 Region 中,打散完成的比率。如1.0表示全部完成。0.5表示只有一半的 Region 已经打散完成,剩下的还在打散过程中。
注意:
以下会话变量会影响
SPLIT语句的行为,需要特别注意:
tidb_wait_split_region_finish:打散 Region 的时间可能较长,由 PD 调度以及 TiKV 的负载情况所决定。这个变量用来设置在执行SPLIT REGION语句时,是否同步等待所有 Region 都打散完成后再返回结果给客户端。默认1代表等待打散完成后再返回结果。0代表不等待 Region 打散完成就返回结果。tidb_wait_split_region_timeout:这个变量用来设置SPLIT REGION语句的执行超时时间,单位是秒,默认值是 300 秒,如果超时还未完成Split操作,就返回一个超时错误。
Split Table Region
表中行数据的 key 由 table_id 和 row_id 编码组成,格式如下:
t[table_id]_r[row_id]
例如,当 table_id 是 22,row_id 是 11 时:
t22_r11
同一表中行数据的 table_id 是一样的,但 row_id 肯定不一样,所以可以根据 row_id 来切分 Region。
均匀切分
由于 row_id 是整数,所以根据指定的 lower_value、upper_value 以及 region_num,可以推算出需要切分的 key。TiDB 先计算 step (step = (upper_value - lower_value)/region_num),然后在 lower_value 和 upper_value 之间每隔 step 区间切一次,最终切出 region_num 个 Region。
例如,对于表 t,如果想要从 minInt64~maxInt64 之间均匀切割出 16 个 Region,可以用以下语句:
SPLIT TABLE t BETWEEN (-9223372036854775808) AND (9223372036854775807) REGIONS 16;
该语句会把表 t 从 minInt64 到 maxInt64 之间均匀切割出 16 个 Region。如果已知主键的范围没有这么大,比如只会在 0~1000000000 之间,那可以用 0 和 1000000000 分别代替上面的 minInt64 和 maxInt64 来切分 Region。
SPLIT TABLE t BETWEEN (0) AND (1000000000) REGIONS 16;
不均匀切分
如果已知数据不是均匀分布的,比如想要 -inf ~ 10000 切一个 Region,10000 ~ 90000 切一个 Region,90000 ~ +inf 切一个 Region,可以通过手动指定点来切分 Region,示例如下:
SPLIT TABLE t BY (10000), (90000);
Split Index Region
表中索引数据的 key 由 table_id、index_id 以及索引列的值编码组成,格式如下:
t[table_id]_i[index_id][index_value]
例如,当 table_id 是 22,index_id 是 5,index_value 是 abc 时:
t22_i5abc
同一表中同一索引数据的 table_id 和 index_id 是一样的,所以要根据 index_value 切分索引 Region。
均匀切分
索引均匀切分与行数据均匀切分的原理一样,只是计算 step 的值较为复杂,因为 index_value 可能不是整数。
upper 和 lower 的值会先编码成 byte 数组,去掉 lower 和 upper byte 数组的最长公共前缀后,从 lower 和 upper 各取前 8 字节转成 uint64,再计算 step = (upper - lower)/num。计算出 step 后再将 step 编码成 byte 数组,添加到之前 upper和 lower的最长公共前缀后面组成一个 key 后去做切分。示例如下:
如果索引 idx 的列也是整数类型,可以用如下 SQL 语句切分索引数据:
SPLIT TABLE t INDEX idx BETWEEN (-9223372036854775808) AND (9223372036854775807) REGIONS 16;
该语句会把表 t 中 idx 索引数据 Region 从 minInt64 到 maxInt64 之间均匀切割出 16 个 Region。
如果索引 idx1 的列是 varchar 类型,希望根据前缀字母来切分索引数据:
SPLIT TABLE t INDEX idx1 BETWEEN ("a") AND ("z") REGIONS 25;
该语句会把表 t 中 idx1 索引数据的 Region 从 a~z 切成 25 个 Region,region1 的范围是 [minIndexValue, b),region2 的范围是 [b, c),……,region25 的范围是 [y, maxIndexValue)。对于 idx1 索引以 a 为前缀的数据都会写到 region1,以 b 为前缀的索引数据都会写到 region2,以此类推。
上面的切分方法,以 y 和 z 前缀的索引数据都会写到 region 25, 因为 z 并不是一个上界,真正的上界是 z 在 ASCII 码中的下一位 {,所以更准确的切分方法如下:
SPLIT TABLE t INDEX idx1 BETWEEN ("a") AND ("{") REGIONS 26;
该语句会把表 t 中 idx1 索引数据的 Region 从 a~{ 切成 26 个 Region,region1 的范围是 [minIndexValue, b),region2 的范围是 [b, c),……,region25 的范围是 [y,z),region26 的范围是 [z, maxIndexValue)。
如果索引 idx2 的列是 timestamp/datetime 等时间类型,希望根据时间区间,按年为间隔切分索引数据,示例如下:
SPLIT TABLE t INDEX idx2 BETWEEN ("2010-01-01 00:00:00") AND ("2020-01-01 00:00:00") REGIONS 10;
该语句会把表 t 中 idx2 的索引数据 Region 从 2010-01-01 00:00:00 到 2020-01-01 00:00:00 切成 10 个 Region。region1 的范围是从 [minIndexValue, 2011-01-01 00:00:00),region2 的范围是 [2011-01-01 00:00:00, 2012-01-01 00:00:00)……
如果希望按照天为间隔切分索引,示例如下:
SPLIT TABLE t INDEX idx2 BETWEEN ("2020-06-01 00:00:00") AND ("2020-07-01 00:00:00") REGIONS 30;
该语句会将表 t 中 idx2 索引位于 2020 年 6 月份的数据按天为间隔切分成 30 个 Region。
其他索引列类型的切分方法也是类似的。
对于联合索引的数据 Region 切分,唯一不同的是可以指定多个 column 的值。
比如索引 idx3 (a, b) 包含 2 列,a 是 timestamp,b 是 int。如果只想根据 a 列做时间范围的切分,可以用切分单列时间索引的 SQL 语句来切分,lower_value 和 upper_velue 中不指定 b 列的值即可。
SPLIT TABLE t INDEX idx3 BETWEEN ("2010-01-01 00:00:00") AND ("2020-01-01 00:00:00") REGIONS 10;
如果想在时间相同的情况下,根据 b 列再做一次切分,在切分时指定 b 列的值即可。
SPLIT TABLE t INDEX idx3 BETWEEN ("2010-01-01 00:00:00", "a") AND ("2010-01-01 00:00:00", "z") REGIONS 10;
该语句在 a 列时间前缀相同的情况下,根据 b 列的值从 a~z 切了 10 个 Region。如果指定的 a 列的值不相同,那么可能不会用到 b 列的值。
如果表的主键为非聚簇索引 NONCLUSTERED,切分 Region 时需要用反引号 ` 来转义 PRIMARY 关键字。例如:
SPLIT TABLE t INDEX `PRIMARY` BETWEEN (-9223372036854775808) AND (9223372036854775807) REGIONS 16;
不均匀切分
索引数据也可以根据用户指定的索引值来做切分。
假如有 idx4 (a,b),其中 a 列是 varchar 类型,b 列是 timestamp 类型。
SPLIT TABLE t1 INDEX idx4 BY ("a", "2000-01-01 00:00:01"), ("b", "2019-04-17 14:26:19"), ("c", "");
该语句指定了 3 个值,会切分出 4 个 Region,每个 Region 的范围如下。
region1 [ minIndexValue , ("a", "2000-01-01 00:00:01"))region2 [("a", "2000-01-01 00:00:01") , ("b", "2019-04-17 14:26:19"))region3 [("b", "2019-04-17 14:26:19") , ("c", "") )region4 [("c", "") , maxIndexValue )
Split 分区表的 Region
预切分分区表的 Region 在使用上和普通表一样,差别是会为每一个 partition 都做相同的切分。
均匀切分的语法如下:
SPLIT [PARTITION] TABLE t [PARTITION] [(partition_name_list...)] [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num
不均匀切分的语法如下:
SPLIT [PARTITION] TABLE table_name [PARTITION (partition_name_list...)] [INDEX index_name] BY (value_list) [, (value_list)] ...
Split 分区表的 Region 示例
首先创建一个分区表。如果你要建一个 Hash 分区表,分成 2 个 partition,示例语句如下:
create table t (a int,b int,index idx(a)) partition by hash(a) partitions 2;
此时建完表后会为每个 partition 都单独 split 一个 Region,用
SHOW TABLE REGIONS语法查看该表的 Region 如下:show table t regions;
+-----------+-----------+---------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |+-----------+-----------+---------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+| 1978 | t_1400_ | t_1401_ | 1979 | 4 | 1979, 1980, 1981 | 0 | 0 | 0 | 1 | 0 || 6 | t_1401_ | | 17 | 4 | 17, 18, 21 | 0 | 223 | 0 | 1 | 0 |+-----------+-----------+---------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+
用
SPLIT语法为每个 partition 切分 Region。如果你要将各个 partition 的 [0,10000] 范围内的数据切分成 4 个 Region,示例语句如下:split partition table t between (0) and (10000) regions 4;
其中,
0和10000分别代表你想要打散的热点数据对应的上、下边界的row_id。注意:
此示例仅适用于数据热点均匀分布的场景。如果热点数据在你指定的数据范围内是不均匀分布的,请参考 Split 分区表的 Region 中不均匀切分的语法。
用
SHOW TABLE REGIONS语法查看该表的 Region。如下会发现该表现在一共有 10 个 Region,每个 partition 分别有 5 个 Region,其中 4 个 Region 是表的行数据,1 个 Region 是表的索引数据。show table t regions;
+-----------+---------------+---------------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |+-----------+---------------+---------------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+| 1998 | t_1400_r | t_1400_r_2500 | 2001 | 5 | 2000, 2001, 2015 | 0 | 132 | 0 | 1 | 0 || 2006 | t_1400_r_2500 | t_1400_r_5000 | 2016 | 1 | 2007, 2016, 2017 | 0 | 35 | 0 | 1 | 0 || 2010 | t_1400_r_5000 | t_1400_r_7500 | 2012 | 2 | 2011, 2012, 2013 | 0 | 35 | 0 | 1 | 0 || 1978 | t_1400_r_7500 | t_1401_ | 1979 | 4 | 1979, 1980, 1981 | 0 | 621 | 0 | 1 | 0 || 1982 | t_1400_ | t_1400_r | 2014 | 3 | 1983, 1984, 2014 | 0 | 35 | 0 | 1 | 0 || 1990 | t_1401_r | t_1401_r_2500 | 1992 | 2 | 1991, 1992, 2020 | 0 | 120 | 0 | 1 | 0 || 1994 | t_1401_r_2500 | t_1401_r_5000 | 1997 | 5 | 1996, 1997, 2021 | 0 | 129 | 0 | 1 | 0 || 2002 | t_1401_r_5000 | t_1401_r_7500 | 2003 | 4 | 2003, 2023, 2022 | 0 | 141 | 0 | 1 | 0 || 6 | t_1401_r_7500 | | 17 | 4 | 17, 18, 21 | 0 | 601 | 0 | 1 | 0 || 1986 | t_1401_ | t_1401_r | 1989 | 5 | 1989, 2018, 2019 | 0 | 123 | 0 | 1 | 0 |+-----------+---------------+---------------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+
如果你要给每个分区的索引切分 Region,如将索引
idx的 [1000,10000] 范围切分成 2 个 Region,示例语句如下:split partition table t index idx between (1000) and (10000) regions 2;
Split 单个分区的 Region 示例
可以单独指定要切分的 partition,示例如下:
首先创建一个分区表。如果你要建一个 Range 分区表,分成 3 个 partition,示例语句如下:
create table t ( a int, b int, index idx(b)) partition by range( a ) (partition p1 values less than (10000),partition p2 values less than (20000),partition p3 values less than (MAXVALUE) );
如果你要将
p1分区的 [0,10000] 范围内的数据预切分 2 个 Region,示例语句如下:split partition table t partition (p1) between (0) and (10000) regions 2;
如果你要将
p2分区的 [10000,20000] 范围内的数据预切分 2 个 Region,示例语句如下:split partition table t partition (p2) between (10000) and (20000) regions 2;
用
SHOW TABLE REGIONS语法查看该表的 Region 如下:show table t regions;
+-----------+----------------+----------------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |+-----------+----------------+----------------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+| 2040 | t_1406_ | t_1406_r_5000 | 2045 | 3 | 2043, 2045, 2044 | 0 | 0 | 0 | 1 | 0 || 2032 | t_1406_r_5000 | t_1407_ | 2033 | 4 | 2033, 2034, 2035 | 0 | 0 | 0 | 1 | 0 || 2046 | t_1407_ | t_1407_r_15000 | 2048 | 2 | 2047, 2048, 2050 | 0 | 35 | 0 | 1 | 0 || 2036 | t_1407_r_15000 | t_1408_ | 2037 | 4 | 2037, 2038, 2039 | 0 | 0 | 0 | 1 | 0 || 6 | t_1408_ | | 17 | 4 | 17, 18, 21 | 0 | 214 | 0 | 1 | 0 |+-----------+----------------+----------------+-----------+-----------------+------------------+------------+---------------+------------+----------------------+------------------+
如果你要将
p1和p2分区的索引idx的 [0,20000] 范围预切分 2 个 Region,示例语句如下:split partition table t partition (p1,p2) index idx between (0) and (20000) regions 2;
pre_split_regions
使用带有 SHARD_ROW_ID_BITS 的表时,如果希望建表时就均匀切分 Region,可以考虑配合 PRE_SPLIT_REGIONS 一起使用,用来在建表成功后就开始预均匀切分 2^(PRE_SPLIT_REGIONS) 个 Region。
注意:
PRE_SPLIT_REGIONS必须小于等于SHARD_ROW_ID_BITS。
以下全局变量会影响 PRE_SPLIT_REGIONS 的行为,需要特别注意:
tidb_scatter_region:该变量用于控制建表完成后是否等待预切分和打散 Region 完成后再返回结果。如果建表后有大批量写入,需要设置该变量值为1,表示等待所有 Region 都切分和打散完成后再返回结果给客户端。否则未打散完成就进行写入会对写入性能影响有较大的影响。
pre_split_regions 示例
create table t (a int, b int,index idx1(a)) shard_row_id_bits = 4 pre_split_regions=2;
该语句在建表后,会对这个表 t 预切分出 4 + 1 个 Region。4 (2^2) 个 Region 是用来存 table 的行数据的,1 个 Region 是用来存 idx1 索引的数据。
4 个 table Region 的范围区间如下:
region1: [ -inf , 1<<61 )region2: [ 1<<61 , 2<<61 )region3: [ 2<<61 , 3<<61 )region4: [ 3<<61 , +inf )
注意事项
Split Region 语句切分的 Region 会受到 PD 中 Region merge 调度的控制,需要动态修改 Region merge 相关的配置项,避免新切分的 Region 不久后又被 PD 重新合并的情况。
MySQL 兼容性
该语句是 TiDB 对 MySQL 语法的扩展。
另请参阅
[转帖]Split Region 使用文档的更多相关文章
- C# 导出word文档及批量导出word文档(4)
接下来是批量导出word文档和批量打印word文件,批量导出word文档和批量打印word文件的思路差不多,只是批量打印不用打包压缩文件,而是把所有文件合成一个word,然后通过js来调用 ...
- Sharepoint文档的CAML分页及相关筛选记录
写这篇文章的初衷是因为其他的业务系统要调用sharepoint的文档库信息,使其他的系统也可以获取sharepoint文档库的信息列表.在这个过程中尝试过用linq to sharepoint来获取文 ...
- C#word(2007)操作类--新建文档、添加页眉页脚、设置格式、添加文本和超链接、添加图片、表格处理、文档格式转化
转:http://www.cnblogs.com/lantionzy/archive/2009/10/23/1588511.html 1.新建Word文档 #region 新建Word文档/// &l ...
- C# 导出word文档及批量导出word文档(3)
在初始化WordHelper时,要获取模板的相对路径.获取文档的相对路径多个地方要用到,比如批量导出时要先保存文件到指定路径下,再压缩打包下载,所以专门写了个关于获取文档的相对路径的类. #regio ...
- Java 合并、拆分PDF文档
处理PDF文档时,我们可以通过合并的方式,来任意组几个不同的PDF文件或者通过拆分将一个文件分解成多个子文件,这样的好处是对文档的存储.管理很方便.下面将通过Java程序代码介绍具体的PDF合并.拆分 ...
- 【转载】 C#工具类:使用iTextSharp操作PDF文档
iTextSharp是一个用于操作PDF文件的组件DLL程序,在C#程序中可以引用iTextSharp组件,用于开发与PDF文件相关的报表等功能,利用iTextSharp组件提供出来的方法接口,我们可 ...
- XMLHelper类 源码(XML文档帮助类,静态方法,实现对XML文档的创建,及节点和属性的增、删、改、查)
以下是代码: using System; using System.Collections.Generic; using System.Linq; using System.Web; using Sy ...
- ReactiveX/RxJava文档中文版
项目地址:https://github.com/mcxiaoke/RxDocs,欢迎Star和帮忙改进. 有任何意见或建议,到这里提出 Create New Issue 阅读地址 ReactiveX文 ...
- Xcode之外的文档浏览工具--Dash (在iOS代码库中浏览本帖)
链接地址:http://www.cocoachina.com/bbs/read.php?tid=273479 Xcode之外的文档浏览工具--Dash (在iOS代码库中浏览本帖) ...
- C# 在word文档中复制表格并粘帖到下一页中
C# 在word文档中复制表格并粘帖到下一页中 object oMissing = System.Reflection.Missing.Value; Microsoft.Offi ...
随机推荐
- Head First 的学习之道
<Head First 设计模式>是一本好书,正如书的封面上说的那样,这是一本重视大脑的学习指南.里面提到了一些学习方法,可以尝试下,看看哪些对你有用: 1. 慢一点,理解的越多,需要记得 ...
- C++产生N以内的随机整数
C++产生N(这里N=100)以内的随机整数的例子: #include <iostream> #include <ctime> using namespace std; int ...
- C# 在Word中添加Latex 数学公式和符号
本篇内容介绍使用Spire.Doc for .NET在Word中添加Latex数学公式和符号的方法.编辑代码前,将Spire.Doc.dll文件添加引用至VS程序.dll文件包可通过官网下载导入(如果 ...
- 面向对象的Python编程,你需要知道这些!
摘要:Python 没有像 java 中的"private"这样的访问说明符.除了强封装外,它支持大多数与"面向对象"编程语言相关的术语.因此它不是完全面向对象 ...
- 盘点华为云GaussDB(for Redis)六大秒级能力
摘要:盘点高斯Redis的秒级能力,包括扩容.备份.删除.启动等. 本文分享自华为云社区<华为云GaussDB(for Redis)揭秘第20期:六大秒级能力盘点>,作者: 高斯Redis ...
- 论文解读丨Zero-Shot场景下的信息结构化提取
摘要:在信息结构化提取领域,前人一般需要基于人工标注的模板来完成信息结构化提取.论文提出一种zero-shot的基于图卷积网络的解决方案,可以解决训练集和测试集来自不同垂直领域的问题. 本文分享自华为 ...
- vue2升级vue3:vue3 hooks库选用
之前a-hooks:https://ahooks.js.org/,比react-use 精简好用.但是没有vue版本的. 网上有个人实现的:https://github.com/dewfall123/ ...
- UltraEdit 去除文本中的空行,按指定字符换行
在将JSON格式的数据,整理到 Excel中查看时,可以通过文本替换的方式将JSON存到csv 后,使用 UltraEdit 编辑工具按需进行替换处理 去除多个空行 ^p^p 替换成 ^p 按逗号换 ...
- 【docker】运维相关名词 Iaas-Paas和Saas docker镜像设置 启动与停止常用命令 镜像相关命令 容器相关命令
目录 上节回顾 今日内容 1 什么是Iaas-Paas和Saas 2 docker 启动设置镜像 2.1 启动与停止常用命令 3 镜像相关命令 4 容器相关命令 练习 上节回顾 # 1 flask-s ...
- java jar 注册成 windows 服务
1.去github上下载winsw https://github.com/winsw/winsw/releases 2.WinSW.NET4.xml <service> <id> ...